







目录
2.3. 在 Virtual Machine Manager 中监视性能
2.3.1. 在 Virtual Machine Manager 中查看性能概览
四、调优和调优管理(TUNED AND TUNED-ADM)
6.1. 使用 Red Hat Enterprise Linux 作为虚拟化主机进行 I/O 调度
6.2. 使用 Red Hat Enterprise Linux 作为虚拟化虚拟机进行 I/O 调度
8.2.3.3. 在引导或运行时为 虚拟机 启用 1 GB 的大页面
9.4. NUMA 感知内核 SamePage 合并 (KSM)
一、引言
1.1 为什么性能优化在虚拟化中很重要
在 KVM 虚拟化中,虚拟机由宿主机上的进程表示。这意味着主宿机的处理能力、内存和其他资源用于模拟虚拟机虚拟硬件的功能和能力。
但是,虚拟机硬件在使用资源方面的效率可能不如宿主机。因此,可能需要调整分配的宿主机资源量,以便虚拟机以预期的速度执行其任务。此外,各种类型的虚拟硬件可能具有不同级别的开销,因此适当的虚拟硬件配置可能会对虚拟机性能产生重大影响。最后,根据具体情况,特定配置使虚拟机能够更有效地使用宿主机资源。
1.2 KVM性能架构概述
以下几点简要概述了 KVM,因为它与系统性能以及进程和线程管理有关:
-
使用 KVM 时,虚拟机在主机上作为 Linux 进程运行。
-
虚拟 CPU (vCPU) 作为普通线程实现,由 Linux 调度程序处理。
-
虚拟机不会自动从内核继承 NUMA 和大页面等功能。
-
主机中的磁盘和网络 I/O 设置对性能有重大影响。
-
网络流量通常通过基于软件的网桥传输。
-
根据设备及其型号的不同,由于仿真该特定硬件,可能会产生大量开销。
1.3 KVM虚拟化性能特性和改进
Red Hat Enterprise Linux 7 中的虚拟化性能改进
以下功能提高了 Red Hat Enterprise Linux 7 中的虚拟化性能:
- 自动 NUMA 平衡(Automatic NUMA Balancing)
自动 NUMA 均衡可提高在 NUMA 硬件系统上运行的应用程序的性能,无需对 Red Hat Enterprise Linux 7 虚拟机进行任何手动调优。自动 NUMA 平衡将任务(可以是线程或进程)移动到它们正在访问的内存附近。这样可以在零配置的情况下实现良好的性能。但是,在某些情况下,提供更准确的虚拟机配置或设置虚拟机到主机的 CPU 和内存关联可能会提供更好的结果。
有关自动 NUMA 平衡的更多信息,请参见第 9.2 节 “自动 NUMA 平衡”。
- VirtIO 模型(VirtIO models)
任何具有 virtio 模型的虚拟硬件都不会产生模拟硬件及其所有特殊性的开销。VirtIO 设备具有低开销,这要归功于它们专为在虚拟化环境中使用而设计。但是,并非所有虚拟机操作系统都支持此类模型。
- 多队列 virtio-net(Multi-queue virtio-net)
一种网络方法,使数据包发送/接收处理能够随着客户机的可用 vCPU 数量而扩展。
有关多队列 virtio-net 的更多信息,请参见第 5.4.2 节 “多队列 virtio-net”。
- 桥接零复制传输(Bridge Zero Copy Transmit)
零拷贝传输模式可在访客网络和外部网络之间传输大数据包时将主机 CPU 开销降低多达 15%,而不会影响吞吐量。Red Hat Enterprise Linux 7 虚拟机完全支持桥接零副本传输,但默认情况下是禁用的。
有关零复制传输的更多信息,请参见第 5.4.1 节 “桥接零复制传输”。
- APIC 虚拟化 (APICv)
较新的 Intel 处理器提供高级可编程中断控制器 (APICv) 的硬件虚拟化。APICv 允许虚拟机直接访问 APIC,从而提高了虚拟化 AMD64 和 Intel 64 虚拟机的性能,从而大大减少了 APIC 导致的中断延迟和虚拟机退出次数。默认情况下,此功能在较新的 Intel 处理器中使用,可提高 I/O 性能。
- EOI加速 (EOI Acceleration)
在没有虚拟 APIC 功能的旧芯片组上实现高带宽 I/O 的中断结束加速。
- 多队列 virtio-scsi
通过 virtio-scsi 驱动程序中的多队列支持提高了存储性能和可扩展性。这使每个虚拟 CPU 都可以使用单独的队列和中断,而不会影响其他 vCPU。
有关多队列 virtio-scsi 的更多信息,请参见第 7.4.2 节 “多队列 virtio-scsi”。
- 半虚拟化票据锁(Paravirtualized Ticketlocks)
半虚拟化票据锁 (pvticketlocks) 可提高在 CPU 超额订阅的 Red Hat Enterprise Linux 7 主机上运行的 Red Hat Enterprise Linux 7 虚拟机的性能。
- 半虚拟化页面错误(Paravirtualized Page Faults)
当虚拟机尝试访问被主机交换的页面时,半虚拟化页面错误会注入到虚拟机中。当主机内存过量使用且虚拟机内存被换出时,这可以提高 KVM 虚拟机性能。
- 半虚拟化时间
与调用优化
gettimeofday和
clock_gettime系统调用通过
vsyscall机制在用户空间中执行。以前,发出这些系统调用需要系统切换到内核模式,然后再返回到用户空间。这大大提高了某些应用程序的性能。
Red Hat Enterprise Linux 中的虚拟化性能特性
-
CPU/内核
-
NUMA - 非一致性内存访问。有关 NUMA 的详细信息,请参见第 9 章 “NUMA”。
-
CFS - 完全公平的调度器。一个以班级为中心的现代调度程序。
-
RCU - 读取、复制、更新。更好地处理共享线程数据。
-
多达 160 个虚拟 CPU (vCPU)。
-
-
Memory
-
针对内存密集型环境的大页面和其他优化。有关详细信息,请参见第 8 章 “内存”。
-
-
Networking
-
vhost-net - 一种快速、基于内核的 VirtIO 解决方案。
-
SR-IOV - 用于接近本机的网络性能级别。
-
-
块 I/O Block I/O
-
AIO - 支持线程与其他 I/O 操作重叠。
-
MSI - PCI 总线设备中断生成。
-
磁盘 I/O 限制 - 控制虚拟机磁盘 I/O 请求,以防止过度利用主机资源。有关详细信息,请参见第 7.4.1 节 “磁盘 I/O 限制”。
-
注意
有关虚拟化支持、限制和功能的更多详细信息,请参阅《Red Hat Enterprise Linux 7 虚拟化入门指南》和以下 URL:
Virtualization limits for Red Hat Enterprise Linux with KVM - Red Hat Customer Portal
二、性能监控工具
本章介绍用于监视虚拟机环境的工具。
2.1 KVM性能
您可以使用perf带有kvm选项的命令来收集和分析来自主机的虚拟机操作系统统计信息。perf 包提供了perf命令。通过运行以下命令进行安装:
# yum install perf为了在主机中使用perf kvm,您必须具有从 虚拟机访问/proc/modules 和 /proc/kallsyms文件的权限。请参见过程 2.1 “将 /proc 文件从虚拟机过程 2.1 “将 /proc 文件从,以将文件传输到主机并运行有关文件的报告。
将 /proc 文件从虚拟机复制到主机
重要
如果您直接复制所需的文件(例如,使用scp),则只会复制长度为零的文件。此过程介绍如何首先将虚拟机中的文件保存到临时位置(使用cat命令),然后将它们复制到主机以供perf kvm使用。
1、登录到虚拟机并保存文件
/proc/modules和
/proc/kallsyms
到
/tmp
位置,:
cat /proc/modules > /tmp/modules
cat /proc/kallsyms > /tmp/kallsyms2、将临时文件复制到主机
scp示例命令以将保存的文件复制到主机。如果主机名和 TCP 端口不同,则应替换它们:
scp root@GuestMachine:/tmp/kallsyms guest-kallsyms
scp root@GuestMachine:/tmp/modules guest-modulesguest-kallsyms和
guest-modules ) 的两个文件,可供
perf kvm使用。
3、使用 perf kvm 记录和报告事件
# perf kvm --host --guest --guestkallsyms=guest-kallsyms \
--guestmodules=guest-modules record -a -o perf.data注意
如果命令中同时使用了 --host 和 --guest,则输出将存储在perf.data.kvm中。如果仅使用 --host,则文件将被命名为perf.data.host。同样,如果仅使用 --guest,则文件将被命名为perf.data.guest。
按 Ctrl-C 停止记录。
4、报告事件
analyze
perf kvm --host --guest --guestmodules=guest-modules report -i perf.data.kvm \
--force > analyze查看analyze文件的内容以检查记录的事件:
# cat analyze
# Events: 7K cycles
#
# Overhead Command Shared Object Symbol
# ........ ............ ................. .........................
#
95.06% vi vi [.] 0x48287
0.61% init [kernel.kallsyms] [k] intel_idle
0.36% vi libc-2.12.so [.] _wordcopy_fwd_aligned
0.32% vi libc-2.12.so [.] __strlen_sse42
0.14% swapper [kernel.kallsyms] [k] intel_idle
0.13% init [kernel.kallsyms] [k] uhci_irq
0.11% perf [kernel.kallsyms] [k] generic_exec_single
0.11% init [kernel.kallsyms] [k] tg_shares_up
0.10% qemu-kvm [kernel.kallsyms] [k] tg_shares_up
[output truncated...]2.2 虚拟性能监控单元(vPMU)
arch_perfmon标志:
# cat /proc/cpuinfo|grep arch_perfmon 要启用 vPMU,请在虚拟机 XML 中将 cpu 模式指定为host-passthrough:
# virsh dumpxml guest_name |grep "cpu mode"
<cpu mode='host-passthrough'> 启用 vPMU 后,通过从虚拟机运行perf命令来显示虚拟机的性能统计信息。
2.3. 在 Virtual Machine Manager 中监视性能
2.3.1. 在 Virtual Machine Manager 中查看性能概览
-
在 Virtual Machine Manager 主窗口中,突出显示要查看的虚拟机。

