







一、xlsx的安装
1、使用npm安装
npm install xlsx --save-dev
2、使用yarn安装
yarn add xlsx
二、使用xlsx时遇到的一些问题
1、多表头导出的问题(该问题已经解决)

如上图所示,需要导出带着多表头的表格,在开发当中遇到了数据解析的问题,一开始没有头绪,后来研究了下xlsx的导出数据格式,知道如何实现导出合并单元格的数据格式后,数据解析转换的时候又卡住了,不知道如何把展示报表的表头的数据格式转换成可以导出excel的数据格式
2、单元格样式导出的问题
三、使用xlsx
1、简单的导出代码及数据格式
const XLSX = require('xlsx');
// 索引是从0开始的,比如A1:代表c:0, r: 0, c: 列索引,r:行索引
let merges = [{ s: { c: 1, r: 0 }, e: { c: 1, r: 1 } }];
let headers = {
A1: { v: '项目' },
B1: { v: '查询总数(人次)' },
A2: { v: '项目2' }
};
let data = {
A3: { v: '111' },
A4: { v: '222' },
B3: { v: '1222' },
B4: { v: '33333' }
};
// 合并 headers 和 data
var output = Object.assign({}, headers, data);
// 表格范围,范围越大生成越慢
let ref = 'A1:ZZ100';
// 构建 workbook 对象
var wb = {
SheetNames: ['mySheet'],
Sheets: {
mySheet: Object.assign({}, output, { '!ref': ref, '!merges': merges })
}
};
// 导出 Excel
XLSX.writeFile('报表名称.xlsx');
2、多表头数据解析思路
(1)多表头的数据格式为:

