









24-01-23.15:50:18.635 [I/O dispatcher 1] WARN org.elasticsearch.client.RestClient - request [HEAD http://localhost:9200/alarm_msg?ignore_throttled=false&include_type_name=true&ignore_unavailable=false&expand_wildcards=open&allow_no_indices=true] returned 1 warnings: [299 Elasticsearch-7.17.13-2b211dbb8bfdecaf7f5b44d356bdfe54b1050c13 "[ignore_throttled] parameter is deprecated because frozen indices have been deprecated. Consider cold or frozen tiers in place of frozen indices."]
Exception in thread "I/O dispatcher 1" java.lang.AssertionError
at org.elasticsearch.client.Response.assertWarningValue(Response.java:193)
at org.elasticsearch.client.Response.extractWarningValueFromWarningHeader(Response.java:183)
at org.elasticsearch.client.Response.getWarnings(Response.java:205)
at org.elasticsearch.client.RestClient$1.completed(RestClient.java:546)
at org.elasticsearch.client.RestClient$1.completed(RestClient.java:537)
Springboot 执行 ES 单元测试时发生上述异常 , 看提示应该是因为使用了 ignore_throttled 过期参数导致的,但是我的查询并没有使用这个字段,那它是从哪里来的呢?
先 debug 查看异常处代码 Response.assertWarningValue
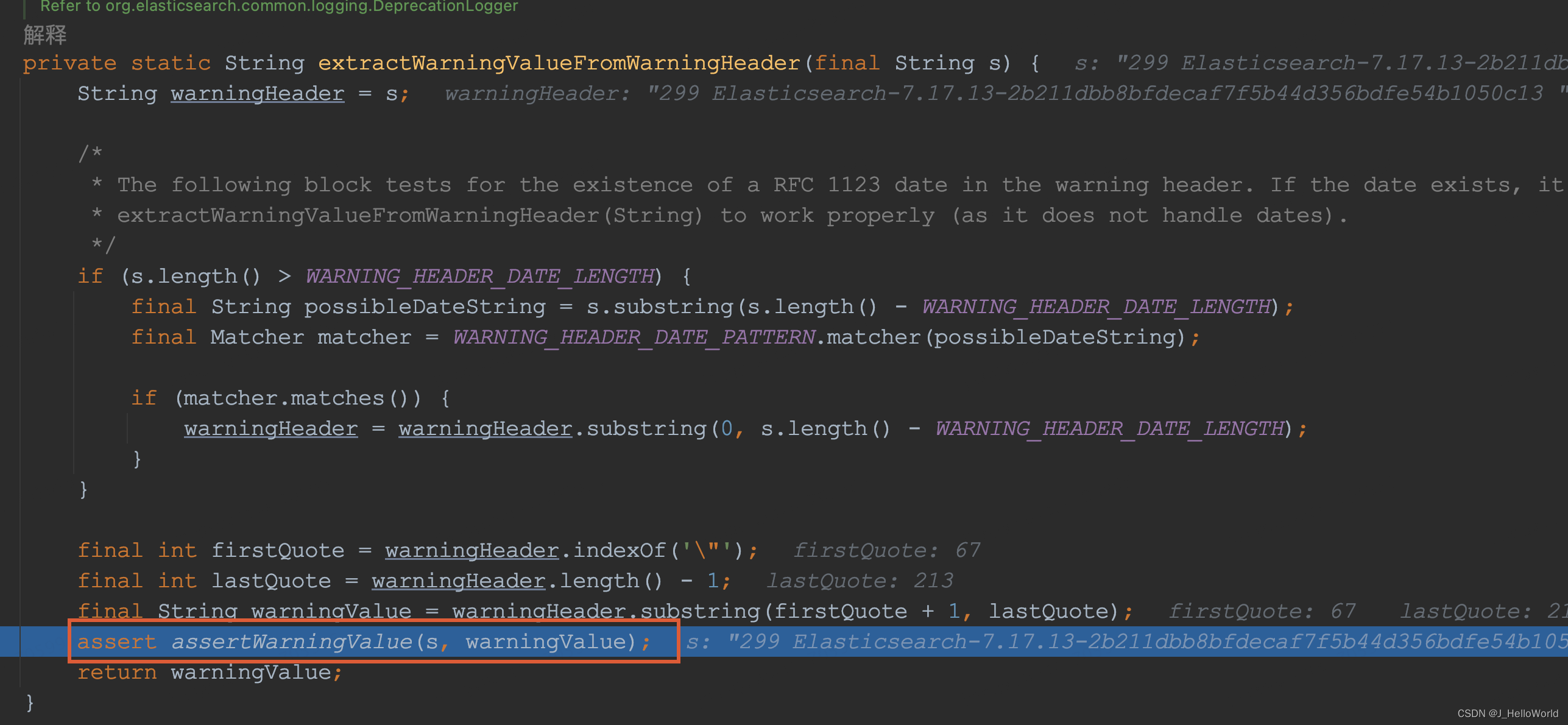
private static final Pattern WARNING_HEADER_PATTERN = Pattern.compile(
"299 " + // warn code
"Elasticsearch-\\d+\\.\\d+\\.\\d+(?:-(?:alpha|beta|rc)\\d+)?(?:-SNAPSHOT)?-(?:[a-f0-9]{7}|Unknown) " + // warn agent
"\"((?:\t| |!|[\\x23-\\x5B]|[\\x5D-\\x7E]|[\\x80-\\xFF]|\\\\|\\\\\")*)\"( " + // quoted warning value, captured
// quoted RFC 1123 date format
"\"" + // opening quote
"(?:Mon|Tue|Wed|Thu|Fri|Sat|Sun), " + // weekday
"\\d{2} " + // 2-digit day
"(?:Jan|Feb|Mar|Apr|May|Jun|Jul|Aug|Sep|Oct|Nov|Dec) " + // month
"\\d{4} " + // 4-digit year
"\\d{2}:\\d{2}:\\d{2} " + // (two-digit hour):(two-digit minute):(two-digit second)
"GMT" + // GMT
"\")?");
private static boolean assertWarningValue(final String s, final String warningValue) {
final Matcher matcher = WARNING_HEADER_PATTERN.matcher(s);