图 2.1.选择要显示的虚拟机
-
从 Virtual Machine Manager 的“编辑”菜单中,选择“虚拟机详细信息”。当“虚拟机详细信息”窗口打开时,可能会显示一个控制台。如果发生这种情况,请单击“查看”,然后选择“详细信息”。默认情况下,“概述”窗口首先打开。
-
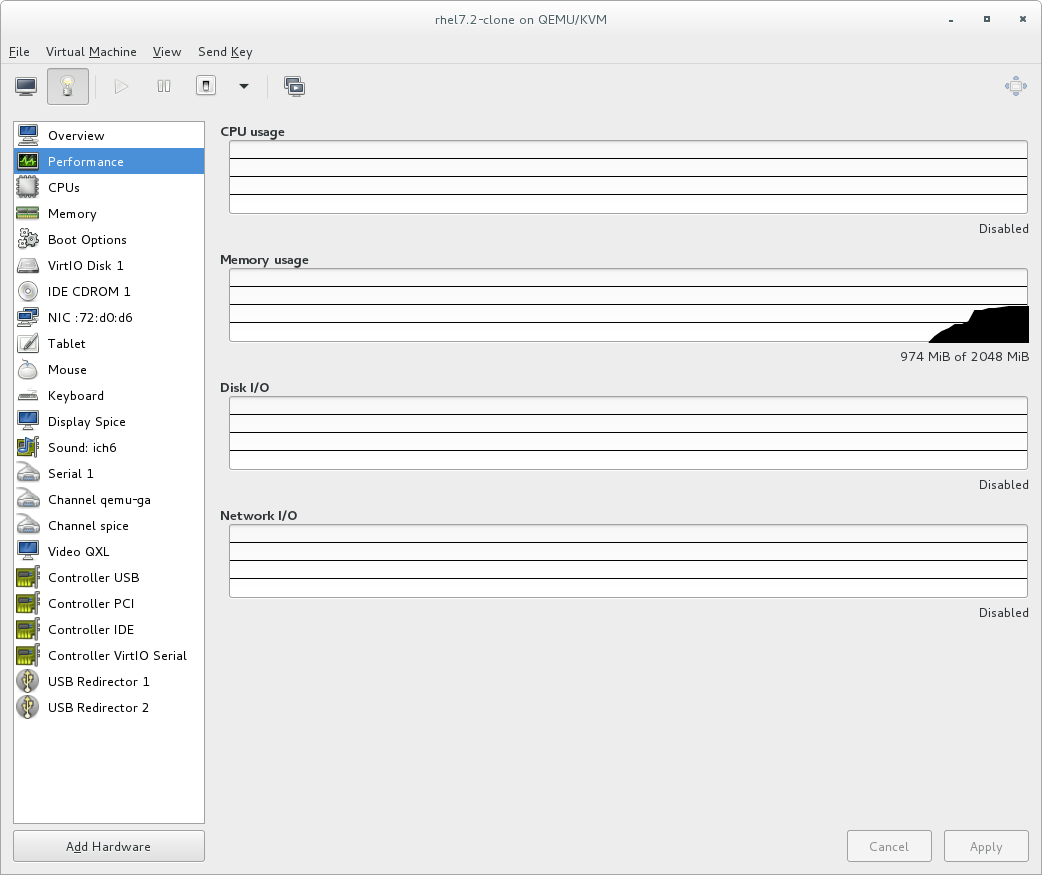
从左侧的导航窗格中选择“性能”。“性能”视图显示虚拟机 性能的摘要,包括 CPU 和内存使用情况以及磁盘和网络输入和输出。

图 2.2.显示虚拟机表演详细信息
2.3.2. 性能监控
virt-manager
-
从“编辑”菜单中,选择“首选项”。此时将显示“首选项”窗口。
-
在“轮询”选项卡中,指定时间(以秒为单位)或统计轮询选项。

图 2.3.配置性能监视

2.3.3. 显示虚拟机的 CPU 使用率
-
从“视图”菜单中,选择“图形”,然后选择“虚拟机 CPU 使用情况”复选框。
-
Virtual Machine Manager 显示系统上所有虚拟机的 CPU 使用情况图。

图 2.4.虚拟机 CPU 使用率图

2.3.4. 显示主机的 CPU 使用率
-
从“视图”菜单中,选择“图形”,然后选择“主机 CPU 使用率”复选框。
-
Virtual Machine Manager 显示系统上主机 CPU 使用情况的图形。

图 2.5.主机 CPU 使用率图
2.3.5. 显示磁盘 I/O
-
确保已启用磁盘 I/O 统计信息收集。为此,请从“编辑”菜单中选择“首选项”,然后单击“轮询”选项卡。
-
选中“磁盘 I/O”复选框。

图 2.6.启用磁盘 I/O
-
要启用磁盘 I/O 显示,请从“视图”菜单中选择“图形”,然后选择“磁盘 I/O”复选框。
-
Virtual Machine Manager 显示系统上所有虚拟机的磁盘 I/O 图。

图 2.7.显示磁盘 I/O

2.3.6. 显示网络 I/O
-
确保已启用网络 I/O 统计信息收集。为此,请从“编辑”菜单中选择“首选项”,然后单击“轮询”选项卡。
-
选中“网络 I/O”复选框。

图 2.8.启用网络 I/O
-
要显示网络 I/O 统计信息,请从“视图”菜单中选择“图形”,然后选择“网络 I/O”复选框。
-
Virtual Machine Manager 显示系统上所有虚拟机的网络 I/O 图。

图 2.9.显示网络 I/O
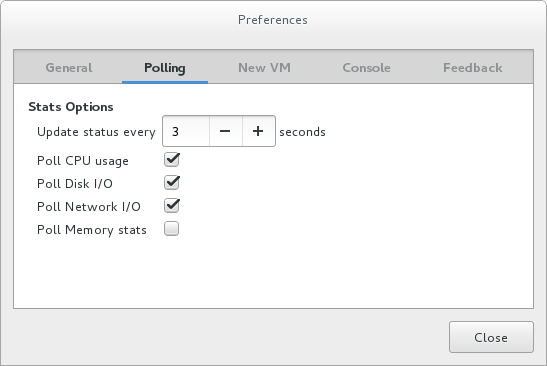

2.3.7. 显示内存使用情况
-
请确保已启用内存使用率统计信息收集。为此,请从“编辑”菜单中选择“首选项”,然后单击“轮询”选项卡。
-
选中 Poll Memory stats 复选框。

图 2.10.启用内存使用情况
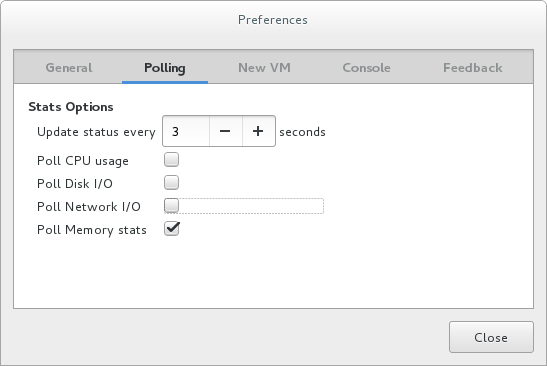
-
要显示内存使用情况,请从“视图”菜单中选择“图形”,然后选择“内存使用情况”复选框。
-
Virtual Machine Manager 列出了系统上所有虚拟机的内存使用百分比(以 MB 为单位)。


三、使用 virt-manager 优化虚拟化性能
3.1. 操作系统详细信息和设备
3.1.1. 指定虚拟机虚拟机详细信息
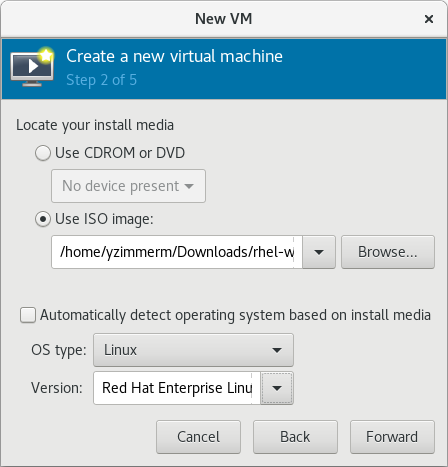
图 3.1.提供操作系统类型和版本
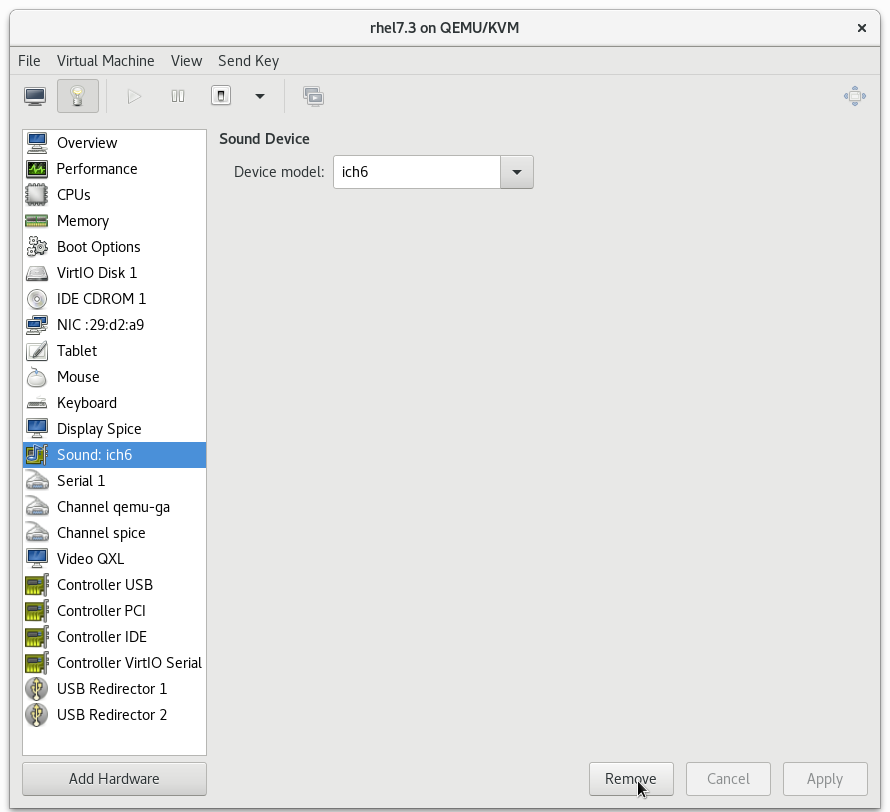
3.1.2. 删除未使用的设备
3.2. CPU 性能选项
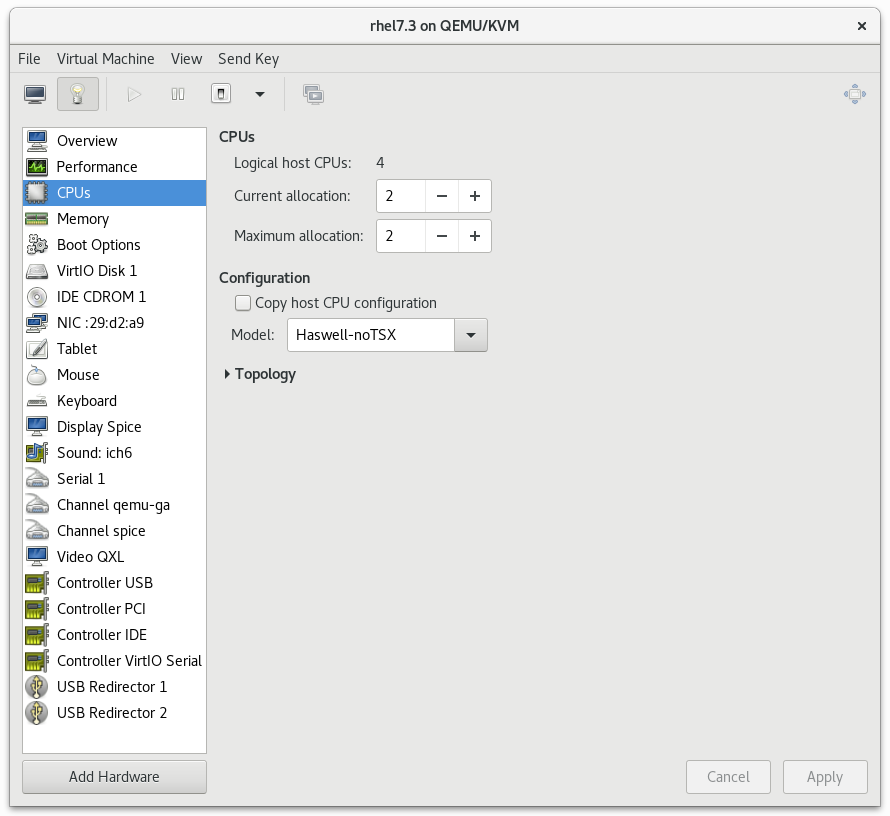
图 3.3.CPU 性能选项
3.2.1. 选项:可用的 CPU

