 Python查询手机号码归属地:BeautifulSoup与phone库方法
Python查询手机号码归属地:BeautifulSoup与phone库方法





 本文介绍了两种使用Python查询手机号码归属地的方法:一是利用BeautifulSoup解析网页[http://www.ip138.com],二是通过Python库phone进行查询。详细步骤包括访问页面、解析信息及保存到Excel。方法一实现实时查询,方法二则更为便捷。
本文介绍了两种使用Python查询手机号码归属地的方法:一是利用BeautifulSoup解析网页[http://www.ip138.com],二是通过Python库phone进行查询。详细步骤包括访问页面、解析信息及保存到Excel。方法一实现实时查询,方法二则更为便捷。
一、使用Python的BeautifulSoup访问[http://www.ip138.com]查询
本方法大致的思路如下:
a)获取页面信息
b)解析返回的页面信息
c)保存查询到的信息到Excel文件
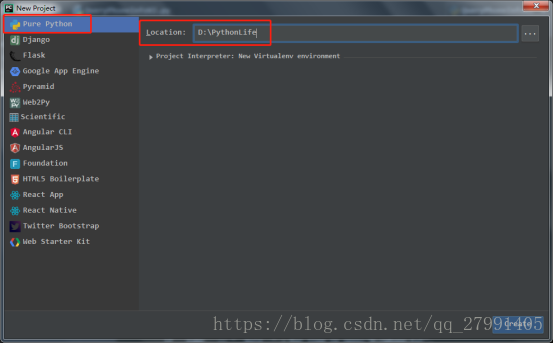
1.新建项目:
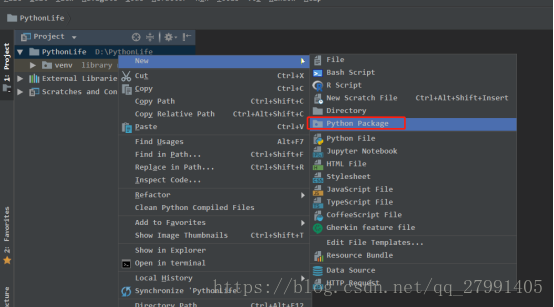
2.新建一个Python package phoneSectionInfo
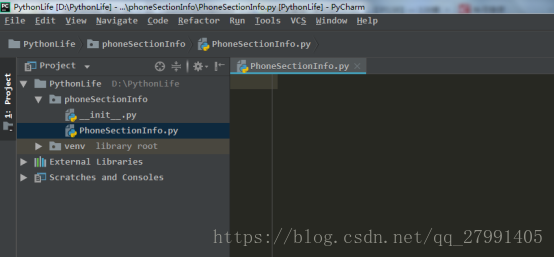
3.新建Python文件 PhoneSectionInfo.py
4.访问页面函数:
# 1.访问页面函数
def getHTMLText(url):
try:
r = requests.get(url)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except Exception as err:
print(err)5.解析页面信息函数:
# 2.解析页面返回的信息
def parsePhoneData(html):
soup = BeautifulSoup(html, "html.parser")
table = soup.find('table',attrs={'style':'border-collapse: collapse'})
phoneInfoList = [] # 用于存放电话信息
for td in table.find_all('td',attrs={'class':'tdc2'}):
rst = td.getText()\
.replace('\xa0','&&')\
.replace(' 测吉凶(新)','')\
.replace(' 更详细的..','')
if '移动' in rst:
rst = '中国移动'
elif '联通' in rst:
rst = '中国联通'
elif '电信' in rst:
rst = '中国电信'
phoneInfoList.append(rst)
return phoneInfoList# 3.保存数据到Excel中
def saveData(datalist,path):
#标题栏背景色
styleBlueBkg = xlwt.easyxf('pattern: pattern solid, fore_colour pale_blue; font: bold on;'); # 80% like
#创建一个工作簿
book=xlwt.Workbook(encoding='utf-8',style_compression=0)
#创建一张表
sheet=book.add_sheet('手机归属地查询',cell_overwrite_ok=True)
#标题栏
titleList=('手机号码段','卡号归属地','卡 类 型','区 号','邮 编')
#设置第一列尺寸
first_col = sheet.col(0)
first_col.width=256*30
#写入标题栏
for i in range(0,5):
sheet.write(0,i,titleList[i], styleBlueBkg)
#写入Phone信息
for i in range(0,len(datalist)):
data=datalist[i]
for j in range(0,len(data)):
sheet.write(i+1,j,data[j])
#保存文件到指定路径
book.save(path)7.测试:
if __name__ == "__main__":
results = [] # 手机号码段信息列表
for line in open("d:/phone_section.txt", "r"):
phoneNum = line.strip(" \t\r\n")
url = "http://www.ip138.com:8080/search.asp?mobile="+phoneNum+"&action=mobile"
html = getHTMLText(url)
result = parsePhoneData(html)
