







上周动手开始学习python写网络爬虫,然而对网络的相关知识了解太少,遂跑去看了《计算机网络(自顶向下方法)》这本书,目前学习到网络层。
但自己觉得对与爬虫的学习帮助不是太大,所以觉得还是看代码逐步学习吧。
爬虫源码地址:
下面是我对代码的注释理解
#!/usr/bin/env python
# -*- coding:utf-8 -*-
"""
一个简单的Python爬虫, 用于抓取豆瓣电影Top前100的电影的名称
Anthor: Andrew Liu
Version: 0.0.1
Date: 2014-12-04
Language: Python2.7.8
Editor: Sublime Text2
Operate: 具体操作请看README.md介绍
"""
import string
import re #正则表达式模块
import urllib2 #HTTP 客户端模块
class DouBanSpider(object) :
"""类的简要说明
本类主要用于抓取豆瓣前100的电影名称
Attributes:
page: 用于表示当前所处的抓取页面
cur_url: 用于表示当前争取抓取页面的url
datas: 存储处理好的抓取到的电影名称
_top_num: 用于记录当前的top号码
"""
def __init__(self) :
self.page = 1
self.cur_url = "http://movie.douban.com/top250?start={page}&filter=&type="
self.datas = []
self._top_num = 1
print "豆瓣电影爬虫准备就绪, 准备爬取数据..."
def get_page(self, cur_page) :
"""
根据当前页码爬取网页HTML
Args:
cur_page: 表示当前所抓取的网站页码
Returns:
返回抓取到整个页面的HTML(unicode编码)
Raises:
URLError:url引发的异常
"""
url = self.cur_url
try :
my_page = urllib2.urlopen(url.format(page = (cur_page - 1) * 25)).read().decode("utf-8")
'''
抓取页面。在原网页代码中可看到页面编码方式为utf-8,此处以改格式解码
每页显示25项
format()函数用于格式化输出字符串
'''
except urllib2.URLError, e : #e中储存错误信息
if hasattr(e, "code"): #检查e中是否有第二个参数中的属性
print "The server couldn't fulfill the request."
print "Error code: %s" % e.code
elif hasattr(e, "reason"):
print "We failed to reach a server. Please check your url and read the Reason"
print "Reason: %s" % e.reason
return my_page #返回html
def find_title(self, my_page) :
"""
通过返回的整个网页HTML, 正则匹配前100的电影名称
Args:
my_page: 传入页面的HTML文本用于正则匹配
"""
temp_data = []
movie_items = re.findall(r'<span.*?class="title">(.*?)</span>', my_page, re.S) #正则表达式查询,第三个参数尚不清楚用法
for index, item in enumerate(movie_items) :
if item.find(" ") == -1 : # 为html中空格表示法
temp_data.append("Top" + str(self._top_num) + " " + item)
self._top_num += 1
self.datas.extend(temp_data)
def start_spider(self) :
"""
爬虫入口, 并控制爬虫抓取页面的范围
"""
while self.page <= 4 :
my_page = self.get_page(self.page)
self.find_title(my_page)
self.page += 1
def main() :
print """
###############################
一个简单的豆瓣电影前100爬虫
Author: Andrew_liu
Version: 0.0.1
Date: 2014-12-04
###############################
"""
my_spider = DouBanSpider()
my_spider.start_spider()
for item in my_spider.datas :
print item
print "豆瓣爬虫爬取结束..."
if __name__ == '__main__':
main()
为了测试format()函数的作用,我添加了一行代码在try后面:
url.format(page = (cur_page - 1) * 25)测试结果:
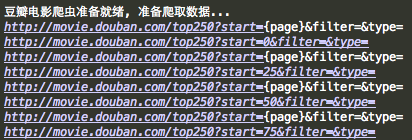
可以看出来format函数把page替换了
更多format函数的用法参考 Python - 格式化(format())输出字符串 详解 及 代码
参考文章:















 3007
3007











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