fusion的多表头数据格式为这种树形结构,在配置表头数据的数据也是按照这种格式去定义的;
(2)解析思路:
a、通过递归方式把树形结构的每一层数据都解析出来,如下图所示:
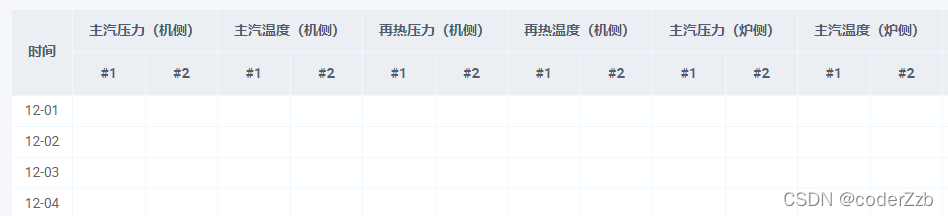
数据解析的话,会把 [时间、主汽压力、主汽温度…]等转换成一列,把 [#1,#2,#3,#1,#2…]转换成一列,里面的参数包含:pid、id、名称
我的数据格式是一个数组,不是树形结构,自己用前端去生成的树结构,解析的时候解析数组,解析代码如下:
const mapTreeData = (treeData, treeDataArr, index, titleList) => {
if (!treeDataArr[index]) {
treeDataArr.push([]);
}
treeData.map((ele, i) => {
const { children } = ele;
if (children && children.length > 0) {
treeDataArr[index].push(ele);
mapTreeData(children, treeDataArr, index + 1, titleList);
} else {
treeDataArr[index].push(ele);
titleList.push(cloneDeepWith(ele));
}
});
return {
treeDataArr: treeDataArr,
titleList: titleList
};
};
b、这里需要解决的一大难点是如何获取每一个表头的合并行数和合并列数,我是通过dom元素获取的,代码如下:
// 先获取表格的顺序和合并行、合并列的个数
let reportContent = document.getElementById(reportContentId);
let tableList = reportContent.getElementsByClassName('next-table-medium');
let groupList = [];
if (tableList && tableList.length > 0) {
// 遍历有多少个表格
for (let i = 0; i < tableList.length; i++) {
// 获取表头的内容
let headerContentList = tableList[i].getElementsByClassName('next-table-header')[0];
let trContentList = headerContentList.getElementsByTagName('tr');
let trLen = trContentList.length;
let trArr = [];
for (let j = 0; j < trLen; j++) {
let thContentList = trContentList[j].getElementsByTagName('th');
let thLen = thContentList.length;
let thArr = [];
for (let k = 0; k < thLen; k++) {
let rowspan = thContentList[k].getAttribute('rowspan') || 1;
let colspan = thContentList[k].getAttribute('colspan') || 1;
thArr.push({
rowspan: parseInt(rowspan),
colspan: parseInt(colspan)
});
}
trArr.push(thArr);
}
groupList.push(trArr);
}
}
因为可能会存在多个表格的情况,所以有了上面的方法
c、对表头进行分组,根据每个分组的数据设置索引、合并行、合并列的数量,代码如下:
let headerGroupObj = _.groupBy(headerListProps, 'groupId');
let titleListObj = {};
let newHeaderGroupObj = {};
let groupIndex = 0;
Object.keys(headerGroupObj).map((groupId) => {
let headerList = headerGroupObj[groupId];
// 把标题数据分组
let headerListTree = BuildAndSortArrayToTree(headerList, 'id', 'pid', 'sort', 0);
// 将树形结构的数据解析成
let arr = []; // 数据列表
var titleList = [];
let index = 0;
let mapTreeDataObj = mapTreeData(headerListTree, arr, index, titleList);
arr = mapTreeDataObj.treeDataArr;
// titleList = mapTreeDataObj.titleList;
// 设置索引
let newArr = [];
arr.map((list, i) => {
let colIndex = 1;
let newList = [];
list = list.map((item, j) => {
const { pid, id } = item;
let { colspan, rowspan } = groupList[groupIndex][i][j];
item.rowIndex = i + 1; // 设置行索引
item.colspan = colspan;
item.rowspan = rowspan;
if (pid == 0) {
item.colIndex = colIndex;
titleList = titleList.map((titleItem) => {
if (titleItem.id === id) {
titleItem.colIndex = colIndex;
}
return titleItem;
});
colIndex = colIndex + colspan;
} else {
// 查找上级节点对应的索引,和该内容所在分组的索引
let parentNode = _.find(newArr[i - 1], { id: pid });
let parentNodeColIndex = parentNode.colIndex;
let curColIndex = 0;
list.map((item2, k) => {
if (item2.pid == pid) {
if (item2.id == id) {
item.colIndex = curColIndex + parentNodeColIndex;
titleList = titleList.map((titleItem) => {
if (titleItem.id === id) {
titleItem.colIndex = curColIndex + parentNodeColIndex;
}
return titleItem;
});
} else {
curColIndex += groupList[groupIndex][i][k].colspan;
}
}
});
}
newList.push(item);
});
newArr.push(newList);
});
newHeaderGroupObj[groupId] = newArr;
titleListObj[groupId] = titleList;
});
d、对解析完成的数据格式化,然后转换成可以导出的数据格式,代码如下:
let colIndexList = getColIndexList();
let headers = {};
let merges = []; // 合并的单元格
let data = {};
let rowIndex = 1;
// 格式化内容
Object.keys(newHeaderGroupObj).map((groupId) => {
let list = newHeaderGroupObj[groupId];
list.map((arr, listIndex) => {
let dataObj = {};
arr.map((item) => {
const { colIndex, colspan, rowspan, title, id } = item;
// 设置表头
let columnId = colIndexList[colIndex - 1] + rowIndex;
headers[columnId] = {
v: title
};
merges.push({
s: { c: colIndex - 1, r: rowIndex - 1 },
e: { c: colIndex + colspan - 2, r: rowIndex + rowspan - 2 }
});
});
if (listIndex == list.length - 1 && dataSource.length > 0) {
// 设置数据
dataSource.map((dataItem, dataItemIndex) => {
rowIndex++;
titleListObj[groupId].map((item) => {
const { colIndex, id } = item;
// 设置表头
let columnId = colIndexList[colIndex - 1] + rowIndex;
data[columnId] = {
v: dataItem[id]
};
});
});
}
rowIndex++;
});
rowIndex++;
rowIndex++;
rowIndex++;
});
e、导出excel,代码如下:
const XLSX = require('xlsx');
// 合并 headers 和 data
var output = Object.assign({}, headers, data);
// 表格范围,范围越大生成越慢
let ref = 'A1:ZZ100';
// 构建 workbook 对象
var wb = {
SheetNames: ['mySheet'],
Sheets: {
mySheet: Object.assign({}, output, { '!ref': ref, '!merges': merges })
}
};
// 导出 Excel
XLSX.writeFile(wb, reportName + '.xlsx');
四、数据格式:
1、headerListProps的数据格式:
{"headerList":[{"title":"时间","id":"e08f58d26b27c2a95783d1bb81c7acad","pid":0,"pids":0,"isHasChild":false,"attrType":"time","attrValue":"","sort":1,"titleWidth":0,"titleType":1,"groupId":"group1","children":[],"timeFormate":"MM-DD"},{"title":"主汽压力(机侧)","id":"dec371ce2ed9e22efbe2d5deb84614ec","pid":0,"pids":0,"isHasChild":false,"attrType":"","attrValue":"","sort":2,"titleWidth":0,"titleType":1,"groupId":"group1","children":[]}]}
2、dataSource的数据格式:
[
{
"e08f58d26b27c2a95783d1bb81c7acad": "2021-12-01",
"dec371ce2ed9e22efbe2d5deb84614ec": "1"
},
{
"e08f58d26b27c2a95783d1bb81c7acad": "2021-12-02",
"dec371ce2ed9e22efbe2d5deb84614ec": "2"
}
]














 4398
4398











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









