










在docker容器的实际应用中,对于我这样的测试来讲
最头疼的事情反而是有时候需要同时操作容器外和容器内
容器外给挂载的路径rz文件,编译服务(以供容器内启动使用),查看日志
而容器内则负责启动服务,查看进程等操作
经常不小心操作错误
后来想到个解决方式就是像这样
把容器外和容器内用标签分开
并且给登入容器的配类似这样的脚本
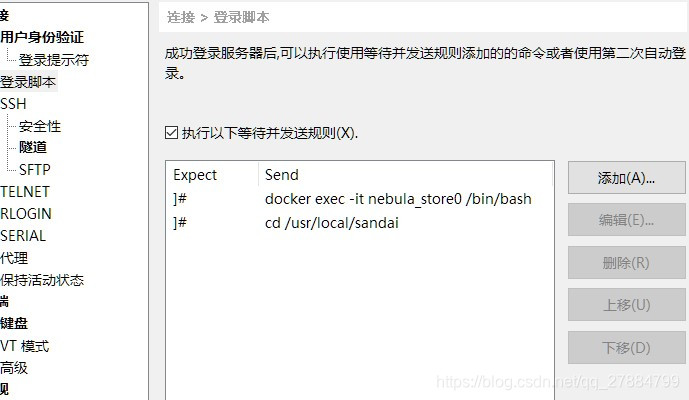
但到了后来,模拟的节点变多,容器越来越多
store这个容器已经多到了18个,还可能更多,这样配置文件显得非常麻烦
解决:
其实xshell是有会话文件的,一般在~/Documents/NetSarang Computer/6/Xshell/Sessions下面,或者windows下相当于C:\Users\用户名\Documents/NetSarang Computer/6/Xshell/Sessions下面是会话文件的保存位置,文件后缀为xsh
我比对了store0和store1的xsh文件,发现仅有这一行不一样
ExpectSend_Send_0=docker exec -it nebula_store0 /bin/bash
这里记录的是具体的expect命令,我只需要批量修改这里并且生成xsh文件就可以
把文件内容复制,放到python中,将命令用{}活化,再在循环里用变量格式化文件名和文件内容
import codecs
model = """
[CONNECTION:PROXY]
Proxy=
# ......略
ExpectSend_Expect_0=]#
ExpectSend_Send_0=docker exec -it nebula_store{} /bin/bash
Library=0
# ......略
SendKeepAlive=0
KeepAlive=1
""".replace("\n", "\r\n")
for i in range(0, 18):
with open("新内网测试(store{}).xsh".format(i), "wb") as f:
f.write(codecs.BOM_UTF16_LE)
f.write(model.format(i).encode("utf-16le"))
print(i)
这里有几个注意的地方
1.用notepad++打开源文件,发现源文件使用的是CrLf格式(windows)的换行符,而python中多行文本换行符为Lf,所以用’\r\n’来替换’\n’,把换行符替换为CrLf
2.还是notepad++,发现源文件格式居然是。。usc-2 (即utf16) little endian编码,而且还带BOM。。。。。。
3.为了避免解析上的问题,我们需要先将文本编码为utf16-le格式。然后在前面加上utf16-le的BOM(codecs模块提供)。因为BOM是二进制的,所以我们也使用二进制写入模式’wb’打开文件,这样正文文本就需要encode为字节流才行。
然后执行代码,得到生成的xsh文件,粘贴到原来xshell会话存储的地方
点击xshell的会话列表即自动刷新














 958
958











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









