







绪、需求说明
- 将源系统mysql表数据全量抽取到hive中作为ODS层,按天分区保留每天的数据,不抽取历史数据
create table T_YYBZB_TGH_BANKINFO
(
id int(8),
bank_id int(8),
bank_name varchar(200),
source_date varchar(200)
);
insert into T_YYBZB_TGH_BANKINFO (ID, BANK_ID, BANK_NAME)values (11, 11, '工商银行(广州)','20210101');
1、创建hive目标表
1.1、编写hive分区表
create table ods.ods_t_yybzb_tgh_bankinfo_di
(
id int,
bank_id int,
bank_name string
)
partitioned by (`pt` string)
row format delimited fields terminated by ',';
1.2、配置SQL组件创建表
- 配置SQL,编写相关建表脚本

1.3、部署上线运行
- 第一步:上线部署

- 第二步:运行调试

1.4、查看运行结果

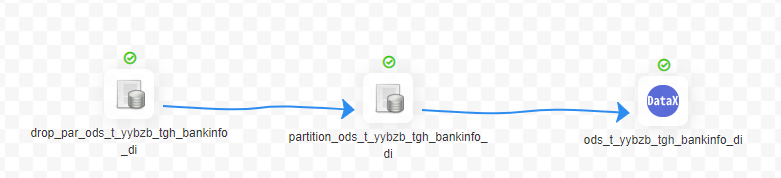
2、创建表分区(按天调度)
2.1、编写SQL脚本
alter table ods.ods_t_yybzb_tgh_bankinfo_di drop if exists partition(p_dt=${pt})
alter table ods.ods_t_yybzb_tgh_bankinfo_di add if not exists partition (pt=${pt})
2.2、配置SQL组件
(1)数据源:ODS
(2)sql类型:非查询
- 删除分区

- 创建分区

(3)参数传递:使用全局时间参数$[yyyyMMdd-1]

3、DataX导入数据
3.1、编写DataX相关Json脚本
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"connection": [
{
"jdbcUrl": [
"jdbc:mysql://${ip}:${port}/${sid}?useSSL=false"],
"querySql": ["select id,bank_id,bank_name from T_YYBZB_TGH_BANKINFO where pt=${p_dt}"],
}
],
"password": "${password}",
"username": "${username}"
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"defaultFS": "hdfs://${hdfs_ip}:${hdfs_port}",
"fileType": "text",
"path": "/user/hive/warehouse/ods.db/ods_t_yybzb_tgh_bankinfo_di/pt=${p_dt}",
"fileName": "ods_t_yybzb_tgh_bankinfo_di",
"column": [
{"name":"id","type":"int"},
{"name":"bank_id","type":"int"},
{"name":"bank_name","type":"string"}
],
"writeMode": "append",
"fieldDelimiter": "\t",
"encoding": "utf-8"
}
}
}],
"setting": {
"speed": {
"channel": "1"
}
}
}
}
3.2、DataX组件配置
(1)自定义模板
(2)参数配置:使用全局参数$[yyyyMMdd-1]

4、设置定时调度
4.1、设置数据链路的定时调度
- 工作流中增加定时,设置为每天6:00整执行

4.2、上线并部署
- 先上线部署,之后设置定时任务

4.3、运行结果
- 运行结果通过工作流实例–>工作流名称查看

















 4146
4146











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











