







1、模拟生成数据
(1)在hadoop102上创建目录
[atguigu@hadoop102 module]$ mkdir data_make
cd data_make/
(2)上传数据生成脚本
rz
gmall2020-mock-log-2020-12-18.jar
application.yml

(3)启动脚本
java -jar gmall2020-mock-log-2020-12-18.jar
- 运行结果

2、模拟数据分发
(1)SpringBoot概述(写数据接口)
- Controller:拦截用户请求,调用service,响应请求
- Service:调用DAO,加工数据
- DAO(Mapper):获取数据
- 持久化层:存储数据
(2)快速搭建SpringBoot
①下载Lombok插件(file–>settings–>Plugins)

②创建空的父工程

③创建module,使用SpringBoot模板(File–>new–>module–>Spring Initializr)
国内地址:https://start.aliyun.com

(3)module配置

(4)配置相关依赖
- 开发工具:Lombok
- Web:Spring Web
- 消息:Springffor Apache Kafka

3、本地测试
(1)创建Controller目录,编写代码
package com.lhw.gmalllogger.controller;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
@RestController
public class LoggerController {
@RequestMapping("applog")
public String getLoogger(@RequestParam("param") String jsonStr){
//打印数据
System.out.println(jsonStr);
return "success";
}
}
(2)开启服务端
- 运行IDEA,开启服务端

(3)修改数据文件
- 将mock.url修改为本地ip(CMD后ipconfig可见)
vim application.yml
#修改如下
mock.url: "http://x.x.x.x:8080/applog"
(4)启动数据生成jar包
java -jar gmall2020-mock-log-2020-12-18.jar
- IDEA运行结果

4、SpringBoot整合kafka&本地落盘
(1)修改配置文件application.yml
server:
port: 8081
logging:
config: classpath:logback.xml
spring:
kafka:
bootstrap-servers: 192.168.6.102:9092,192.168.6.103:9092,192.168.6.104:9092
# 配置生产者
producer:
# 消息重发的次数
retries: 3
# 一个批次可以使用的内存大小
batch-size: 16384
# 设置生产者内存缓冲区的大小
buffer-memory: 33554432
# 键的序列化方式
key-serializer: org.apache.kafka.common.serialization.StringSerializer
# 值的序列化方式
value-serializer: org.apache.kafka.common.serialization.StringSerializer
# acks: all
# 配置消费者
consumer:
# 自动提交的时间间隔,在SpringBoot2.x版本是值的类型为Duration,需要付恶化特定的格式,如1S,1M,1H,1D
auto-commit-interval: 1S
# 指定了消费者在读取一个没有偏移量的分区或者偏移量无效的情况下该做如何处理
auto-offset-reset: earliest
# 是否自动提交偏移量,默认值是ture,为了避免出现重复数据,可以把它设置为false,然后手动提交偏移量
enable-auto-commit: false
# 键的反序列化方式
key-serializer: org.apache.kafka.common.serialization.StringDeSerializer
# 值的反序列化方式
value-serializer: org.apache.kafka.common.serialization.StringDeSerializer
listener:
# 手工ack,调用ack后立刻提交offset
ack-mode: manual_immediate
# 容器运行的线程数
concurrency: 4
(2)新增logback.xml日志文件
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<!--追加到控制台-->
<property name="LOG_HOME" value="e:/logs" />
<appender name="console" class="ch.qos.logback.core.ConsoleAppender">
<encoder>
<pattern>%msg%n</pattern>
</encoder>
</appender>
<!--滚动追加到文件-->
<appender name="rollingFile" class="ch.qos.logback.core.rolling.RollingFileAppender">
<file>${LOG_HOME}/app.log</file>
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<fileNamePattern>${LOG_HOME}/app.%d{yyyy-MM-dd}.log</fileNamePattern>
</rollingPolicy>
<encoder>
<pattern>%msg%n</pattern>
</encoder>
</appender>
<!-- 选择追加器方式:将某一个包下日志单独打印日志 -->
<logger name="com.lhw.gmalllogger.controller.LoggerController"
level="INFO" additivity="false">
<appender-ref ref="rollingFile" />
<appender-ref ref="console" />
</logger>
<!--日志级别-->
<root level="error" additivity="false">
<appender-ref ref="console" />
</root>
</configuration>
(3)修改controller目录下的脚本
package com.lhw.gmalllogger.controller;
import lombok.extern.log4j.Log4j;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
@Slf4j
@RestController
public class LoggerController {
// 1、声明topic
private static final String TOPIC_NAME="ods";
// 2、注入kafka
@Autowired
private KafkaTemplate<String,Object> kafkaTemplate;
// 3、数据传输到本地
@RequestMapping("applog")
public String getLoogger(@RequestParam("param") String jsonStr){
// 3.1、打印数据
System.out.println(jsonStr);
// 3.2、将数据落到本地磁盘
log.info(jsonStr);
// 3.3、将数据写入kafka
kafkaTemplate.send(TOPIC_NAME,jsonStr);
return "success";
}
}
(4)运行测试
- 开启kafka