final boolean matches = matcher.matches();
assert matches;
return matcher.group(1).equals(warningValue);
}这段代码是从 es 请求的响应中提取告警信息,判断是否符合断言,该正则表达式分为三部分
1、299 Elasticsearch-xxx...
2、捕获的告警信息
3、时间(可有可无)
对比运行时异常信息发现,299 Elasticsearch-7.17.13-2b211dbb8bfdecaf7f5b44d356bdfe54b1050c13 不在 WARNING_HEADER_PATTERN 约束的版本内,导致匹配失败,分析下我使用的版本信息
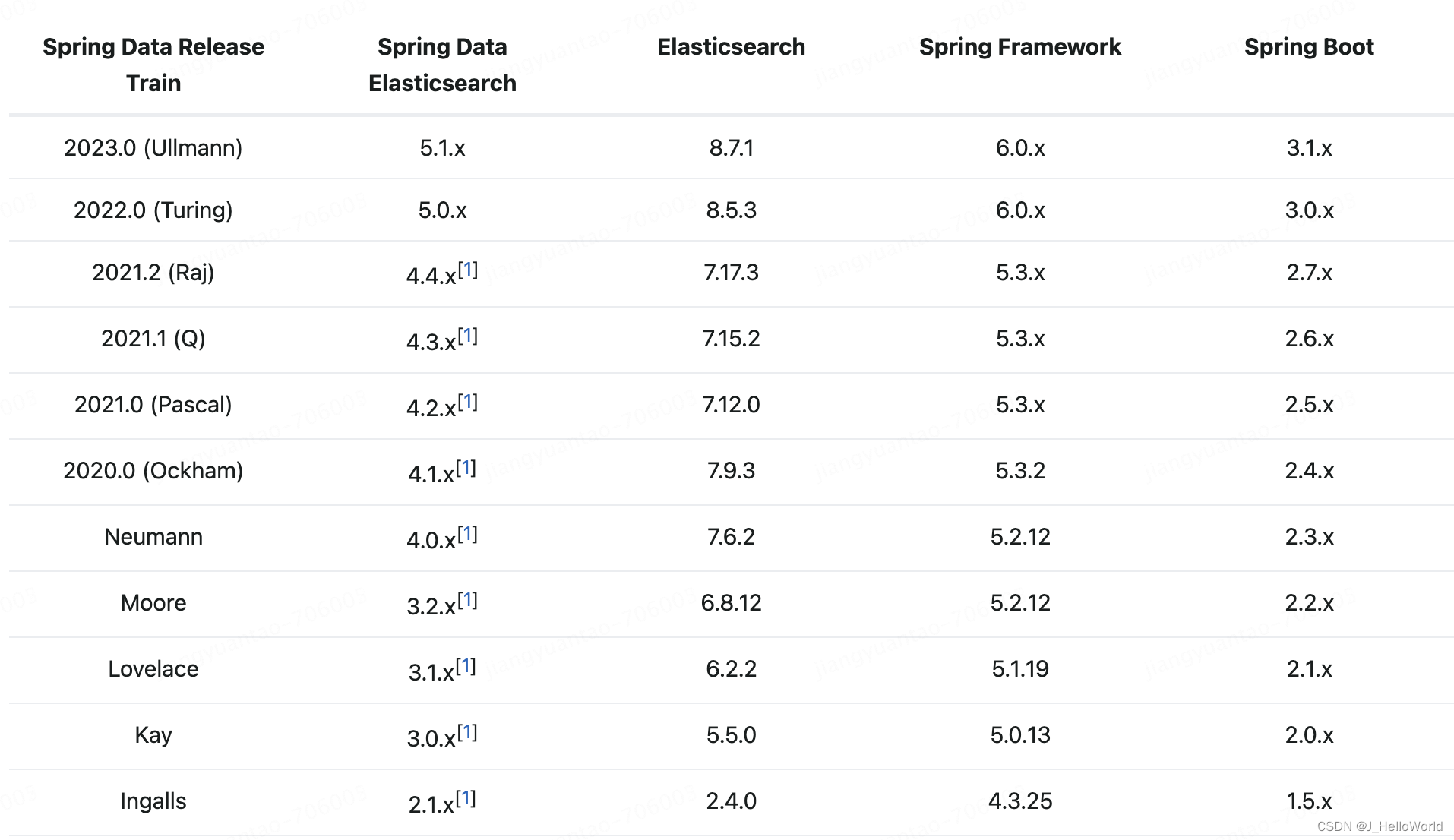
maven 依赖信息 <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-dependencies</artifactId> <version>2.2.6.RELEASE</version> <type>pom</type> <scope>import</scope> </dependency> <dependency> <groupId>org.springframework.data</groupId> <artifactId>spring-data-elasticsearch</artifactId> <version>3.2.6.RELEASE</version> </dependency>- ES 版本 7.17.13
查看官网各版本对应关系:
Spring Data Elasticsearch - Reference Documentation
升级 springboot 版本为 2.7.10
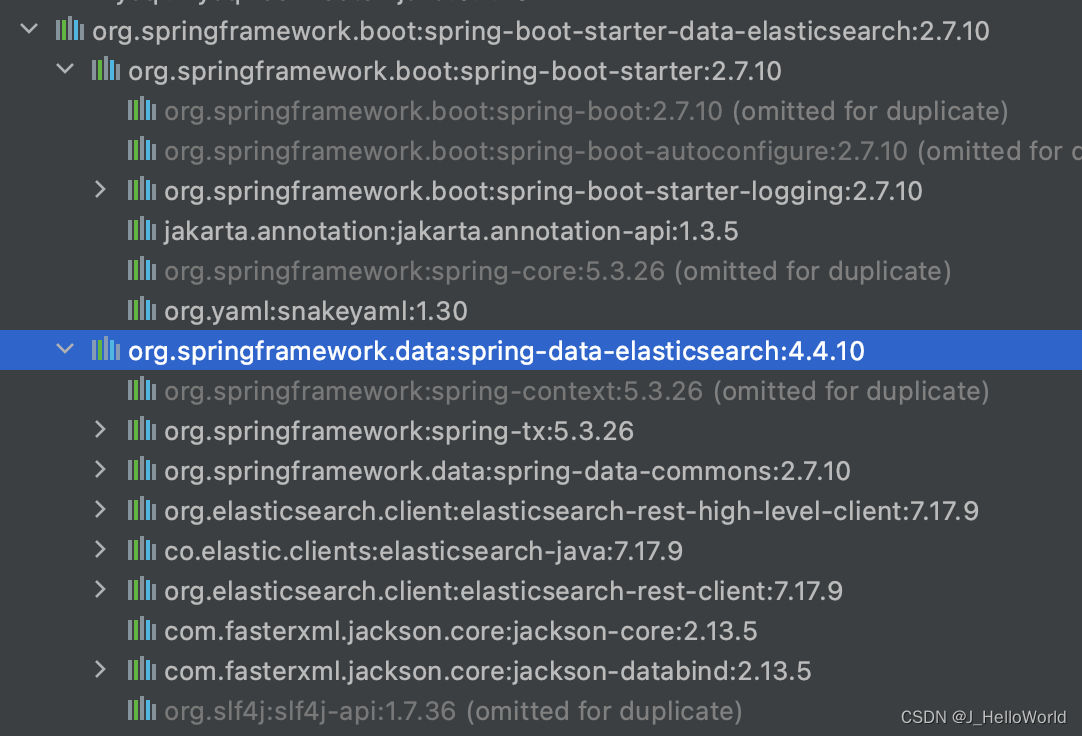
再次执行单元测试通过,没有异常信息,数据正常插入ES