图 3.4.CPU 过量分配
重要
3.2.2. 选项:CPU配置
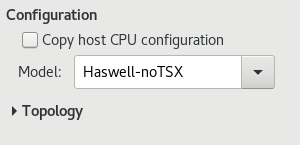
图 3.5.CPU 配置选项
注意
注意
virsh capabilities
3.2.3. 选项:CPU拓扑
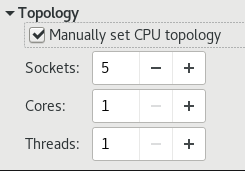
图 3.6.CPU 拓扑选项
注意
3.3. 虚拟磁盘性能选项

图 3.7.虚拟磁盘性能选项
重要
在 virt-manager 中设置虚拟磁盘性能选项时,必须重新启动虚拟机才能使设置生效。
四、调优和调优管理(TUNED AND TUNED-ADM)
virtual-guest
吞吐量-性能配置文件,virtual-guest 还会降低虚拟内存的交换性。
虚拟虚拟机
配置文件。这是虚拟机的推荐配置文件。
virtual-host
吞吐量-性能配置文件,virtual-host 还支持对脏页进行更积极的写回。此配置文件是虚拟化主机(包括 KVM 和 Red Hat 虚拟化 (RHV) 主机)的推荐配置文件。
tuned
<span style="color:#151515"><code># tuned-adm list</code>
Available profiles:
- balanced
- desktop
- latency-performance
- network-latency
- network-throughput
- powersave
- sap
- throughput-performance
- virtual-guest
- virtual-host
Current active profile: throughput-performance</span>tuned.conf
<span style="color:#151515"><code>tuned-adm active</code></span><span style="color:#151515"><code>tuned-adm profile <em>profile_name</em></code></span>virtual-host
<span style="color:#151515"><code>tuned-adm profile virtual-host</code></span>重要
<span style="color:#151515"># <code>systemctl enable tuned</code></span><span style="color:#151515"># <code>tuned-adm off</code></span><span style="color:#151515"># <code>tuned-adm off; systemctl disable tuned</code></span>注意
五、网络
本章介绍虚拟化环境的网络优化主题。
5.1. 网络调优技巧
使用多个网络以避免单一网络上的拥堵。例如,可以为管理、备份或实时迁移设置专用网络。
红帽公司建议不要在同一个网络段中使用多个接口。然而,如果无法避免,可以使用 arp_filter 来防止 ARP 频繁变更(ARP Flux),这种不良情况可能在主机和客机中都发生,是由于机器对来自多个网络接口的 ARP 请求作出响应所导致的:可以通过执行 echo 1 > /proc/sys/net/ipv4/conf/all/arp_filter 或编辑 /etc/sysctl.conf 来使此设置持久化。
注意
有关 ARP Flux 的更多信息,请参阅 2.1. Address Resolution Protocol (ARP)
5.2. Virtio 和 vhost_net
下图演示了内核在 Virtio 和 vhost_net 架构中的参与。

图 5.1.Virtio 和 vhost_net 架构
vhost_net将 Virtio 驱动程序的一部分从用户空间移动到内核中。这样可以减少复制操作,降低延迟和 CPU 使用率。
5.3. 设备分配和 SR-IOV
下图演示了内核在设备分配和 SR-IOV 体系结构中的参与。