- 创建topic
bin/kafka-topics.sh --zookeeper hadoop102:2181/kafka --create --replication-factor 3 --partitions 6 --topic ods
- 运行IDEA,启动服务端
- 运行数据生成jar包
java -jar gmall2020-mock-log-2020-12-18.jar
(5)结果查看
- IDEA打印结果查看

- kafka消费消息查看
bin/kafka-console-consumer.sh \--bootstrap-server hadoop102:9092 --topic ods

- 本地磁盘文件查看
(6)打包单机部署
- 修改日志落磁盘目录
<property name="LOG_HOME" value="/opt/data/logs" />
- 打包

- 上传jar包
rz gmall-logger-0.0.1-SNAPSHOT.jar
- 启动服务端的jar包
java -jar gmall-logger.jar
- 修改application.yml
mock.url: "http://hadoop102:8081/applog"
- 启动数据生成jar包
java -jar gmall2020-mock-log-2020-12-18.jar
- 运行结果

5、打包集群部署,并用 Nginx 进行反向代理
(1)将日志采集jar包同步到hadoop103 &hadoop104
xsync gmall-logger.jar
(2)修改数据生成脚本的配置文件
#http模式下,发送的地址
mock.url: "http://hadoop102:80/applog"
(2)启动nginx
sbin/nginx
(3)启动消费者
bin/kafka-console-consumer.sh \--bootstrap-server hadoop102:9092 --topic ods
(4)启动服务端jar包
java -jar gmall-logger.jar