results.append(result)
print(results)
saveDataToExcel(results,'d:/phone_section_result.xls')8.代码汇总:
import requests
from bs4 import BeautifulSoup
import xlwt
# 1.获取网页信息
def getHTMLText(url):
try:
r = requests.get(url)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except Exception as err:
print(err)
# 2.解析页面返回的信息
def parsePhoneData(html):
soup = BeautifulSoup(html, "html.parser")
table = soup.find('table',attrs={'style':'border-collapse: collapse'})
phoneInfoList = [] # 用于存放电话信息
for td in table.find_all('td',attrs={'class':'tdc2'}):
rst = td.getText()\
.replace('\xa0','&&')\
.replace(' 测吉凶(新)','')\
.replace(' 更详细的..','')
if '移动' in rst:
rst = '中国移动'
elif '联通' in rst:
rst = '中国联通'
elif '电信' in rst:
rst = '中国电信'
phoneInfoList.append(rst)
return phoneInfoList
# 3.将查询的信息写入Excel文件
def saveDataToExcel(datalist,path):
#标题栏背景色
styleBlueBkg = xlwt.easyxf('pattern: pattern solid, fore_colour pale_blue; font: bold on;'); # 80% like
#创建一个工作簿
book=xlwt.Workbook(encoding='utf-8',style_compression=0)
#创建一张表
sheet=book.add_sheet('手机归属地查询',cell_overwrite_ok=True)
#标题栏
titleList=('手机号码段','卡号归属地','卡 类 型','区 号','邮 编')
#设置第一列尺寸
first_col = sheet.col(0)
first_col.width=256*30
#写入标题栏
for i in range(0,5):
sheet.write(0,i,titleList[i], styleBlueBkg)
#写入Chat信息
for i in range(0,len(datalist)):
data=datalist[i]
for j in range(0,len(data)):
sheet.write(i+1,j,data[j])
#保存文件到指定路径
book.save(path)
if __name__ == "__main__":
results = [] # 手机号码段信息列表
for line in open("d:/phone_section.txt", "r"):
phoneNum = line.strip(" \t\r\n")
url = "http://www.ip138.com:8080/search.asp?mobile="+phoneNum+"&action=mobile"
html = getHTMLText(url)
result = parsePhoneData(html)
results.append(result)
print(results)
saveDataToExcel(results,'d:/phone_section_result.xls')
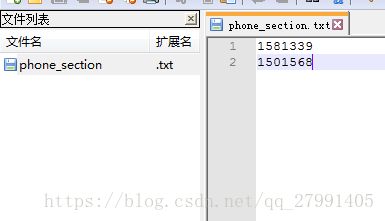
9.相关截图:
phone_section.txt
phone_section_result.xls
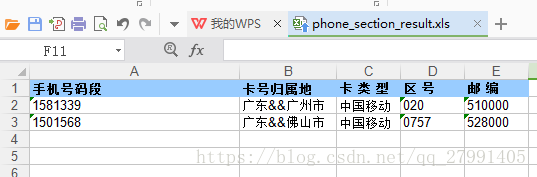
10.方法总结:
该方法实时查询www.ip138.com,性能还行,但有更简单的方法。
二、使用Python lib --> phone(简单粗暴)
import phone
if __name__ == "__main__":
phoneNum = '1581339'
info = phone.Phone().find(phoneNum)
print(info)批量查询并写入Excel文件的可以参加第一种方法
效果图:
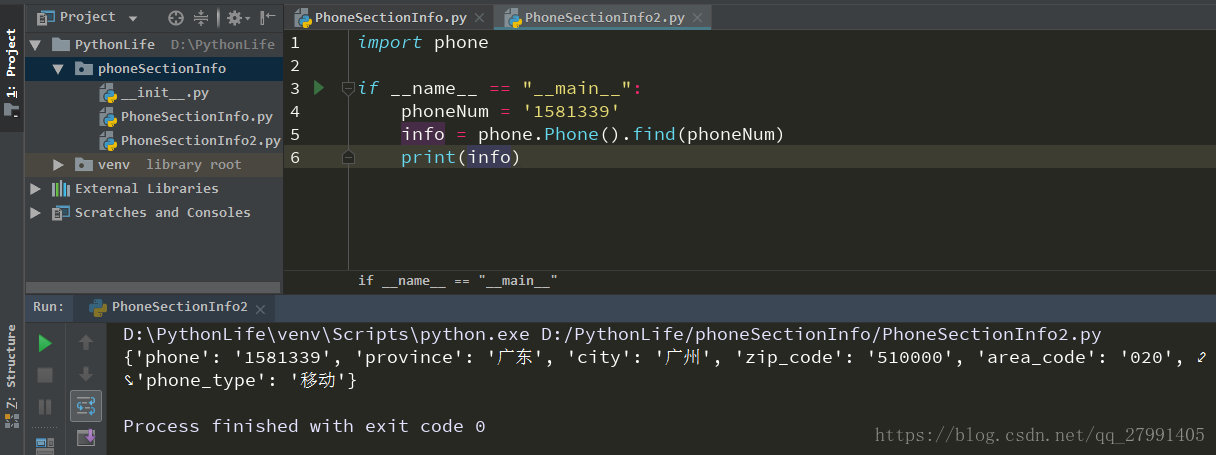

















 2452
2452







 到【灌水乐园】发言
到【灌水乐园】发言