图 5.2.设备分配和 SR-IOV
设备分配将整个设备呈现给来宾。SR-IOV 需要驱动程序和硬件(包括 NIC 和系统板)方面的支持,并允许创建多个虚拟设备并将其传递给不同的虚拟机。虚拟机中需要特定于供应商的驱动程序,但是,SR-IOV 提供任何网络选项中最低的延迟。
5.4. 网络调优技术
本节介绍在虚拟化环境中调整网络性能的技术。
重要
Red Hat Enterprise Linux 7 虚拟机管理程序和虚拟机支持以下功能,但也在运行 Red Hat Enterprise Linux 6.6 及更高版本的虚拟机上受支持。
5.4.1. 桥接零复制传输
零拷贝传输模式对大数据包有效。在来宾网络和外部网络之间传输大数据包时,它通常会将主机 CPU 开销降低多达 15%,而不会影响吞吐量。
它不会影响虚拟机到虚拟机、虚拟机到主机或小数据包工作负载的性能。
Red Hat Enterprise Linux 7 虚拟机完全支持桥接零副本传输,但默认情况下是禁用的。要启用零拷贝传输模式,请将vhost_net模块的 experimental_zcopytx 内核模块参数设置为 1。有关详细说明,请参阅《虚拟化部署和管理指南》。
注意
通常在传输过程中创建额外的数据副本,作为针对拒绝服务和信息泄露攻击的威胁缓解技术。启用零拷贝传输将禁用此威胁缓解技术。
如果观察到性能回归,或者如果主机 CPU 利用率不是问题,则可以通过将 experimental_zcopytx 设置为 0 来禁用零拷贝传输模式。
5.4.2. 多队列virtio-net
多队列 virtio-net 提供了一种随着 vCPU 数量的增加而扩展网络性能的方法,允许它们一次通过多个 virtqueue 对传输数据包。
如今的高端服务器拥有更多的处理器,在其上运行的虚拟机通常拥有越来越多的 vCPU。在单队列 virtio-net 中,虚拟机中协议栈的规模受到限制,因为网络性能不会随着 vCPU 数量的增加而扩展。虚拟机不能并行传输或检索数据包,因为 virtio-net 只有一个 TX 和 RX 队列。
多队列支持通过允许并行数据包处理来消除这些瓶颈。
在以下情况下,多队列virtio-net可提供最大的性能优势:
- 流量数据包相对较大。
- 访客同时在多个连接上处于活动状态,流量在访客之间、访客到主机之间或访客到外部系统之间运行。
- 队列数等于 vCPU 数。这是因为多队列支持优化了 RX 中断亲和性和 TX 队列选择,以便使特定队列对特定 vCPU 私有。
注意
目前,设置多队列 virtio-net 连接可能会对传出流量的性能产生负面影响。具体来说,当通过传输控制协议 (TCP) 流发送小于 1,500 字节的数据包时,可能会发生这种情况。有关更多信息,请参阅 Red Hat 知识库。
5.4.2.1. 配置多队列virtio-net
要使用多队列 virtio-net,请通过在虚拟机 XML 配置中添加以下内容来启用虚拟机中的支持(其中 N 的值介于 1 到 256 之间,因为内核支持多达 256 个多队列分路设备的队列):
<interface type='network'>
<source network='default'/>
<model type='virtio'/>
<driver name='vhost' queues='N'/>
</interface>在虚拟机中运行具有 N 个 virtio-net 队列的虚拟机时,请使用以下命令启用多队列支持(其中 M 的值为 1 到 N):
# ethtool -L eth0 combined M5.5. 批处理网络数据包
在传输路径较长的配置中,在将数据包提交到内核之前对数据包进行批处理可能会提高缓存利用率。
要配置可以批处理的最大数据包数,其中 N 是要批处理的最大数据包数:
# ethtool -C $tap rx-frames N要为 type='bridge' 或 type='network' 接口提供对 / rx 批处理的支持,请向域 XML 文件添加类似于以下内容的代码段。
...
<devices>
<interface type='network'>
<source network='default'/>
<target dev='vnet0'/>
<coalesce>
<rx>
<frames max='7'/>
</rx>
</coalesce>
</interface>
</devices>六、I/O 调度
当 Red Hat Enterprise Linux 7 是虚拟化主机时,您可以使用输入/输出 (I/O) 调度器来提高磁盘性能,也可以使用它是虚拟化客户机。
6.1. 使用 Red Hat Enterprise Linux 作为虚拟化主机进行 I/O 调度
在使用 Red Hat Enterprise Linux 7 作为虚拟化虚拟机的主机时,默认的截止时间(deadline)调度器通常是理想选择。该调度器在几乎所有工作负载上表现良好。然而,如果在客户工作负载中,最大化 I/O 吞吐量比最小化 I/O 延迟更为重要,使用 cfq 调度器可能会更有益。
6.2. 使用 Red Hat Enterprise Linux 作为虚拟化虚拟机进行 I/O 调度
无论虚拟机运行在哪种虚拟机监控器上,您都可以在 Red Hat Enterprise Linux 客户虚拟机上使用 I/O 调度。以下是需要考虑的好处和问题列表:
- Red Hat Enterprise Linux 客户通常从使用 noop 调度器中获得很大收益。该调度器将来自客户操作系统的小请求合并为较大的请求,然后再将 I/O 发送到虚拟机监控器。这允许虚拟机监控器更高效地处理 I/O 请求,从而显著提升客户的 I/O 性能。
- 根据工作负载的 I/O 特性以及存储设备的连接方式,像截止时间调度器(deadline)这样的调度器可能比 noop 更有益。红帽公司建议进行性能测试,以验证哪个调度器能够提供最佳的性能影响。
- 使用 iSCSI、SR-IOV 或物理设备直通访问的存储的虚拟机不应使用 noop 调度器。这些方法不允许主机优化对底层物理设备的 I/O 请求。
注意
在虚拟化环境中,有时在主机层和虚拟机层上安排 I/O 是没有好处的。如果多个虚拟机使用由主机操作系统管理的文件系统或块设备上的存储,则主机可能能够更有效地安排 I/O,因为它知道来自所有虚拟机的请求。此外,主机知道存储的物理布局,而该布局可能不会线性映射到来宾的虚拟存储。
所有调度程序调优都应在正常运行条件下进行测试,因为综合基准测试通常无法准确比较在虚拟环境中使用共享资源的系统的性能。
Red Hat Enterprise Linux 7 系统上使用的deadline默认调度程序是 。但是,在 Red Hat Enterprise Linux 7 虚拟机上,通过执行以下操作将调度器更改为 noop可能会有所帮助:
所有调度程序调优都应在正常运行条件下进行测试,因为综合基准测试通常无法准确比较在虚拟环境中使用共享资源的系统的性能。
Red Hat Enterprise Linux 7 系统上使用的deadline默认调度程序是 。但是,在 Red Hat Enterprise Linux 7 虚拟机上,通过执行以下操作将调度器更改为noop 可能会有所帮助:
- 在 /etc/default/grub 文件中,将 GRUB_CMDLINE_LINUX 行中的 elevator=deadline 字符串更改为 elevator=noop。如果没有 elevator= 字符串,请在行末添加 elevator=noop。
以下是成功更改后 /etc/default/grub 文件的示例:
# cat /etc/default/grub
[...]
GRUB_CMDLINE_LINUX="crashkernel=auto rd.lvm.lv=vg00/lvroot rhgb quiet elevator=noop"
[...]- 重新生成/boot/grub2/grub.cfg文件。
- 在基于 BIOS 的计算机上:
# grub2-mkconfig -o /boot/grub2/grub.cfg- 在基于 UEFI 的计算机上:
# grub2-mkconfig -o /boot/efi/EFI/redhat/grub.cfg七、块 I/O(BLOCK I/O)
本章介绍如何优化虚拟化环境中的 I/O 设置。
7.1. 块I/O调优
virsh blkiotune命令允许管理员在虚拟机XML 配置的元素中手动设置或显示虚拟机的块 I/O 参数。
要显示虚拟机的当前参数,请执行以下操作:
# virsh blkiotune virtual_machine要设置虚拟机的参数,请根据您的环境使用virsh blkiotune命令并替换选项值:
# virsh blkiotune virtual_machine [--weight number] [--device-weights string] [--config] [--live] [--current]参数包括:
weight
I/O 权重,在 100 到 1000 范围内。增加设备的 I/O 权重会增加其 I/O 带宽的优先级,从而为其提供更多的主机资源。同样,减轻设备的重量可以减少设备消耗的主机资源。
device-weights
列出一个或多个设备/权重对的单个字符串,格式为 。每个权重必须在 100-1000 范围内,或者值为 0 才能从每台设备的列表中删除该设备。仅修改字符串中列出的设备;其他设备的任何现有每设备权重保持不变。/path/to/device,weight,/path/to/device,weight
config
添加更改在下次启动时生效的选项。--config
live
添加--live选项以将更改应用于正在运行的虚拟机。
注意:--live选项要求虚拟机管理程序支持此操作。并非所有虚拟机管理程序都允许实时更改最大内存限制。
current
添加选项以将更改应用于当前虚拟机。--current
例如,以下代码将 liftbrul VM 中/dev/sda设备的权重更改为 500。
# virsh blkiotune liftbrul --device-weights /dev/sda, 500注意:有关使用virsh blkiotune命令的更多信息,请使用virsh help blkiotune命令。
7.2. 缓存(caching)
缓存选项可以在虚拟机安装过程中使用 virt-manager 进行配置,或者在现有的虚拟机上通过编辑虚拟机 XML 配置来配置缓存选项。
| 缓存选项 | 描述 |
| Cache=none | 虚拟机的 I/O 不会缓存在宿主机上,但可以保存在写回磁盘缓存中。对于具有大量 I/O 要求的虚拟机,请使用此选项。此选项通常是最佳选择,也是支持迁移的唯一选项。 |
| Cache=writethrough | 虚拟机的 I/O 缓存在宿主机上,但会写入物理介质。此模式速度较慢,容易出现缩放问题。最适合用于 I/O 要求较低的少数虚拟机。建议用于不支持写回缓存(例如 Red Hat Enterprise Linux 5.5 及更早版本)的虚拟机,在这些虚拟机中不需要迁移。 |
| Cache=writeback | 虚拟机的 I/O 缓存在宿主机上。 |
| Cache=directsync | 类似于 writethrough ,但来自虚拟机的 I/O 会绕过宿主机页面缓存。 |
| Cache=unsafe | 宿主机可能会缓存所有磁盘 I/O,并且来自虚拟机的同步请求将被忽略。 |
| Cache=default | 如果未指定缓存模式,则选择系统的默认设置。 |
在 virt-manager 中,可以在 Virtual Disk 下指定缓存模式。有关使用 virt-manager 更改缓存模式的信息,请参见第 3.3 节 “虚拟磁盘性能选项”
要在虚拟机 XML 中配置缓存模式,请编辑driver标记内的cache设置以指定缓存选项。例如,要将缓存设置为写回:
<disk type='file' device='disk'> <driver name='qemu' type='raw' cache='writeback'/>
7.3. I/O模式
I/O 模式选项可以在虚拟机安装期间使用 virt-manager 进行配置,也可以在现有虚拟机虚拟机上通过编辑虚拟机XML 配置进行配置。
| IO 模式选项 | 描述 |
| IO=native | Red Hat Virtualization (RHV) 环境的默认值。此模式是指具有直接 I/O 选项的内核异步 I/O。 |
| IO=threads | 默认值是基于宿主机用户模式的线程。 |
| IO=default | Red Hat Enterprise Linux 7 中的默认设置是线程模式。 |
在 virt-manager 中,可以在 Virtual Disk 下指定 I/O 模式。有关使用 virt-manager 更改 I/O 模式的信息,请参见第 3.3 节 “虚拟磁盘性能选项”
