






一、目的:
为了解决分布式集群高可用故障节点任务漂移不均衡的问题,对GBase 8a集群功能进行优化。
二、load任务数均衡
1、目前coordinator会记录自己下发的load任务数,优化后会继续沿用。主要优化的问题一是任务数记录时机不对,下发命令前,实例任务数+1,所有任务全部完成后,实例任务数-1,减去任务数的动作太晚会导致不均衡。二是coordinator选择加载机的算法是从固定顺序的实例中选取前n个实例,并给每个实例下发一个任务,由于选择顺序固定,导致并发加载时,顺序靠前的实例会被分配到更多的任务,致使会出现负载不均衡的问题。
2、主要优化的内容
选择加载机之前,先结合当前记录的任务数与物理机-实例对应关系,优先选择任务数少的物理机,然后在该物理机内部选择任务数少的实例作为加载机;若多个物理机任务数相同,则随机选取物理机;若多个实例任务数相同,则随机选取实例。
3、可以打开gcluster_log_level=7,查看集群层express日志和查看单机层线程等方式观察任务下发情况。
4、以下是每次下发前检查当前coor下发的load任务数
10.10.8.199和10.10.8.190为同一台物理机,因此phy_2和phy_5的任务数相差未超过1。另外,超负载加载时会对所有在线且正常的加载机下发任务。
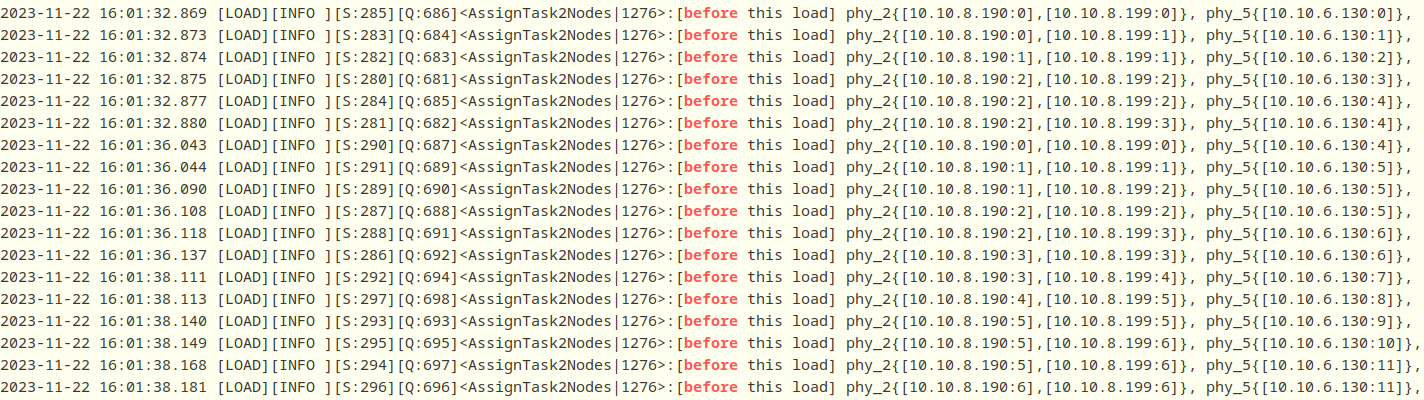
5、以下是下发到具体实例上的任务。
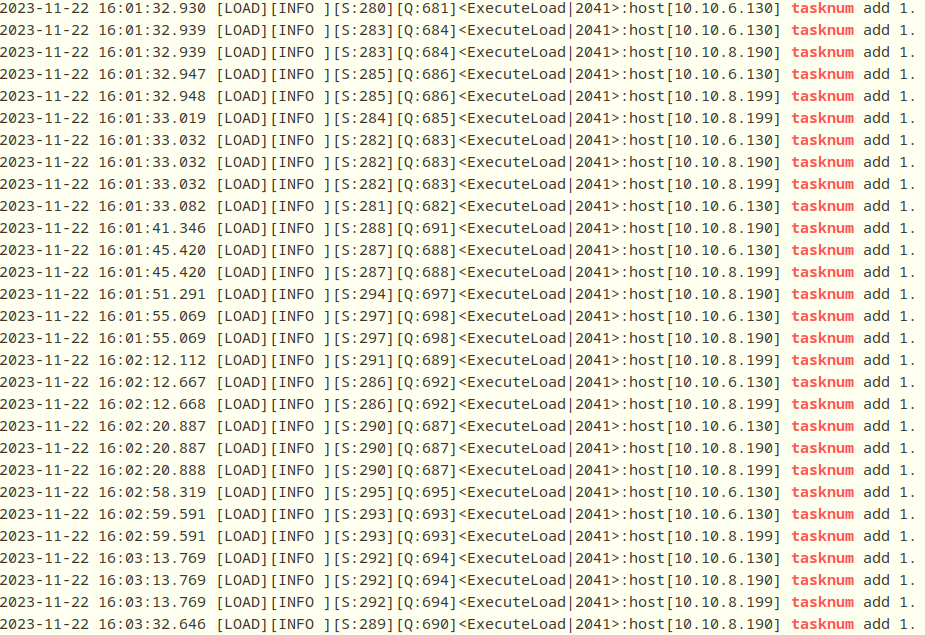
6、显示每个load具体分成了几个任务,每个任务加载行数。

7、查看集群物理机与实例的对应关系
[gbase@lxj-node-6 ~]$ gcadmin getphyinst
| key | /phy-inst |
| crc32 | 2234517161 |
| value | {"phy_1":"10.10.5.77,10.10.5.78","phy_2":"10.10.8.190,10.10.8.199","phy_3":"10.10.7.88,10.10.7.89","phy_4":"10.10.9.19","phy_5":"10.10.6.130"} |















 4634
4634











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