(5)启动数据生成jar包
java -jar gmall2020-mock-log-2020-12-18.jar

(6)数据落盘
分别查看hadoop102&hadoop103&hadoop104的logs文件

(7)数据传输到kafka
查看kafka的日志文件

6、代码运行整理
- 代码路径:/opt/module/data/springboot_source

- 代码运行顺序
#1、开启nginx的反向代理
sbin/nginx
#2、开启kafka的消费者
bin/kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --topic ods_base_log
#3、启动gmall-logger项目
java -jar gmall-logger.jar
#4、启动gmall-mock-logger日志生成数据项目
java -jar gmall2020-mock-log-2020-12-18.jar
- 运行界面
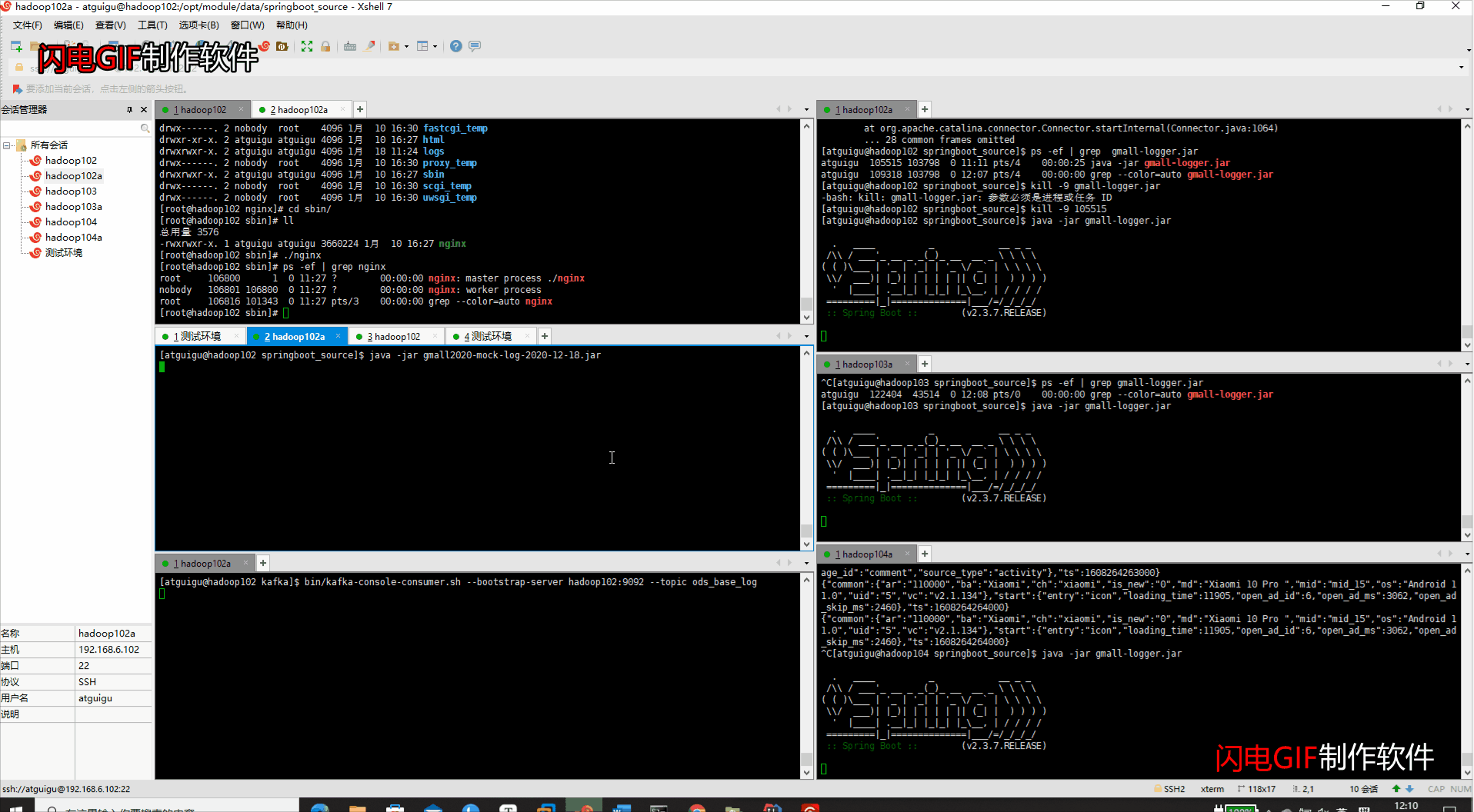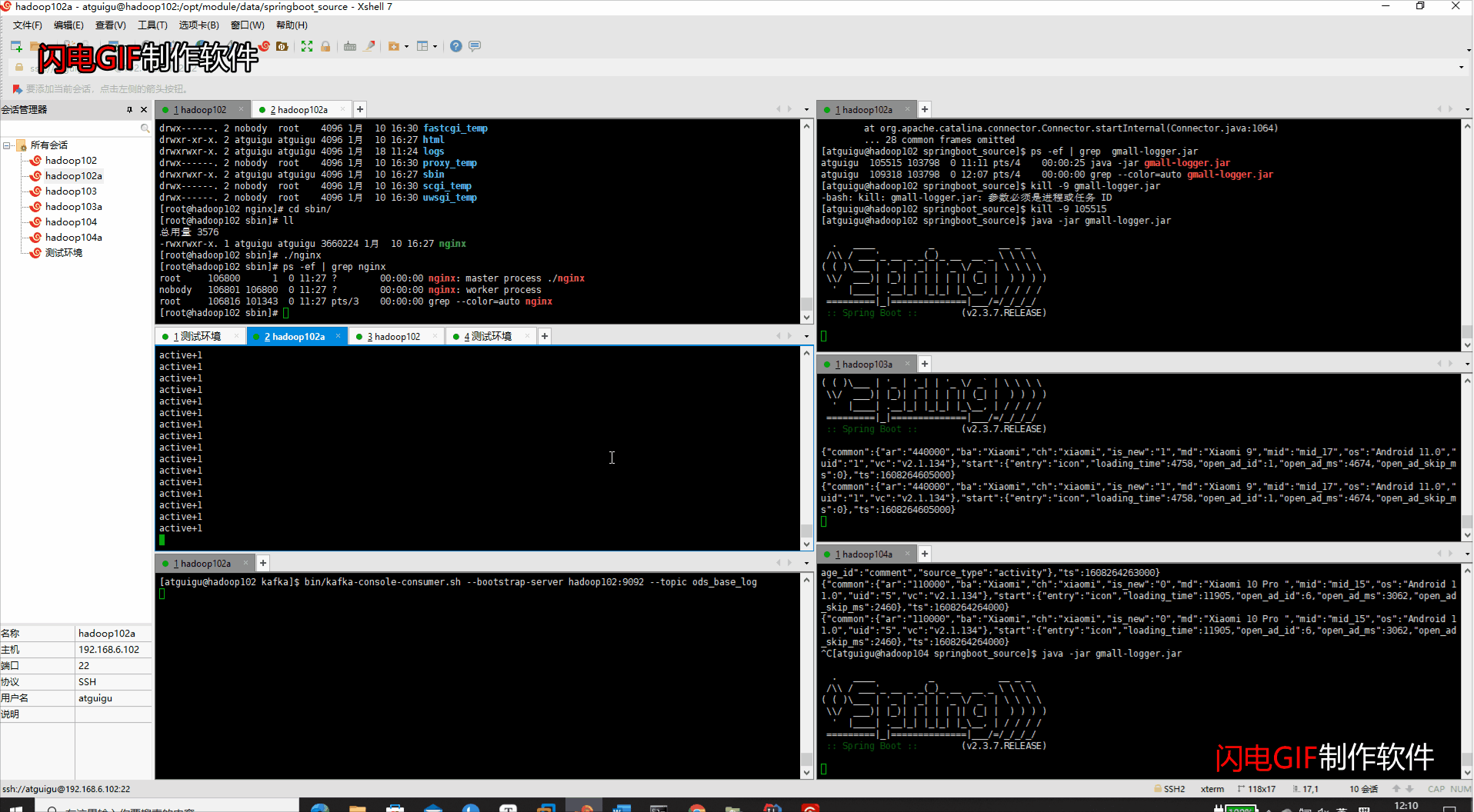