要在虚拟机 XML 中配置 I/O 模式,请编辑driver标记内的io设置,并指定native、threads或default。例如,要将 I/O 模式设置为线程模式:
<disk type='file' device='disk'> <driver name='qemu' type='raw' io='threads'/>
7.4. Block I/O调优技术
本节介绍在虚拟化环境中调整模块 I/O 性能的更多技术。
7.4.1. 磁盘 I/O 节流
当多个虚拟机同时运行时,它们可能会使用过多的磁盘 I/O 来干扰系统性能。KVM 中的磁盘 I/O 限制提供了对从虚拟机发送到主机的磁盘 I/O 请求设置限制的功能。这可以防止虚拟机过度利用共享资源并影响其他虚拟机的性能。
磁盘 I/O 限制在各种情况下都很有用,例如,当属于不同客户的虚拟机在同一主机上运行时,或者当为不同的虚拟机提供服务质量保证时。磁盘 I/O 限制还可用于模拟速度较慢的磁盘。
I/O 限制可以独立应用于连接到虚拟机的每个块设备,并支持对吞吐量和 I/O 操作的限制。使用以下virsh blkdeviotune命令为虚拟机设置 I/O 限制:
# virsh blkdeviotune virtual_machine device --parameter limitDevice 为连接到虚拟机的其中一个磁盘设备指定唯一的目标名称 () 或源文件 (
)。使用virsh domblklist命令获取磁盘设备名称列表。
可选参数包括:
total-bytes-sec
总吞吐量限制(以每秒字节数为单位)。
read-bytes-sec
读取吞吐量限制(以每秒字节数为单位)。
write-bytes-sec
写入吞吐量限制(以每秒字节数为单位)。
total-iops-sec
每秒的总 I/O 操作限制。
read-iops-sec
每秒读取 I/O 操作数限制。
write-iops-sec
每秒写入 I/O 操作数限制。
例如,要限制virtual_machine上的vda到每秒 1000 个 I/O 操作和每秒 50 MB 的吞吐量,请运行以下命令:
# virsh blkdeviotune virtual_machine vda --total-iops-sec 1000 --total-bytes-sec 52428800
7.4.2. 多队列virtio-scsi
多队列 virtio-scsi 在 virtio-scsi 驱动程序中提供了改进的存储性能和可扩展性。它使每个虚拟 CPU 都可以使用单独的队列和中断,而不会影响其他 vCPU。
7.4.2.1. 配置多队列 virtio-scsi
多队列 virtio-scsi 在 Red Hat Enterprise Linux 7 上默认处于禁用状态。
要在虚拟机中启用多队列 virtio-scsi 支持,请将以下内容添加到虚拟机 XML 配置中,其中 N 是 vCPU 队列的总数:
<controller type='scsi' index='0' model='virtio-scsi'> <driver queues='N' /> </controller>
八、内存
本章介绍虚拟化环境的内存优化选项。
8.1. 内存调优技巧
要优化虚拟化环境中的内存性能,请考虑以下事项:
- 为来宾分配的资源不要多于其将使用的资源。
- 如果可能,请将来宾分配给单个 NUMA 节点,前提是该 NUMA 节点上的资源足够。有关使用 NUMA 的更多信息,请参见
8.2. 虚拟机上的内存调整
8.2.1. 内存监控工具
可以使用裸机环境中使用的工具在虚拟机中监视内存使用情况。用于监视内存使用情况和诊断内存相关问题的工具包括:
- top
- vmstat
- numastat
- /proc/
8.2.2. 使用 virsh 进行内存调整
虚拟机XML 配置中的可选元素允许管理员手动配置虚拟机内存设置。如果省略,则 VM 将根据 VM 创建期间的分配和分配方式使用内存。
使用以下virsh memtune命令在虚拟机的元素中显示或设置内存参数,并根据您的环境替换值:
virsh memtune virtual_machine --parameter size可选参数包括:
hard_limit
虚拟机可以使用的最大内存,以千字节(1024 字节的块)为单位。
警告
如果将此限制设置得太低,可能会导致虚拟机被内核终止。
soft_limit
在内存争用期间要执行的内存限制,以千字节(1024 字节的块)为单位。
swap_hard_limit
虚拟机可以使用的最大内存加上交换空间,以千字节(1024 字节的块)为单位。swap_hard_limit值必须大于hard_limit值。
min_guarantee
虚拟机的保证最小内存分配,以 kibibytes(1024 字节的块)为单位。
注意
有关使用virsh memtune命令的更多信息,请参阅# virsh help memtune。
可选元素可能包含多个元素,这些元素会影响主机页支持虚拟内存页的方式。
设置锁定可防止主机交换属于虚拟机的内存页。将以下内容添加到虚拟机XML 中,以锁定主机内存中的虚拟内存页:
<memoryBacking> <locked/> </memoryBacking>重要
设置 locked 时,必须在元素中将hard_limit设置为为虚拟机配置的最大内存,加上进程本身消耗的任何内存。
设置 nosharepages 可防止主机合并虚拟机之间使用的相同内存。要指示虚拟机管理程序禁用虚拟机的共享页面,请将以下内容添加到虚拟机的 XML 中:
<memoryBacking> <nosharepages/> </memoryBacking>8.2.3. 大页面和透明大页面
AMD64 和 Intel 64 CPU 通常以 4kB 页面处理内存,但它们能够使用更大的 2MB 或 1GB 页面,称为大页面。KVM 虚拟机可以部署大页面内存支持,以便通过增加对事务后备缓冲区 (TLB) 的 CPU 缓存命中来提高性能。
这是 Red Hat Enterprise Linux 7 中默认启用的内核功能,大页面可以显著提高性能,特别是对于大内存和内存密集型工作负载。Red Hat Enterprise Linux 7 能够通过使用大页面来增加页面大小,从而更有效地管理大量内存。为了提高管理大页面的有效性和便利性,Red Hat Enterprise Linux 7 默认使用透明大页面(THP)。有关大页面和 THP 的详细信息,请参阅性能优化指南。
Red Hat Enterprise Linux 7 系统支持 2MB 和 1GB 的大页面,可以在启动时或运行时分配。请参见第 8.2.3.3 节 “在引导或运行时为虚拟机第 8.2.3.3 节 “在引导或运行时为,了解有关启用多个大页面大小的说明。
8.2.3.1. 配置透明大页面
透明大页面 (THP) 是一个抽象层,可自动执行创建、管理和使用大页面的大部分方面。默认情况下,它们会自动优化系统设置以提高性能。
注意
使用 KSM 可以减少透明大页面的出现,因此建议在启用 THP 之前禁用 KSM。有关详细信息,请参见第 8.3.4 节 “停用 KSM”。
默认情况下,透明的大页面处于启用状态。要检查当前状态,请运行:
cat /sys/kernel/mm/transparent_hugepage/enabled要启用默认使用的透明大页面,请运行:
echo always > /sys/kernel/mm/transparent_hugepage/enabled这将/sys/kernel/mm/transparent_hugepage/enabled设置为始终。
要禁用透明的大页面:
echo never > /sys/kernel/mm/transparent_hugepage/enabled透明大页面(Transparent Huge Page)支持并不阻止使用静态大页面(static huge pages)。然而,当不使用静态大页面时,KVM 将会使用透明大页面,而不是常规的 4KB 页面大小。
8.2.3.2. 配置静态大页面
在某些情况下,对大页面的更大控制是可取的。要在虚拟机上使用静态大页面,请使用以下virsh edit命令将以下内容添加到虚拟机 XML 配置中:
<memoryBacking> <hugepages/> </memoryBacking>这将指示主机使用大页面为虚拟机分配内存,而不是使用默认页面大小。
通过运行以下命令查看当前大页面值:
cat /proc/sys/vm/nr_hugepages具体步骤
设置大页面
以下示例过程显示了用于设置大页面的命令。
- 查看当前超大页面值:
cat /proc/meminfo | grep Huge AnonHugePages: 2048 kB HugePages_Total: 0 HugePages_Free: 0 HugePages_Rsvd: 0 HugePages_Surp: 0 Hugepagesize: 2048 kB- 大页面以 2MB 为增量设置。要将大页数设置为 25000,请使用以下命令:
echo 25000 > /proc/sys/vm/nr_hugepages注意
要使设置持久化,请在虚拟机的 /etc/sysctl.conf 文件中添加以下行,其中 X 是您希望设置的大页面数量:
# echo 'vm.nr_hugepages = X' >> /etc/sysctl.conf
# sysctl -p随后,在虚拟机的 /etc/grub2.cfg 文件中的 /kernel 行末尾添加 transparent_hugepage=never 到内核启动参数中。
- 挂载大页面:
mount -t hugetlbfs hugetlbfs /dev/hugepages- 在虚拟机的 XML 配置中,将以下行添加到 memoryBacking 部分:
<hugepages> <page size='1' unit='GiB'/> </hugepages>- 重新启动 libvirtd:
systemctl restart libvirtd- 启动 VM:
virsh start virtual_machine如果 VM 已在运行,请重新启动它:
virsh reset virtual_machine- 验证/proc/meminfo位置的更改:
cat /proc/meminfo | grep Huge AnonHugePages: 0 kB HugePages_Total: 25000 HugePages_Free: 23425 HugePages_Rsvd: 0 HugePages_Surp: 0 Hugepagesize: 2048 kB大页面不仅可以使主人受益,还可以使客人受益,但是,它们的总大页面价值必须小于主机中可用的价值。
8.2.3.3. 在引导或运行时为 虚拟机 启用 1 GB 的大页面
Red Hat Enterprise Linux 7 系统支持 2MB 和 1GB 的大页面,可以在启动时或运行时分配。
具体步骤
在启动时分配 1GB 的大页面
- 要在启动时分配不同大小的大页面,请使用以下命令并指定大页面的数量。此示例分配 4 个 1GB 大页面和 1024 个 2MB 大页面:
'default_hugepagesz=1G hugepagesz=1G hugepages=4 hugepagesz=2M hugepages=1024'更改此命令行以指定在启动时要分配的不同数量的大页面。
注意
接下来的两个步骤也必须在启动时首次分配 1GB 大页面时完成。
- 在主机上挂载 2MB 和 1GB 的大页面:
mkdir /dev/hugepages1G mount -t hugetlbfs -o pagesize=1G none /dev/hugepages1G mkdir /dev/hugepages2M mount -t hugetlbfs -o pagesize=2M none /dev/hugepages2M- 在虚拟机的 XML 配置中,将以下行添加到 memoryBacking 部分:
<hugepages> <page size='1' unit='GiB'/> </hugepages>- 重新启动 libvirtd 以允许在虚拟机上使用 1GB 的大页面:
systemctl restart libvirtd在运行时分配 1GB 的大页面
也可以在运行时分配 1GB 的大页面。运行时分配允许系统管理员选择要从哪个 NUMA 节点分配这些页面。但是,由于内存碎片,运行时页面分配比启动时间分配更容易出现分配失败。
- 若要在运行时分配不同大小的大页面,请使用以下命令,替换大页面数的值、要从中分配它们的 NUMA 节点以及大页面大小:
echo 4 > /sys/devices/system/node/node1/hugepages/hugepages-1048576kB/nr_hugepages echo 1024 > /sys/devices/system/node/node3/hugepages/hugepages-2048kB/nr_hugepages此示例命令分配node1 4 个 1GB 大页面和node3 1024 个 2MB 大页面。
