










今天遇到一个很神奇的bug
一段描述字段,很长一段,中间有如下的字符

这个是在vim 下看到的
但是在php中打印和使用cat看到的情况如下:


这就很神奇了,所以肉眼看不见
尝试解决办法:str_replace <200b>发现没用。
解决办法:
$value = str_replace("\xe2\x80\x8b", '', $value);
$value = str_replace("\xe2\x80\x8c", '', $value);$value = str_replace("\xe2\x80\x8d", '', $value);
原理:
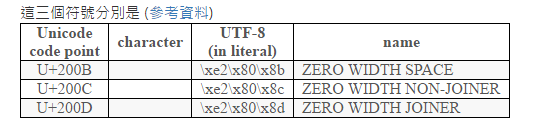
文字说明:
这些字符其实就是排版过程中产生的,而排版使用的规范是Unicode编码标准
扩展阅读:

















 992
992

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