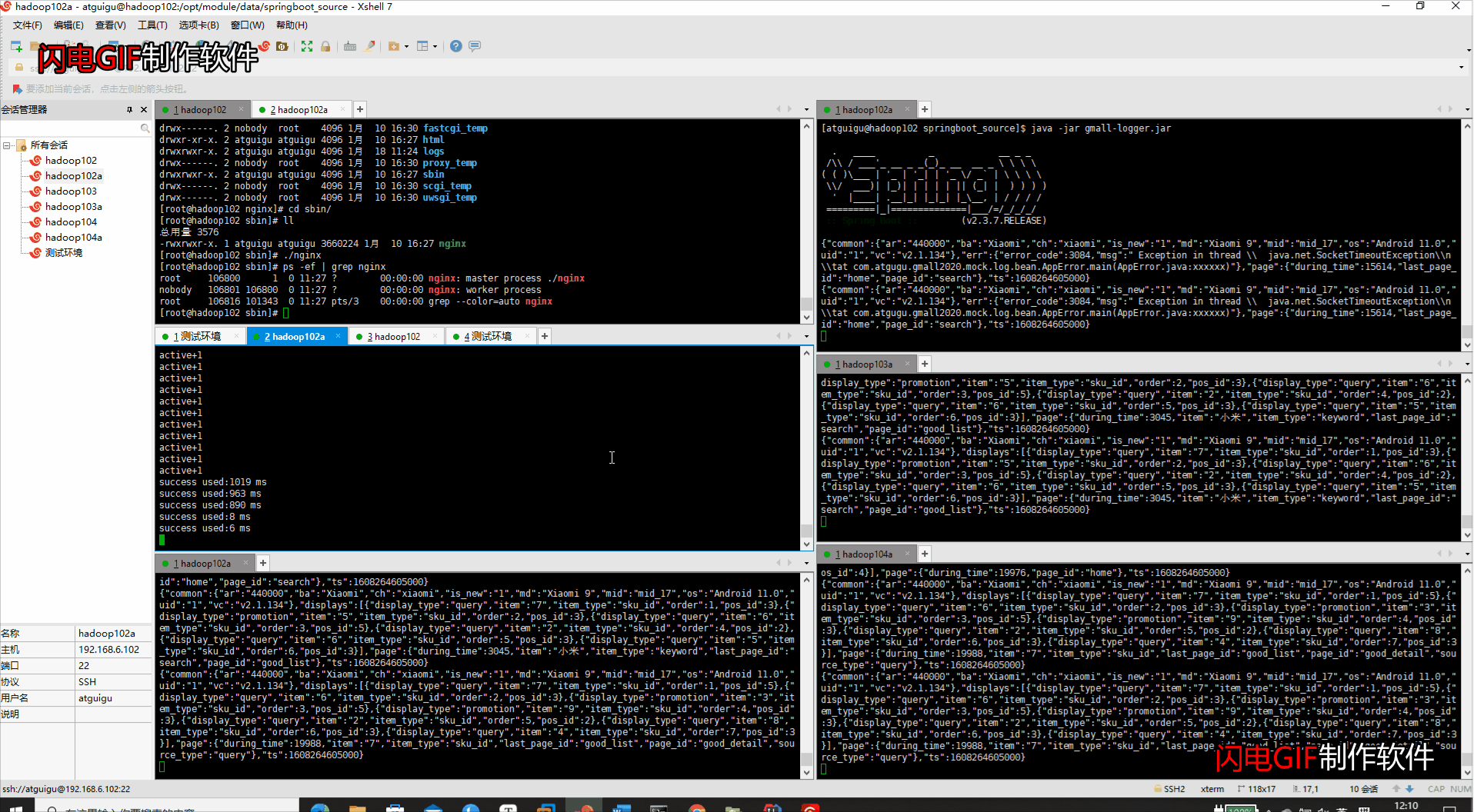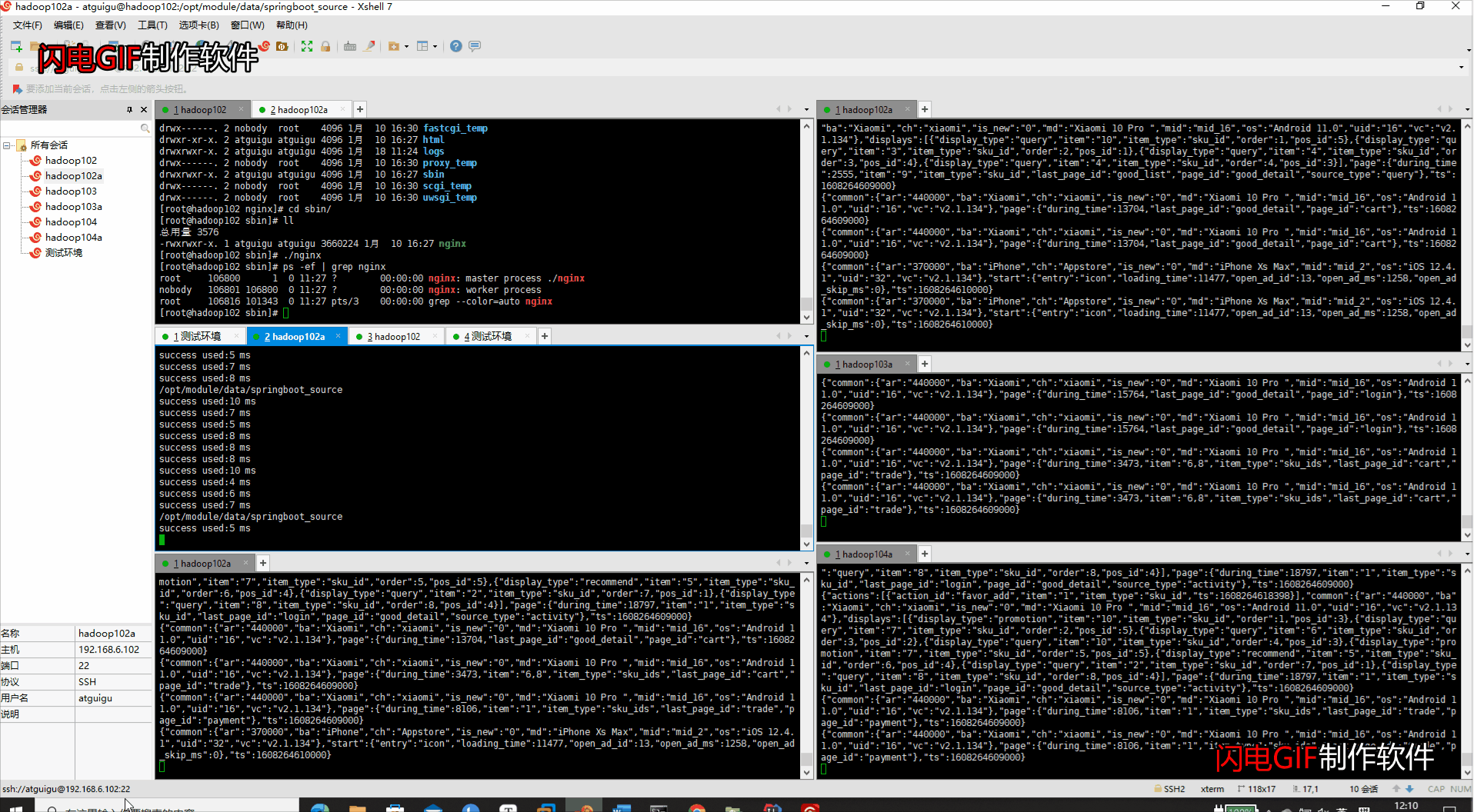
- 注意事项:代码在本地调试时请关闭nginx的端口,否则会报web端口被占用,无法调试
7、代码下载
链接:https://pan.baidu.com/s/1ZTT-NWcJM1MJUAOA7gpC1g
提取码:olu5
















 963
963











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