可以使用上述命令随时更改这些大页面设置,具体取决于主机系统上的可用内存量。
注意
接下来的两个步骤也必须在运行时首次分配 1GB 大页面时完成。
- 在主机上挂载 2MB 和 1GB 的大页面:
mkdir /dev/hugepages1G
mount -t hugetlbfs -o pagesize=1G none /dev/hugepages1G
mkdir /dev/hugepages2M
mount -t hugetlbfs -o pagesize=2M none /dev/hugepages2M- 在虚拟机的 XML 配置中,将以下行添加到 memoryBacking 部分:
<hugepages> <page size='1' unit='GiB'/> </hugepages>- 重新启动 libvirtd 以允许在虚拟机上使用 1GB 的大页面:
systemctl restart libvirtd8.3. 内核同页合并(KSM)
内核同页合并(KSM),由KVM虚拟机监控程序使用,允许KVM虚拟机共享相同的内存页面。这些共享页面通常是常用的公共库或其他相同的高使用率数据。KSM通过避免内存重复使用,允许在相同或相似的虚拟机操作系统中实现更高的虚拟机密度。
共享内存的概念在现代操作系统中非常普遍。例如,当一个程序首次启动时,它会与父程序共享其所有内存。当子程序或父程序尝试修改这段内存时,内核会分配一个新的内存区域,复制原始内容,并允许程序修改这个新区域。这被称为按需复制(copy on write)。
KSM是一个Linux特性,它以相反的方式使用此概念。KSM使内核能够检查两个或多个已经运行的程序并比较它们的内存。如果发现任何内存区域或页面是相同的,KSM会将多个相同的内存页面合并为一个页面。这个页面随后被标记为按需复制。如果虚拟机的客人修改了该页面的内容,内核会为该客人创建一个新页面。
这对于使用KVM进行虚拟化非常有用。当启动一个客虚拟机时,它仅继承主机qemu-kvm进程的内存。一旦虚拟机运行,该虚拟机操作系统镜像的内容可以在运行相同操作系统或应用程序的虚拟机之间共享。KSM允许KVM请求这些相同的客内存区域进行共享。
KSM提供了增强的内存速度和利用率。通过KSM,常见的进程数据存储在缓存或主内存中。这减少了KVM虚拟机的缓存未命中率,从而可以提高某些应用程序和操作系统的性能。其次,内存共享减少了虚拟机总内存的使用,这允许更高的密度和更大的资源利用率。
注意
在红帽企业Linux 7中,KSM(内存重复页合并)是意识到NUMA(非统一内存访问)架构的。这使得KSM在合并页面时能够考虑到NUMA的局部性,从而防止与页面移动到远程节点相关的性能下降。红帽建议在使用KSM时避免跨节点内存合并。如果在使用KSM,应将/sys/kernel/mm/ksm/merge_across_nodes的可调参数更改为0,以避免在NUMA节点之间合并页面。可以使用命令virsh node-memory-tune --shm-mergeacross-nodes 0来实现这一点。经过大量跨节点合并后,内核内存会计统计信息可能会相互矛盾。因此,在KSM守护进程合并大量内存后,numad可能会变得困惑。如果系统有大量空闲内存,您可能会通过关闭和禁用KSM守护进程来实现更高的性能。有关NUMA的更多信息,请参见第9章“NUMA”。
重要
确保在不考虑KSM的情况下,交换空间的大小足以满足已分配的RAM。KSM减少了相同或相似虚拟机的RAM使用。虽然在KSM下可能存在超分配虚拟机而没有足够的交换空间,但不推荐这样做,因为客户虚拟机内存的使用可能会导致页面变得不共享。
红帽企业Linux使用两种独立的方法来控制KSM(内存重复页合并):
- ksm服务:启动和停止KSM内核线程。
- ksmtuned服务:控制和调整ksm服务,动态管理相同页面的合并。ksmtuned会启动ksm服务,如果不需要内存共享,则会停止ksm服务。当新的虚拟机被创建或销毁时,必须使用retune参数指示ksmtuned进行运行。
这两个服务都可以通过标准的服务管理工具进行控制。
8.3.1 KSM 服务
- ksm服务包含在 qemu-kvm 软件包中。
- 当ksm服务未启动时,内核同页合并 (KSM) 仅共享 2000 个页面。此默认值提供有限的内存节省优势。
- 当ksm服务启动时,KSM 将共享主机系统最多一半的主内存。启动ksm服务以使 KSM 能够共享更多内存。
# systemctl start ksm
Starting ksm: [ OK ]![]()
可以将ksm服务添加到默认启动序列中。使用 systemctl 命令使ksm服务持久化。
systemctl enable ksm![]()
8.3.2 KSM 调优服务
ksmtuned服务通过循环和调整ksm来微调内核同页合并 (KSM) 配置。此外,当创建或销毁虚拟机时,libvirt 会通知ksmtuned服务。ksmtuned服务没有选项。
# systemctl start ksmtuned
Starting ksmtuned: [ OK ]![]()
可以使用 retune 参数来调整ksmtuned服务,ksmtuned参数指示手动运行调整函数。
/etc/ksmtuned.conf文件是ksmtuned服务的配置文件。下面的文件输出是默认ksmtuned.conf文件:
# Configuration file for ksmtuned.
# How long ksmtuned should sleep between tuning adjustments
# KSM_MONITOR_INTERVAL=60
# Millisecond sleep between ksm scans for 16Gb server.
# Smaller servers sleep more, bigger sleep less.
# KSM_SLEEP_MSEC=10
# KSM_NPAGES_BOOST - is added to the `npages` value, when `free memory` is less than `thres`.
# KSM_NPAGES_BOOST=300
# KSM_NPAGES_DECAY - is the value given is subtracted to the `npages` value, when `free memory` is greater than `thres`.
# KSM_NPAGES_DECAY=-50
# KSM_NPAGES_MIN - is the lower limit for the `npages` value.
# KSM_NPAGES_MIN=64
# KSM_NPAGES_MAX - is the upper limit for the `npages` value.
# KSM_NPAGES_MAX=1250
# KSM_THRES_COEF - is the RAM percentage to be calculated in parameter `thres`.
# KSM_THRES_COEF=20
# KSM_THRES_CONST - If this is a low memory system, and the `thres` value is less than `KSM_THRES_CONST`, then reset `thres` value to `KSM_THRES_CONST` value.
# KSM_THRES_CONST=2048
# uncomment the following to enable ksmtuned debug information
# LOGFILE=/var/log/ksmtuned
# DEBUG=1![]()
在 /etc/ksmtuned.conf 文件中,npages 设置了在 ksmd 守护进程变为非活动状态之前,ksm 将扫描多少页面。这个值也会被设置在 /sys/kernel/mm/ksm/pages_to_scan 文件中。KSM_THRES_CONST 值表示用于激活 ksm 的可用内存阈值。当以下任一情况发生时,ksmd 将被激活:
- 可用内存量降至低于在 KSM_THRES_CONST 中设置的阈值。
- 已承诺的内存量加上阈值 KSM_THRES_CONST 超过总内存量。
8.3.3 KSM变量和监控
内核同页合并 (KSM) 将监控数据存储在/sys/kernel/mm/ksm/目录中。/etc/ksmtuned.conf目录中的文件由内核更新,是 KSM 使用情况和统计信息的准确记录。
如上所述,下面列表中的变量也是文件中的可配置变量。
/sys/kernel/mm/ksm/中的文件:
- full_scans
运行完全扫描。
- merge_across_nodes
来自不同 NUMA 节点的页面是否可以合并。
- pages_shared
共享的总页数。
- pages_sharing
当前共享的页面。
- pages_to_scan
未扫描的页面。
- pages_unshared
不再共享页面。
- pages_volatile
易失效页数。
- run
KSM 进程是否正在运行。
- sleep_millisecs
睡眠毫秒。
可以使用virsh node-memory-tune命令手动调整这些变量。例如,以下代码指定了在共享内存服务进入睡眠状态之前要扫描的页数:
# virsh node-memory-tune --shm-pages-to-scan number![]()
如果在 /etc/ksmtuned.conf 文件中添加 DEBUG=1 行,KSM 调优活动将被存储在 /var/log/ksmtuned 日志文件中。日志文件的位置可以通过 LOGFILE 参数进行更改。不建议更改日志文件的位置,这可能需要对 SELinux 设置进行特殊配置。
8.3.4 停用 KSM
内核同页合并 (KSM) 具有性能开销,对于某些环境或主机系统来说可能太大。KSM 还可能引入可能用于在客人之间泄露信息的侧信道。如果这是一个问题,可以根据每个客人禁用 KSM。
可以通过停止ksmtuned 和ksm 服务来停用 KSM。但是,此操作在重新启动后不会持续存在。要停用 KSM,请以 root 身份在终端中运行以下命令:
# systemctl stop ksmtuned
Stopping ksmtuned: [ OK ]
# systemctl stop ksm
Stopping ksm: [ OK ]![]()
停止 ksmtuned和 ksm停用 KSM,但此操作在重新启动后不会持续存在。使用以下systemctl命令持续停用 KSM:
# systemctl disable ksm
# systemctl disable ksmtuned![]()
禁用 KSM 后,在停用 KSM 之前共享的任何内存页仍将共享。要删除系统中的所有 PageKSM,请使用以下命令:
# echo 2 >/sys/kernel/mm/ksm/run![]()
执行此操作后,khugepaged守护进程可以在 KVM 虚拟机物理内存上重建透明的大页面。使用# echo 0 >/sys/kernel/mm/ksm/run 会停止 KSM,但不会取消共享所有以前创建的 KSM 页面(这与 #systemctl stop ksmtuned 命令相同)。
九、NUMA
从历史上看,AMD64 和 Intel 64 系统上的所有内存都可以由所有 CPU 平等访问。称为统一内存访问 (UMA),无论哪个 CPU 执行操作,访问时间都是相同的。
最新的 AMD64 和 Intel 64 处理器不再出现此行为。在非一致性内存访问 (NUMA) 中,系统内存分布在 NUMA 节点之间,这些节点对应于套接字或一组特定的 CPU,这些 CPU 对系统内存的本地子集具有相同的访问延迟。
本章介绍虚拟化环境中的内存分配和 NUMA 调优配置。
9.1. NUMA 内存分配策略
以下策略定义了如何从系统中的节点分配内存:
Strict
严格策略意味着如果无法在目标节点上分配内存,则分配将失败。指定 NUMA 节点集列表而不定义内存模式属性默认为严格模式。
Interleave
内存页在节点集指定的节点之间分配,但以循环方式分配。
Preferred
内存是从单个首选内存节点分配的。如果没有足够的内存可用,则可以从其他节点分配内存。
若要启用预期的策略,请将其设置为域 XML 文件元素的值:
<numatune> <memory mode='preferred' nodeset='0'> </numatune>重要
如果内存在严格模式下超额使用,并且虚拟机没有足够的交换空间,内核将终止一些虚拟机进程以检索额外的内存。Red Hat 建议使用首选分配并指定单个节点集(例如,nodeset='0')来防止这种情况。
9.2. 自动 NUMA 平衡
