







1、Hive架构
1.1、架构图

1.1.1、用户接口
包括shell命令,JDBC/ODBC和webUi
1.1.2、解析器
根据sql语法匹配出相对应的mapreduce模板
1.1.3、元数据库接口
存储表中的元数据信息在mysql中,表明,列名,分区,表的属性,表数据所存的目录
1.2、存储层
mysql:存储hive的元数据;
hive表中的数据都是保存的HDFS上,也就是说hive中的数据库、表、分区等都可以在HDFS找到对应的文件;
元数据可以理解成hive中用于保存数据库、表、分区或者表字段等基本属性,以及这些属性与HDFS文件对应关系的一个映射。
HDFS:存储hive的数据。
Hive和MySQL之间通过MetaStore服务交互
1.3、计算层
MapReduce:hive的执行器
spark:hive on spark的执行器。
1.4、调度层
yarn:hive的调度器,通常采用容量调度器
1.5、作业提交层
Hive是最上层,即客户端层或者作业提交层。
1.6、hive的运行机制
(1)查询语句提交给hive;
(2)hive利用解析器,优化器,执行器,调用mapreduce模板,形成查询计划存储在HDFS中;
(3)mapreduce程序调用查询计划,提交job给yarn;
(4)通过HDFS和mysql查询所需数据。
2、hiveql基础
(1)HDFS的存储格式:
/user/hive/warehose/log/201801/03/dept.log
(2)分区表的存储格式:
/user/hive/warehose/dept_partition2/**month=201801/day=01**/dept.log;
2.1、数据类型
| INT | 4字节 | 有符号整型 |
|---|---|---|
| BIGINT | 8字节 | 有符号整型 |
| FLOAT | 4字节 | 有符号单精度浮点数 |
| DOUBLE | 8字节 | 有符号双精度浮点数(only available starting with Hive 2.2.0) |
| TIMESTAMP | – | 时间戳,内容格式:yyyy-mm-dd hh:mm:ss[.f…](Only available starting with Hive 0.8.0) |
|---|---|---|
| DATE | – | 日期,内容格式:YYYYMMDD(Only available starting with Hive 0.12.0) |
| STRING | – | 字符串 |
|---|---|---|
| VARCHAR | 字符数范围1 - 65535 | 长度不定字符串(Only available starting with Hive 0.12.0) |
| CHAR | 最大的字符数:255 | 长度固定字符串(Only available starting with Hive 0.13.0) |
| ARRAY | – | 包含同类型元素的数组,索引从0开始 ARRAY<data_type>(negative values and non-constant expressions are allowed as of Hive 0.14.) |
|---|---|---|
| MAP | – | 字典 MAP<primitive_type, data_type>(negative values and non-constant expressions are allowed as of Hive 0.14.) |
| STRUCT | – | 结构体 STRUCT<col_name : data_type [COMMENT col_comment], …> |
2.2、内部表和外部表
未被external修饰的是内部表(managed table),被external修饰的为外部表(external table);
区别 :
1>:内部表数据由Hive自身管理,外部表数据由HDFS管理;
2>:删除内部表会直接删除元数据(metadata)及存储数据;删除外部表仅仅会删除元数据,HDFS上的文件并不会被删除;
- 内部表和外部表的应用场景
在公司中绝大多数场景都是外部表。
自己使用的临时表,才会创建内部表;
2.3、分区和分桶的区别
(1)分区
在逻辑上分区表与未分区表没有区别,在物理上分区表会将数据按照分区键的列值存储在表目录的子目录中,目录名=“分区键=键值”。其中需要注意的是分区键的值不一定要基于表的某一列(字段),它可以指定任意值,只要查询的时候指定相应的分区键来查询即可。我们可以对分区进行添加、删除、重命名、清空等操作。因为分区在特定的区域(子目录)下检索数据,减少扫描成本。
将数据按照分区字段拆分存储的表,在hdfs中以文件夹的形式分别存放不同分区的数据,可以避免全表查询,提高查询效率
Hive(Inceptor)分区又分为单值分区、范围分区。单值分区又分为静态分区和动态分区。我们先看下分区长啥样。如下,假如有一张表名为persionrank表,记录每个人的评级,有id、name、score字段。我们便可以创建分区rank(注意rank不是表中的列,我们可以把它当做虚拟列),并将相应数据导入指定分区(将数据插入指定目录)。