注:[ignore_throttled] parameter is deprecated because frozen indices have been deprecated. Consider cold or frozen tiers in place of frozen indices. 是什么 ?
什么是
ignore_throttled ?
ignore_throttled=true会忽略被限制的分片并继续执行搜索操作,可能导致搜索结果的不完整性(分片受到资源限制或负载高,且无法及时响应搜索请求,这些被限制的分片将会被忽略);而ignore_throttled=false会等待被限制的分片完成操作并返回完整的结果,确保搜索结果的完整性和准确性,但可能会增加搜索请求的响应时间。ignore_throttled参数在版本6.4.0中开始被废弃(deprecated),并且在版本7.0.0中完全移除(removed),建议使用默认值false- 在 7.0 版本中,可以使用 search.allow_partial_results(true/false 用于控制搜索操作是否允许返回部分结果) 替代 ignore_throttled 参数 ignore_throttled
为什么在高版本中不需要
ignore_throttled了?
- 改进索引策略:高版本的Elasticsearch引入了改进的索引策略,其中包括更好的分片管理和负载均衡机制。这些改进使得Elasticsearch能够更好地处理高负载和资源限制的情况,而不需要显式地忽略被限制的分片。
- 自适应限速(Adaptive Throttling):较高版本的Elasticsearch引入了自适应限速机制,它根据系统的负载情况自动调整操作的速度。自适应限速能够更智能地应对资源限制和负载情况,而无需开发人员手动设置忽略被限制的分片。
- 保证结果的完整性:忽略被限制的分片可能会导致搜索结果的不完整性,因为被限制的分片可能包含一部分数据。为了确保搜索结果的准确性和完整性,建议不忽略被限制的分片,而是等待它们完成操作并返回完整的结果。















 879
879











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