自动 NUMA 平衡可提高在 NUMA 硬件系统上运行的应用程序的性能。默认情况下,它在 Red Hat Enterprise Linux 7 系统上处于启用状态。
当应用程序的进程线程在调度线程的同一 NUMA 节点上访问内存时,应用程序通常性能最佳。自动 NUMA 平衡将任务(可以是线程或进程)移动到更靠近它们正在访问的内存的位置。它还将应用程序数据移动到更靠近引用它的任务的内存中。当自动 NUMA 平衡处于活动状态时,这一切都由内核自动完成。
自动 NUMA 平衡使用许多算法和数据结构,这些算法和数据结构仅在系统上的自动 NUMA 平衡处于活动状态并分配时才被分配:
- 进程内存的定期 NUMA 取消映射
- NUMA 提示故障
- Migrate-on-Fault (MoF) - 将内存移动到使用它的程序运行的位置
- task_numa_placement - 将正在运行的程序移近其内存
9.2.1. 配置自动 NUMA 平衡
在 Red Hat Enterprise Linux 7 中,自动 NUMA 均衡默认处于启用状态,并且在具有 NUMA 属性的硬件上启动时将自动激活。
当满足以下两个条件时,将启用自动 NUMA 平衡:
- # numactl --hardware 显示多个节点
- # cat /proc/sys/kernel/numa_balancing 显示1
应用程序的手动 NUMA 调整将覆盖自动 NUMA 平衡,禁用内存的定期取消映射、NUMA 故障、迁移以及这些应用程序的自动 NUMA 放置。
在某些情况下,系统范围的手动 NUMA 调优是首选。
若要禁用自动 NUMA 平衡,请使用以下命令:
# echo 0 > /proc/sys/kernel/numa_balancing若要启用自动 NUMA 平衡,请使用以下命令:
# echo 1 > /proc/sys/kernel/numa_balancing9.3. libvirt NUMA 调优
通常,NUMA 系统上的最佳性能是通过将虚拟机大小限制为单个 NUMA 节点上的资源量来实现的。避免在 NUMA 节点之间不必要地拆分资源。
使用numastat工具可以查看进程和操作系统的每个 NUMA 节点内存统计信息。
在以下示例中,numastat工具显示了四个虚拟机,这些虚拟机在 NUMA 节点之间的内存对齐次优:
# numastat -c qemu-kvm
Per-node process memory usage (in MBs)
PID Node 0 Node 1 Node 2 Node 3 Node 4 Node 5 Node 6 Node 7 Total
--------------- ------ ------ ------ ------ ------ ------ ------ ------ -----
51722 (qemu-kvm) 68 16 357 6936 2 3 147 598 8128
51747 (qemu-kvm) 245 11 5 18 5172 2532 1 92 8076
53736 (qemu-kvm) 62 432 1661 506 4851 136 22 445 8116
53773 (qemu-kvm) 1393 3 1 2 12 0 0 6702 8114
--------------- ------ ------ ------ ------ ------ ------ ------ ------ -----
Total 1769 463 2024 7462 10037 2672 169 7837 32434运行numad以自动对齐虚拟机的 CPU 和内存资源。
然后再次运行numastat -c qemu-kvm以查看numad运行的结果。以下输出显示资源已对齐:
# numastat -c qemu-kvm
Per-node process memory usage (in MBs)
PID Node 0 Node 1 Node 2 Node 3 Node 4 Node 5 Node 6 Node 7 Total
--------------- ------ ------ ------ ------ ------ ------ ------ ------ -----
51747 (qemu-kvm) 0 0 7 0 8072 0 1 0 8080
53736 (qemu-kvm) 0 0 7 0 0 0 8113 0 8120
53773 (qemu-kvm) 0 0 7 0 0 0 1 8110 8118
59065 (qemu-kvm) 0 0 8050 0 0 0 0 0 8051
--------------- ------ ------ ------ ------ ------ ------ ------ ------ -----
Total 0 0 8072 0 8072 0 8114 8110 32368注意
运行numastat提供-c的输出;添加-m选项会将每个节点的系统范围内存信息添加到输出中。有关更多信息,请参见numastat手册页。
9.3.1. 监控每个主机 NUMA 节点的内存
您可以使用nodestats.py脚本报告主机上每个 NUMA 节点的总内存和可用内存。此脚本还报告每个正在运行的域的特定主机节点严格绑定的内存量。例如:
# /usr/share/doc/libvirt-python-2.0.0/examples/nodestats.py
NUMA stats
NUMA nodes: 0 1 2 3
MemTotal: 3950 3967 3937 3943
MemFree: 66 56 42 41
Domain 'rhel7-0':
Overall memory: 1536 MiB
Domain 'rhel7-1':
Overall memory: 2048 MiB
Domain 'rhel6':
Overall memory: 1024 MiB nodes 0-1
Node 0: 1024 MiB nodes 0-1
Domain 'rhel7-2':
Overall memory: 4096 MiB nodes 0-3
Node 0: 1024 MiB nodes 0
Node 1: 1024 MiB nodes 1
Node 2: 1024 MiB nodes 2
Node 3: 1024 MiB nodes 3此示例显示四个主机 NUMA 节点,每个节点总共包含大约 4GB 的 RAM (MemTotal)。几乎所有内存都消耗在每个域 (MemFree) 上。有四个域(虚拟机)在运行:域“rhel7-0”具有 1.5GB 内存,该内存未固定到任何特定的主机 NUMA 节点。但是,域“rhel7-2”具有 4GB 内存和 4 个 NUMA 节点,这些节点以 1:1 的比例固定到主机节点。
要打印主机 NUMA 节点统计信息,请为您的环境创建一个nodestats.py脚本。可以在 libvirt-python 包文件/usr/share/doc/libvirt-python-version/examples/nodestats.py中找到示例脚本。可以使用rpm -ql libvirt-python命令显示脚本的特定路径。
9.3.2. NUMA vCPU绑定
vCPU 绑定与裸机系统上的任务绑定具有类似的优势。由于 vCPU 在主机操作系统上作为用户空间任务运行,因此绑定可以提高缓存效率。例如,在某个环境中,所有 vCPU 线程都运行在同一物理套接字上,因此共享一个 L3 缓存域。
注意
在 Red Hat Enterprise Linux 版本 7.0 到 7.2 中,只能绑定活动的 vCPU。但是,在 Red Hat Enterprise Linux 7.3 中,绑定非活动 vCPU 也是可用的。
将 vCPU 固定与 vCPU 固定结合使用numatune可以避免 NUMA 未命中。NUMA 未命中对性能的影响非常大,通常从 10% 或更高的性能影响开始。vCPU 绑定和numatune应一起配置。
如果虚拟机正在执行存储或网络 I/O 任务,则将所有 vCPU 和内存绑定到物理连接到 I/O 适配器的同一物理套接字可能会有所帮助。
注意
lstopo 工具可用于可视化 NUMA 拓扑。它还可以帮助验证 vCPU 是否绑定到同一物理插槽上的核心。有关 lstopo 的更多信息,请参阅以下知识库文章:How can I visualize my system's NUMA topology in Red Hat Enterprise Linux? - Red Hat Customer Portal。
重要
当 vCPU 数量比物理核心多得多时,固定会导致复杂性增加。
以下示例 XML 配置将域进程绑定到物理 CPU 0-7。vCPU 线程绑定到其自己的 cpuset。例如,vCPU0 固定到物理 CPU 0,vCPU1 固定到物理 CPU 1,依此类推:
<vcpu cpuset='0-7'>8</vcpu>
<cputune>
<vcpupin vcpu='0' cpuset='0'/>
<vcpupin vcpu='1' cpuset='1'/>
<vcpupin vcpu='2' cpuset='2'/>
<vcpupin vcpu='3' cpuset='3'/>
<vcpupin vcpu='4' cpuset='4'/>
<vcpupin vcpu='5' cpuset='5'/>
<vcpupin vcpu='6' cpuset='6'/>
<vcpupin vcpu='7' cpuset='7'/>
</cputune>虚拟CPU(vcpu)和虚拟CPU固定(vcpupin)标签之间存在直接关系。如果未指定vcpupin选项,则该值将自动确定并从父vcpu标签选项中继承。以下配置显示了vCPU 5的缺失。因此,vCPU5将被固定到物理CPU 0-7,如父标签所指定的那样:
<vcpu cpuset='0-7'>8</vcpu>
<cputune>
<vcpupin vcpu='0' cpuset='0'/>
<vcpupin vcpu='1' cpuset='1'/>
<vcpupin vcpu='2' cpuset='2'/>
<vcpupin vcpu='3' cpuset='3'/>
<vcpupin vcpu='4' cpuset='4'/>
<vcpupin vcpu='6' cpuset='6'/>
<vcpupin vcpu='7' cpuset='7'/>
</cputune>重要
、、和 应一起配置以实现最佳的确定性性能。有关标签的更多信息,请参见第 9.3.3 节 “域进程”。有关标签的更多信息,请参见第 9.3.6 节 “使用 emulatorpin”。
9.3.3. 域进程(Domain Processes)
正如 Red Hat Enterprise Linux 中提供的那样,libvirt 使用 libnuma 为域进程设置内存绑定策略。这些策略的节点集可以配置为静态(在域 XML 中指定)或自动(通过查询 numad 配置)。有关如何在标签内配置这些配置的示例,请参阅以下 XML 配置:
<numatune> <memory mode='strict' placement='auto'/> </numatune>
<numatune> <memory mode='strict' nodeset='0,2-3'/> </numatune>libvirt 使用 sched_setaffinity(2) 为域进程设置 CPU 绑定策略。cpuset 选项可以是 static(在域 XML 中指定)或 auto(通过查询 numad 配置)。有关如何在标签内配置这些配置的示例,请参阅以下 XML 配置:
<vcpu placement='auto'>8</vcpu>
<vcpu placement='static' cpuset='0-10,ˆ5'>8</vcpu>在用于和的放置模式之间存在隐式继承规则:
- 的放置模式默认为与相同的放置模式,或者如果指定了,则默认为静态模式。
- 同样,的放置模式默认为与相同的放置模式,或者如果指定了,则默认为静态模式。
这意味着可以单独指定和定义域进程的CPU调优和内存调优,但它们也可以配置为依赖于对方的放置模式。
此外,还可以使用numad配置系统,以在启动时启用选定数量的vCPU,而不必在启动时固定所有vCPU。
例如,要在具有32个vCPU的系统上启动时仅启用8个vCPU,可以将XML配置类似于以下内容:
<vcpu placement='auto' current='8'>32</vcpu>注意
有关 vcpu 和 numatune 的更多信息,请参阅以下 URL:libvirt: Domain XML format 和 libvirt: Domain XML format
9.3.4. 域vCPU线程
除了调优域进程外,libvirt 还允许为 XML 配置中的每个 vcpu 线程设置固定策略。为标签内的每个 vcpu 线程设置固定策略:
<cputune>
<vcpupin vcpu="0" cpuset="1-4,ˆ2"/>