(2)分桶
分桶是指定分桶表的某一列,让该列数据按照哈希取模的方式随机、均匀地分发到各个桶文件中。因为分桶操作需要根据某一列具体数据来进行哈希取模操作,故指定的分桶列必须基于表中的某一列(字段)。因为分桶改变了数据的存储方式,它会把哈希取模相同或者在某一区间的数据行放在同一个桶文件中。如此一来便可提高查询效率,如:我们要对两张在同一列上进行了分桶操作的表进行JOIN操作的时候,只需要对保存相同列值的桶进行JOIN操作即可。同时分桶也能让取样(Sampling)更高效。
分桶表根据分桶字段hash值分组拆分数据的表,在hdfs表现为将单个的数据文件拆分为多个文件;
Hive也是 针对某一列进行桶的组织。Hive采用对列值哈希,然后除以桶的个数求余的方式决定该条记录存放在哪个桶当中。
总结:
分区字段的每个值都对应一个文件夹和分区文件,而分桶字段则是多个值对应一个桶文件;
如果同时使用分区和分桶,则会先按照分区划分文件,再对每个文件按照分桶进行拆分;
2.4、hive支持的存储格式和压缩方式介绍和对比
TextFile : 每一行都是一条记录,每行都以换行符(\ n)结尾。数据不做压缩,磁盘开销大,数据解析开销大。可结合Gzip、Bzip2使用(系统自动检查,执行查询时自动解压),但使用这种方式,hive不会对数据进行切分,从而无法对数据进行并行操作。
SequenceFile : 是Hadoop API提供的一种二进制文件支持,其具有使用方便、可分割、可压缩的特点。支持三种压缩选择:NONE, RECORD, BLOCK。 Record压缩率低,一般建议使用BLOCK压缩。
RCFile : 是一种行列存储相结合的存储方式。首先,其将数据按行分块,保证同一个record在一个块上,避免读一个记录需要读取多个block。其次,块数据列式存储,有利于数据压缩和快速的列存取。
ORCFile : ORC文件格式提供了一种将数据存储在Hive表中的高效方法。这个文件系统实际上是为了克服其他Hive文件格式的限制而设计的。Hive从大型表读取,写入和处理数据时,使用ORC文件可以提高性能。
Parquet : 一个面向列的二进制文件格式。Parquet对于大型查询的类型是高效的。对于扫描特定表格中的特定列的查询,Parquet特别有用。
| 存储格式 | 存储方式 | 特点 |
|---|---|---|
| TextFile | 行存储 | 存储空间消耗比较大,并且压缩的text 无法分割和合并 查询的效率最低,可以直接存储,加载数据的速度最高 |
| SequenceFile | 行存储 | 存储空间消耗最大,压缩的文件可以分割和合并 查询效率高,需要通过text文件转化来加载 |
| RCFile | 数据按行分块 每块按照列存储 | 存储空间最小,查询的效率最高 ,需要通过text文件转化来加载,加载的速度最低。压缩快 快速列存取。读记录尽量涉及到的block最少,读取需要的列只需要读取每个row group 的头部定义。 读取全量数据的操作 性能可能比sequencefile没有明显的优势 |
| ORCFile | 数据按行分块 每块按照列存储 | 压缩快,快速列存取 ,效率比rcfile高,是rcfile的改良版本 |
| Parquet | 列存储 | 相对于ORC,Parquet压缩比较低,查询效率较低,不支持update、insert和ACID.但是Parquet支持Impala查询引擎 |
1、压缩比:压缩比越高,压缩后文件越小,所以压缩比越高越好
2、压缩时间:越快越好
3、已经压缩的格式文件是否可以再分割:可以分割的格式允许单一文件由多个Mapper程序处理,可以更好的并行化
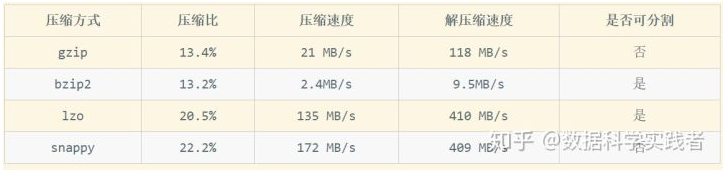
hive一般使用orc作为存储格式,使用snappy作为压缩方式
2.5、窗口函数
2.5.1、累加问题
sum(col)over(partition by col1 order by col2)
count(col)over(partition by col1 order by col2)
avg(col)over(partition by col1 order by col2)
max(col)over(partition by col1 order by col2)
min(col)over(partition by col1 order by col2)
2.5.2、排序问题
row_number()over(partition by col1 order by col2)
rank()over(partition by col1 order by col2)
dense_rank()over(partition by col1 order by col2)
2.5.3、获取其它行的值
lag(col,number)over(partition by col1 order by col2)
lead(col,number)over(partition by col1 order by col2)
2.6、排序问题
2.6.1、order by
order by会对输入的数据做全局排序,因此只有一个reducer,数据规模较大时,耗费时间较长;
order by跟数据库中的order by功能一致,按照某一项或几项排序输出。

**2.6.2、**Sort by
数据进入reducer完成排序,sort by的数据只能保证在同一reduce中的数据可以按指定字段排序,不保证全局有序
使用sort by你可以指定执行的reduce个数(set mapred.reduce.tasks=n)

2.6.3、distribute by
类似MR中的partition,进行分区,是控制在map段如何拆分数据给reduce端的,hive会根据distribute by 后面的列,对应reduce的个数进行分发(即有几个不同的字段,就会有对应个数的reduce进行处理),默认采用hash算法,结合sort by进行使用。
注:Distribute by和sort by的使用场景
1.Map输出的文件大小不均。
maptask输出不均匀,可能会造成部分reducetask处理数据量较大,造成数据倾斜;
2.Reduce输出文件大小不均。
3.小文件过多。
4.文件超大。
将文件根据对应key值拆分为不同的区,将由不同的reduce进行处理;
2.6.4、Cluster by
Cluster by除了具有distribute by的功能外还兼具sort by的功能。但是排序只能是倒序排序,不能指定排序规则为ASC或者DESC。
Cluster by等价于Distribute by和sort by字段相同时

2.6.5、生产环境的应用场景
在生产环境中Order By用的比较少,容易导致OOM。
在生产环境中Sort By + Distrbute By用的多。
2.7、常用函数
2.7.1、split()[]


2.7.2、str_to_map()
使用两个分隔符将文本拆分为键值对。 Delimiter1将文本分成K-V对,Delimiter2分割每个K-V对。对于delimiter1默认分隔符是’,’,对于delimiter2默认分隔符是’=’。


2.7.3、coalesce(a1,a2,…,an)
返回a1,a2,…,an中遇到的第一个不为NULL的值
















 1578
1578











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











