







说明
假设我们试图在多个模型中为一个学习问题选择一个合适的模型。例如,我们可能使用一个多项式回归模型
hθ(x)=g(θ0+θ1x+θ2x2+...+θkxk)
想要选择K应该等于0,1…还是10呢?我们如何自动地选择一个模型,这个模型可以表示一个好的折衷在偏差和方差之间呢?二者选一的,假设我们想要自动地为局部权重回归选择单宽参数
γ
,,或者为软间隔SVM选择参数C,我们该怎么做呢?
为了具体,我们假设我们有个有限的模型集
M=M1,...,Md
我们将要在这之中选择模型。例如,在我们一开始举的例子中,模型
Mi
代表着第i个多项式回归模型。也就是说,如果我们试图在使用SVM,还是神经网络或者逻辑回归之间选择,
M
可以包含这些模型。下面来选择几种方法。
1 交叉验证
假设我们通常会给定一个训练集
1 在
S
上训练每个模型
2 选择其中训练误差最小的假设。
显然这个误差存在问题。考虑选择多项式的次数。显然,越高次数的多项式,将会更加拟合训练集
S
,因此将会有更低的训练误差。因此,这个方法始终会选择一个高方差,高次数的多项式模型,但是这显然不是一个好的选择,会导致过拟合问题。
这里有一个算法能得到更好的效果,提出交叉验证法(同时也叫简单交叉验证),按照如下步骤:
1. 随机的把
2. 仅使用
Strain
训练每个模型
Mi
,并得到对应的
hi
。
3. 选择和输出假设
hi
,其对应于预留交叉验证集有最小误差
ϵ^Scv(hi)
(
ϵ^Scv(hi)
代表在
Scv
样例上经验误差最小的
h
)
同时,在算法中的步骤3也可能被代替为:根据
这个方法的缺点的是大约要“浪费”大约30%的数据,但是假设我们的数据集个数m=20,这种浪费将是很巨大的,下面针对这种情况介绍一种方法:
这里有一种方法叫做k折交叉验证法,将会预留更少的数据:
1.把
S
随机的分为
2.对于每个模型
Mi
,我们这样评价它:
Forj=1,...,k
在数据集
S1⋃...⋃Sj−1⋃Sj+1⋃...Sk
(也就是训练模型在除了
Sj
外的所有训练集上)并得到对应的假设
hij
。
在
Sj
上测试假设
hij
,得到
ϵ^Sj(hij)
。模型
Mi
的估计泛化误差被计算为
ϵ^Sj(hij)‘s
的平均(关于j平均)。
3.选择模型有最小估计泛化误差的
Mi
,然后在整个训练集上重新训练模型。得到的结果假设就是我们要输出的最终结果。
一个典型的选取方法就是令k=10。但是这种方法可能要比预留交叉验证方法的复杂度要高,因为我们现在需要训练每个模型K次。
如果我们令k=m每次只预留一个训练样例,这种方法叫做预留一个交叉验证法。
上面这些各个版本的交叉验证算法同时也能用来评估一个单一的模型或者算法。
特征选取
一个特殊或者重要的模型选取情况叫做特征选取。假设你现在有一个监督学习问题,它的特征数
n
非常的大(可能n
这种情况下,我们可以使用一个特征选取算法来减少特征值的数目。给定n个特征值,将会有
2n
个可能的特征子集(因为每个特征值可以被包括和不被包括),因此这个问题可以被看做有
2n
个可能的模型的模型选取问题。对于n很大,很难计算比较所有
2n
个模型,下面介绍一种典型的搜索算法叫做前向搜索算法:
1.初始化
F=∅
2.重复{
(a)For i=1,…,n if i
∉F
,让
Fi=F⋃i
然后使用某种交叉验证算法评估特征值
Fi
(也就是说训练你的学习算法仅仅使用特征值
Fi
,然后估计他的误差)
(b)设置
F
为在步骤(a)中最好特征子集。
}
3.选取和输出整个搜索步骤中评价最好的特征子集。
算法外循环的终止条件可以是
F=1,...,n
所有的特征值,或者
|F|
超过某些前置的阈值(对应于你想要算法考虑的使用的最大的特征数)。
这个算法是一种包装模型特征选取的实例化。对应,我们有一种反向搜索算法,初始化
F=1,...,n
为所有的特征集,然后重复的每次删除一个特征(评估单个特征删除用和前向搜索单个特征增加方法相似的方法)直到
F=∅
。这两种算法的复杂度都很高大约为
O(n2)
。
过滤特征选取,算法的计算复杂度较低。核心思想是计算简单的分数
S(i)
用来测量每个特征值
xi
对于标签y的信息量。然后,我们可以简单的选取k个
S(i)
分数最大的特征值。
一个可能定义
S(i)
分数的选择是:定义为
xi
和y的相关度,作为测量训练数据。我们将会导致我们选择和标签具有最大相关度的特征值。实际上,更普遍的是选择
S(i)
为互信息
MI(xi,y)
:
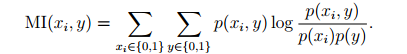
为了增加直观度同样也可以表示为:
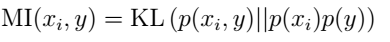
从公式中可以看出如果
xi
和y相互独立那么
MI(xi,y)
将会等于0,相反如果他们很相关将会很大,这与我们的假设是相同的。
那么你已经通过分数对特征值进行了排序?那么应该选取多少个特征k呢?一个标准的方法是使用交叉验证法在几个可能的K值中选取。例如,在朴素贝叶斯文本分类中–词汇量通常会非常大–使用这种方法选取特征值子集通常 会增加分类器的精确度。














 74
74











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