<vcpupin vcpu="1" cpuset="0,1"/>
<vcpupin vcpu="2" cpuset="2,3"/>
<vcpupin vcpu="3" cpuset="0,4"/>
</cputune>在此标签中,libvirt 使用 cgroup 或 sched_setaffinity(2) 将 vcpu 线程固定到指定的 cpuset。
注意
有关 的更多详细信息,请参阅以下 URL:libvirt: Domain XML format
此外,如果需要设置具有更多 vCPU 的虚拟机,而不是单个 NUMA 节点,请配置主机,以便虚拟机在主机上检测 NUMA 拓扑。这允许 CPU、内存和 NUMA 节点的 1:1 映射。例如,这可以应用于具有 4 个 vCPU 和 6 GB 内存的虚拟机,以及具有以下 NUMA 设置的主机:
4 available nodes (0-3)
Node 0: CPUs 0 4, size 4000 MiB
Node 1: CPUs 1 5, size 3999 MiB
Node 2: CPUs 2 6, size 4001 MiB
Node 3: CPUs 0 4, size 4005 MiB在此方案中,请使用以下域 XML 设置:
<cputune>
<vcpupin vcpu="0" cpuset="1"/>
<vcpupin vcpu="1" cpuset="5"/>
<vcpupin vcpu="2" cpuset="2"/>
<vcpupin vcpu="3" cpuset="6"/>
</cputune>
<numatune>
<memory mode="strict" nodeset="1-2"/>
</numatune>
<cpu>
<numa>
<cell id="0" cpus="0-1" memory="3" unit="GiB"/>
<cell id="1" cpus="2-3" memory="3" unit="GiB"/>
</numa>
</cpu>9.3.5. 使用缓存分配技术提高性能
您可以在特定 CPU 型号上使用内核提供的缓存分配技术 (CAT)。这样就可以为 vCPU 线程分配主机 CPU 的部分缓存,从而提高实时性能。
有关如何在cachetune标签内配置 vCPU 缓存分配的示例,请参阅以下 XML 配置:
<domain>
<cputune>
<cachetune vcpus='0-1'>
<cache id='0' level='3' type='code' size='3' unit='MiB'/>
<cache id='0' level='3' type='data' size='3' unit='MiB'/>
</cachetune>
</cputune>
</domain>上面的 XML 文件将 vCPU 0 和 1 的线程配置为分配来自第一个 L3 缓存 (level='3' id='0') 的 3 MiB,一次用于 L3CODE,一次用于 L3DATA。
注意
单个虚拟机可以有多个元素。
9.3.6. 使用 emulatorpin
调整域进程固定策略的另一种方法是在 中使用 内的标记。
标签指定模拟器(域的子集,不包括 vCPU)将固定到哪些主机物理 CPU。标签提供了一种设置与仿真器线程进程的精确关联的方法。因此,虚拟主机线程在物理 CPU 和内存的同一子集上运行,因此受益于缓存局部性。例如:
<cputune> <emulatorpin cpuset="1-3"/> </cputune>注意
在 Red Hat Enterprise Linux 7 中,默认情况下会启用自动 NUMA 均衡。自动 NUMA 平衡减少了手动调整的需要,因为 vhost-net 仿真器线程更可靠地遵循 vCPU 任务。有关自动 NUMA 平衡的更多信息,请参见第 9.2 节 “自动 NUMA 平衡”。
9.3.7. 调整 vCPU 使用 virsh 进行固定
重要
这些只是示例命令。您将需要根据您的环境替换值。
以下示例virsh命令将 ID 为 1 的 vcpu 线程 rhel7 固定到物理 CPU 2:
% virsh vcpupin rhel7 1 2您也可以使用virsh命令获取当前的 vcpu pinning 配置。例如:
% virsh vcpupin rhel79.3.8. 使用 virsh 调整域进程 CPU 固定
重要
这些只是示例命令。您将需要根据您的环境替换值。
emulatorpin选项将CPU亲和性设置应用于与每个域进程相关联的线程。要实现完全固定,您必须对每个虚拟机同时使用virsh vcpupin(如前所示)和virsh emulatorpin。例如:
% virsh emulatorpin rhel7 3-49.3.9. 使用 virsh 调整域进程内存策略
域进程内存可以动态调整。请参阅以下示例命令:
% virsh numatune rhel7 --nodeset 0-10可以在virsh手册页中找到这些命令的更多示例。
9.3.10. 虚拟机NUMA拓扑
虚拟机 NUMA 拓扑可以使用虚拟机的 XML 中标签内的标签来指定。请参阅以下示例,并相应地替换值:
<cpu>
...
<numa>
<cell cpus='0-3' memory='512000'/>
<cell cpus='4-7' memory='512000'/>
</numa>
...
</cpu>每个元素指定一个NUMA单元或NUMA节点。cpus指定该节点的一部分CPU或CPU范围,memory指定节点内存(单位为Kibibytes,即1024字节的块)。每个单元或节点以递增的顺序从0开始分配cellid或nodeid。
重要
在修改具有配置的CPU插槽、内核和线程拓扑的客户虚拟机的NUMA拓扑时,请确保属于同一插槽的内核和线程被分配到同一NUMA节点。如果来自同一插槽的线程或内核被分配到不同的NUMA节点,虚拟机可能无法启动。
警告
在红帽企业Linux 7中,同时使用虚拟机NUMA拓扑和大页并不受支持,仅在红帽虚拟化或红帽OpenStack平台等分层产品中可用。
9.3.11. PCI设备的NUMA节点位置
启动新虚拟机时,了解主机 NUMA 拓扑和 PCI 设备与 NUMA 节点的隶属关系非常重要,以便在请求 PCI 直通时,将虚拟机固定到正确的 NUMA 节点上,以实现最佳内存性能。
例如,如果虚拟机固定到 NUMA 节点 0-1,但其其中一个 PCI 设备与节点 2 关联,则节点之间的数据传输将需要一些时间。
在 Red Hat Enterprise Linux 7.1 及更高版本中,libvirt 在虚拟机 XML 中报告 PCI 设备的 NUMA 节点位置,使管理应用程序能够做出更好的性能决策。
此信息在sysfs 中的/sys/devices/pci*/*/numa_node文件中可见。验证这些设置的一种方法是使用 lstopo 工具报告sysfs数据:
# lstopo-no-graphics
Machine (126GB)
NUMANode L#0 (P#0 63GB)
Socket L#0 + L3 L#0 (20MB)
L2 L#0 (256KB) + L1d L#0 (32KB) + L1i L#0 (32KB) + Core L#0 + PU L#0 (P#0)
L2 L#1 (256KB) + L1d L#1 (32KB) + L1i L#1 (32KB) + Core L#1 + PU L#1 (P#2)
L2 L#2 (256KB) + L1d L#2 (32KB) + L1i L#2 (32KB) + Core L#2 + PU L#2 (P#4)
L2 L#3 (256KB) + L1d L#3 (32KB) + L1i L#3 (32KB) + Core L#3 + PU L#3 (P#6)
L2 L#4 (256KB) + L1d L#4 (32KB) + L1i L#4 (32KB) + Core L#4 + PU L#4 (P#8)
L2 L#5 (256KB) + L1d L#5 (32KB) + L1i L#5 (32KB) + Core L#5 + PU L#5 (P#10)
L2 L#6 (256KB) + L1d L#6 (32KB) + L1i L#6 (32KB) + Core L#6 + PU L#6 (P#12)
L2 L#7 (256KB) + L1d L#7 (32KB) + L1i L#7 (32KB) + Core L#7 + PU L#7 (P#14)
HostBridge L#0
PCIBridge
PCI 8086:1521
Net L#0 "em1"
PCI 8086:1521
Net L#1 "em2"
PCI 8086:1521
Net L#2 "em3"
PCI 8086:1521
Net L#3 "em4"
PCIBridge
PCI 1000:005b
Block L#4 "sda"
Block L#5 "sdb"
Block L#6 "sdc"
Block L#7 "sdd"
PCIBridge
PCI 8086:154d
Net L#8 "p3p1"
PCI 8086:154d
Net L#9 "p3p2"
PCIBridge
PCIBridge
PCIBridge
PCIBridge
PCI 102b:0534
GPU L#10 "card0"
GPU L#11 "controlD64"
PCI 8086:1d02
NUMANode L#1 (P#1 63GB)
Socket L#1 + L3 L#1 (20MB)
L2 L#8 (256KB) + L1d L#8 (32KB) + L1i L#8 (32KB) + Core L#8 + PU L#8 (P#1)
L2 L#9 (256KB) + L1d L#9 (32KB) + L1i L#9 (32KB) + Core L#9 + PU L#9 (P#3)
L2 L#10 (256KB) + L1d L#10 (32KB) + L1i L#10 (32KB) + Core L#10 + PU L#10 (P#5)
L2 L#11 (256KB) + L1d L#11 (32KB) + L1i L#11 (32KB) + Core L#11 + PU L#11 (P#7)
L2 L#12 (256KB) + L1d L#12 (32KB) + L1i L#12 (32KB) + Core L#12 + PU L#12 (P#9)
L2 L#13 (256KB) + L1d L#13 (32KB) + L1i L#13 (32KB) + Core L#13 + PU L#13 (P#11)
L2 L#14 (256KB) + L1d L#14 (32KB) + L1i L#14 (32KB) + Core L#14 + PU L#14 (P#13)
L2 L#15 (256KB) + L1d L#15 (32KB) + L1i L#15 (32KB) + Core L#15 + PU L#15 (P#15)
HostBridge L#8
PCIBridge
PCI 1924:0903
Net L#12 "p1p1"
PCI 1924:0903
Net L#13 "p1p2"
PCIBridge
PCI 15b3:1003
Net L#14 "ib0"
Net L#15 "ib1"
OpenFabrics L#16 "mlx4_0"此输出显示:
- NICs em* 和 disks sd* 连接到 NUMA 节点 0,以及核心 0、2、4、6、8、10、12、14。
- NICs p1* 和 ib* 连接到 NUMA 节点 1,以及核心 1、3、5、7、9、11、13、15。
9.4. NUMA 感知内核 SamePage 合并 (KSM)
内核 SamePage 合并 (KSM) 允许虚拟机共享相同的内存页。KSM 可以检测系统是否正在使用 NUMA 内存,并控制不同 NUMA 节点之间的合并页面。
使用sysfs /sys/kernel/mm/ksm/merge_across_nodes参数可控制跨不同 NUMA 节点的页面合并。默认情况下,所有节点的页面都可以合并在一起。当此参数设置为零时,仅合并来自同一节点的页面。
通常,除非您超额订阅系统内存,否则通过禁用 KSM 共享将获得更好的运行时性能。
重要
当 KSM 在具有多个虚拟机的 NUMA 主机上的节点之间合并时,来自更远节点的虚拟机和 CPU 可能会显著增加对合并的 KSM 页面的访问延迟。
要指示虚拟机管理程序禁用虚拟机的共享页面,请将以下内容添加到虚拟机的 XML 中:
<memoryBacking> <nosharepages/> </memoryBacking>有关使用元素调整内存设置的更多信息,请参见第 8.2.2 节 “使用 virsh 进行内存调整”。

















 897
897

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











