







BERT4Torch
论文
Pre-training of Deep Bidirectional Transformers for Language Understanding
https://arxiv.org/abs/1810.04805
模型结构
BERT的主模型是BERT中最重要组件,BERT通过预训练(pre-training),具体来说,就是在主模型后再接个专门的模块计算预训练的损失(loss),预训练后就得到了主模型的参数(parameter),当应用到下游任务时,就在主模型后接个跟下游任务配套的模块,然后主模型赋上预训练的参数,下游任务模块随机初始化,然后微调(fine-tuning)就可以了(注意:微调的时候,主模型和下游任务模块两部分的参数一般都要调整,也可以冻结一部分,调整另一部分)。
主模型由三部分构成:嵌入层、编码器、池化层。
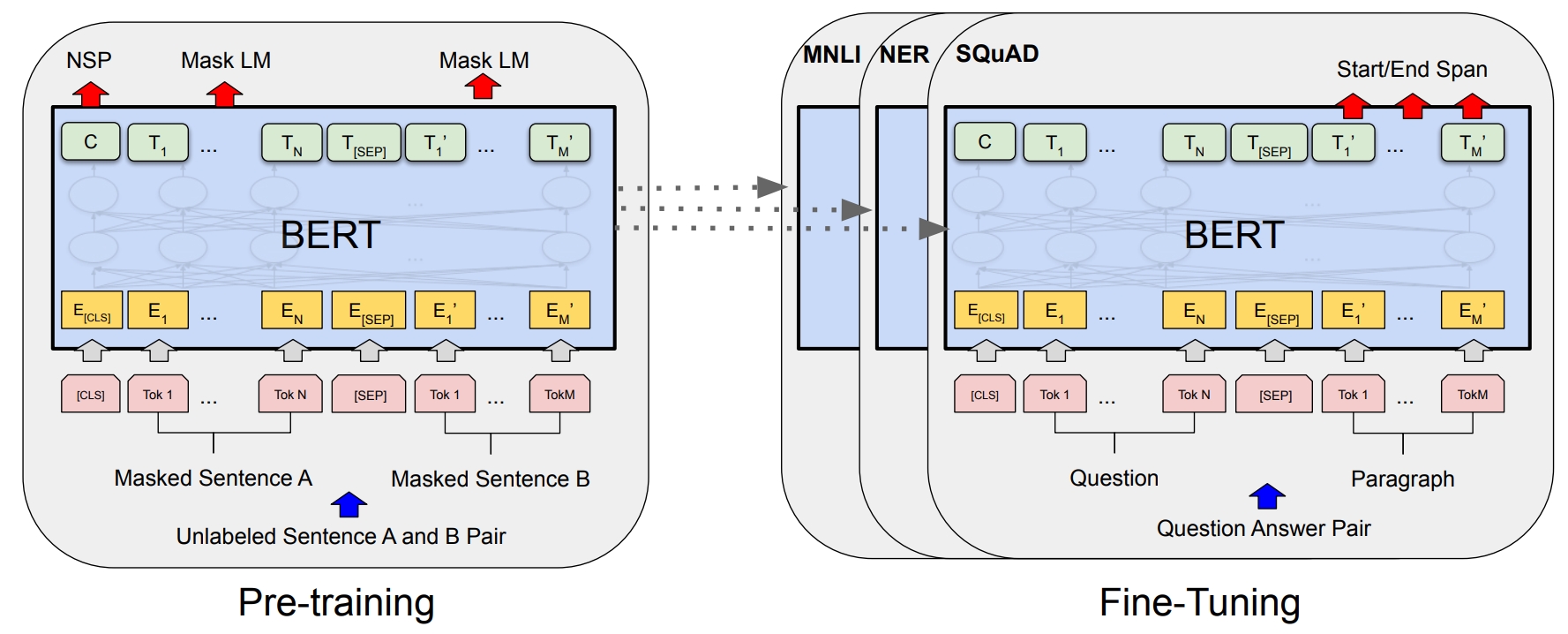
如图:

其中
- 输入:一个个小批(mini-batch),小批里是
batch_size个序列(句子或句子对),每个序列由若干个离散编码向量组成。 - 嵌入层:将输入的序列转换成连续分布式表示(distributed representation),即词嵌入(word embedding)或词向量(word vector)。
- 编码器:对每个序列进行非线性表示。
- 池化层:取出
[CLS]标记(token)的表示(representation)作为整个序列的表示。 - 输出:编码器最后一层输出的表示(序列中每个标记的表示)和池化层输出的表示(序列整体的表示)。
算法原理
BERT模型是基于Transformer模型的,但是与原始的Transformer模型不同,它采用了双向(bidirectional)训练方式,并且通过预训练和微调两个步骤来完成自然语言处理任务。
- 预训练(pre-training):先对大量语料进行无监督学习;
- 微调(Fine-tuning):再对少量标注语料进行监督学习,提升模型针对特定任务的表现能力。
环境配置
Docker(方法一)
在光源可拉取docker镜像:
docker pull image.sourcefind.cn:5000/dcu/admin/base/pytorch:1.13.1-centos7.6-dtk-23.04-py37-latest
创建并启动容器:
docker run -dit --network=host --name=bert4torch --privileged --device=/dev/kfd --device=/dev/dri --ipc=host --shm-size=16G --group-add video --cap-add=SYS_PTRACE --security-opt seccomp=unconfined -u root --ulimit stack=-1:-1 --ulimit memlock=-1:-1 image.sourcefind.cn:5000/dcu/admin/base/pytorch:1.13.1-centos7.6-dtk-23.04-py37-latest
docker exec -it bert4torch /bin/bash
安装依赖包和bert4torch:
pip install -r requirements.txt
cd bert4torch
python3 setup.py install
Dockerfile(方法二)
cd bert4torch/docker
docker build --no-cache -t bert4torch:latest .
docker run --rm --shm-size 16g --network=host --name=bert4torch --privileged --device=/dev/kfd --device=/dev/dri --group-add video --cap-add=SYS_PTRACE --security-opt seccomp=unconfined -v $PWD/../../bert4torch:/home/bert4torch -it bert4torch:latest bash
Anaconda(方法三)
1.创建conda虚拟环境:
conda create -n bert4torch python=3.7
2.关于本项目DCU显卡所需的工具包、深度学习库等均可从光合开发者社区下载安装:https://developer.hpccube.com/tool/
DTK驱动:dtk23.04
python:python3.7
torch:1.13.1
Tips:以上DTK、python、torch等DCU相关工具包,版本需要严格一一对应
3.安装bert4torch
cd bert4torch
python3 setup.py install
4.其它非特殊库参照requirements.txt安装
数据集
数据集下载地址:https://s3.bmio.net/kashgari/china-people-daily-ner-corpus.tar.gz 人民日报数据集存放在目录/datasets/bert-base-chinese目录下,然后解压。
预训练模型下载地址:https://huggingface.co/bert-base-chinese/tree/main 所有文件下载存放在目录/datasets/bert-base-chinese下。
训练数据目录结构如下:
dataset
|
bert-base-chinese
|
china-people-daily-ner-corpus config.json flax_model.msgpack pytorch_model.bin vocab.txt
|
example.dev example.test example.train
训练
修改配置文件
cd examples/sequence_labeling/
# 修改训练脚本配置文件
crf.py # 单卡训练脚本
crf_ddp.py # 多卡训练脚本 多卡训练使用torch的ddp,在单卡训练代码基础上增加DDP的相关内容
仅修改配置文件路径,包括config_path, checkpoint_path, dict_path, train_dataloader, valid_dtaloader,根据需要调整batch_size大小。配置文件修改成argparse参数控制形式,可以在单机单卡启动脚本single_train.sh和多机多卡启动脚本multi_train.sh中对参数进行调整。
单机单卡
cd examples/sequence_labeling/
./single_train.sh
单机多卡
cd examples/sequence_labeling/
./multi_train.sh
result

精度
| 卡数 | 类型 | batch_size | f1 | p | r |
|---|---|---|---|---|---|
| 1 | fp32 | 64 | 0.9592 | 0.9643 | 0.9617 |
| 1 | fp16 | 64 | 0.9559 | 0.9596 | 0.9545 |
| 4 | fp32 | 256 | 0.9459 | 0.9398 | 0.9521 |
| 4 | fp16 | 256 | 0.9438 | 0.9398 | 0.9505 |
应用场景
算法类别
对话问答
热点应用行业
医疗,教育,科研,金融

















 940
940

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











