







补码表示法
在原码表示的基础上取反然后加1
负数的二进制表示就是对应的正数的补码表示
1)-1:1的原码表示是00000001,取反是11111110,然后再加1,就是11111111。
2)-2:2的原码表示是00000010,取反是11111101,然后再加1,就是11111110。
3)-127:127的原码表示是01111111,取反是10000000,然后再加1,就是10000001。
好处:
- 补码可以逆运算:正数->补码-> 负数->补码->正数
- 利于计算机计算:利用溢出的特性正确做加减法
Java 一些特性
// 二进制常量
// 从 jdk7 开始支持,之前只能写成 16 进制
int a = 0b1101;
int b = 0xff;
// 查看数值的 二进制和 16 进制
Integer.toBinaryString(a);
Long.toHexString(b);
// 位运算
int a = -0b11;
int b = a >> 1;
int c = a >>> 1;
int d = -0b1;
System.out.println(a); //-3
System.out.println(Integer.toBinaryString(a)); //11111111111111111111111111111101
System.out.println(b); //-2
System.out.println(Integer.toBinaryString(b)); //11111111111111111111111111111110
System.out.println(c); //2147483646
System.out.println(d); //-1
十进制和二进制数
整数
辗转相除法
例子:
int:10
10/2=5–0
5/2=2–1
2/2=1–0
1/2=0–1
结果:1010
原理:
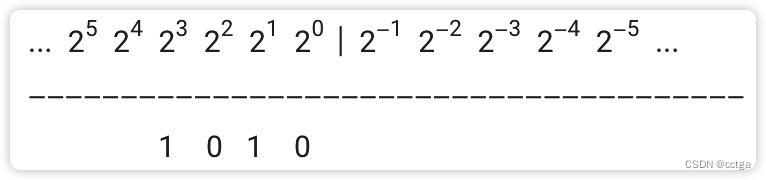
10/2=5–0 查看是否可以完全使用相比于 20 更高位 21 表示,余数为 0 ,表示可以
5/2=2–1 查看是否可以完全使用相比于 21 更高位 22 表示,余数为 1 ,表示去掉一个 21,剩下的可以使用更高位完全表示
2/2=1–0 …
1/2=0–1 一直到全部表示完
小数
类似于 整数 的转化原理,使用辗转相除法
例子:
float:0.3
0.3 / 2-1 = 0.6 – 0 0.3 对于 2-1 来说,并不能获取一个 2-1
0.6 / 2-1 = 0.2 – 1 0.6 对于 2-2 来说,可以获取一个 2-2
为什么变成了 0.6,这就相当于十进制中:12/10 = 1–2,
而对于更低位 1 来说,12/1 = 12–0,相当于扩大了 10 倍,
也可以理解为,低位向高位借位为 10 倍
0.2 / 2-1 = 0.4 – 0
0.4 / 2-1 = 0.8 – 0
0.8 / 2-1 = 0.6 – 1
… 无限循环,直到达到指定精度
原理:
类似于整型的原理,都是看高位是否可以表示,区别在于对于小数而言,最高位在最前面,也就是 2-1 ,所以类似于查看是否可以从目标数中获取一个最高位的数值,例子中就是:0.3 - 2-1 > 0 ?
如果不能获取,则向低位询问,而对于低位而言,值是翻倍的,就像十进制中是翻十倍的,102 是 101 的十倍
就这样一直向更低位询问,直到目标数刚好被取完或是达到指定精度
浮点数和二进制
IEEE 754 国际标准规定浮点数的表示
两种:32 位浮点和 64 位浮点
32 位浮点的位组成位:1+8+23,正负标志位+指数位+有效数位,s+E+M
64 位浮点:1+11+52
转化中需要使用到 整数和小数 转化到二进制的内容
例子 1 :
float:5.0
binary:101.0
科学计数法:1.01 x 2^2
s = 0, E = 2 + 127, M = 010000…用 0 补足 23 位
所以结果为:0 1000,0001 0100,0000,0000,0000,0000,000
例子 2 :
float:-1.125
binary:-1.001
科学计数法:-1.001 x 2^0
s = 1, E = 0 + 127, M = 001000…用 0 补足 23 位
所以结果为:1 0111,1111 0010,0000,0000,0000,0000,000
例子 3 :
double:-1.3
binary:-1.01,0011,0011,0011,… 无限循环 0011
科学计数法:-1.01,0011,0011… x 2^0
s = 1, E = 0 + 1023, M = 01,0011,0011,0011,0011… 循环到补足 52 位
所以结果为: 1 0111,1111,111 01,0011,0011,0011,0011,0011,0011,0011,0011,0011,0011,0011,0011,00
使用代码验证结果为: 1 0111,1111,111 01,0011,0011,0011,0011,0011,0011,0011,0011,0011,0011,0011,0011,01 (发生进位)
以上例子可以使用 Java 代码验证
Integer.toBinaryString(Float.floatToIntBits(value))
Long.toBinaryString(Double.doubleToLongBits(value))
计算机存储
❗️❗️❗️ 计算机中的数据是以字节来存储的,即 8 bit
所以对于 utf-8 中的 英文(UTF-8 兼容 ASCII )来说,不需要考虑存储,一个字节就够了
对于大小端序,只有存储两个字节的情况才要考虑
而对于 utf8 来说,也不需要考虑字节序的问题,因为高位和低位之间无法产生混淆
对于 utf16,utf32 来说,需要考虑字节序
存储地址由小到大增大
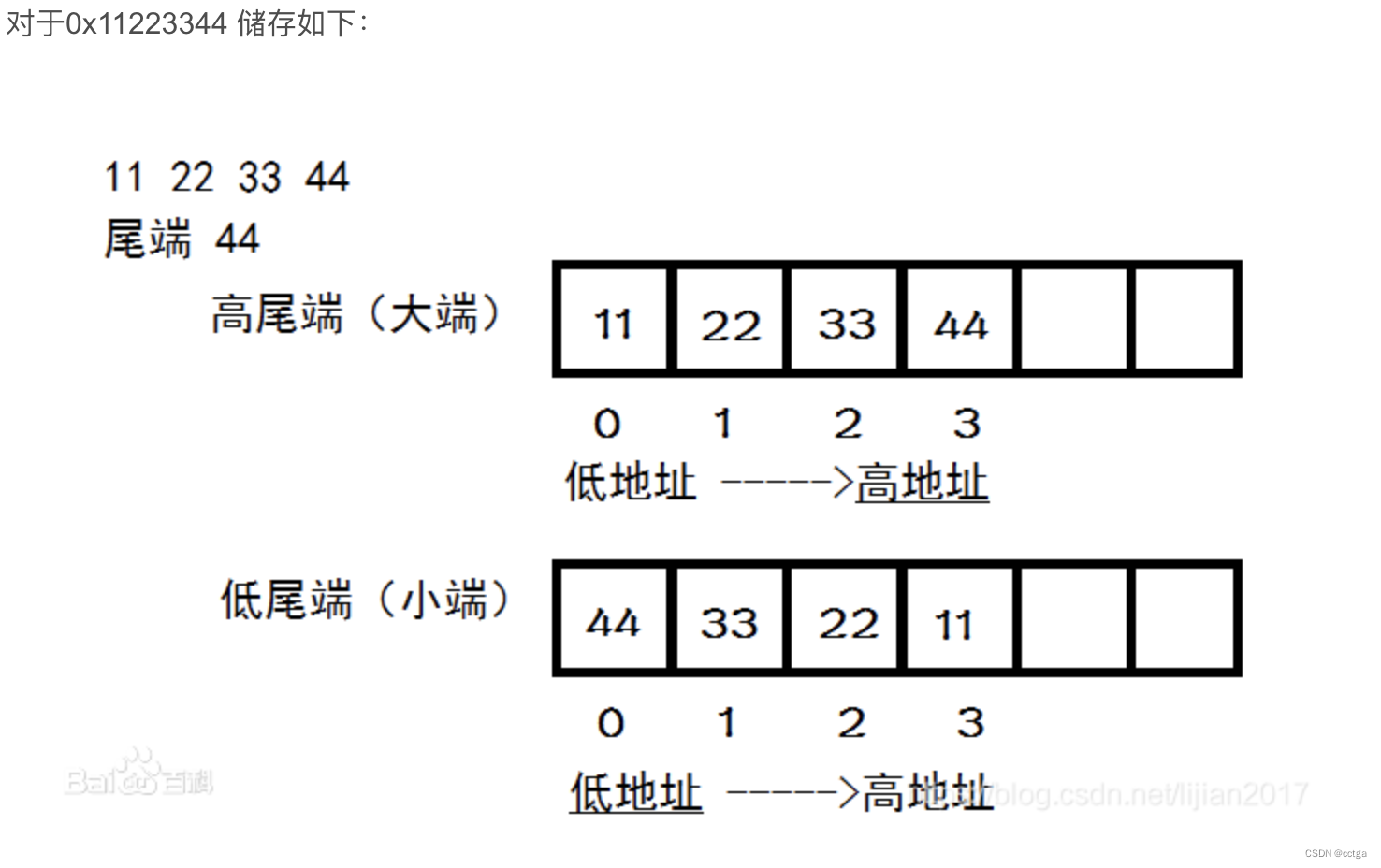
大端:
低位存储于高位,与阅读习惯一致
小端:
低位存储于低位,比较有效率
字符编码
UTF-32 和 UTF-16 存在字节序问题,其他是没有的
UTF-32 和 UTF-16 不兼容 ASCII,其他都是兼容的
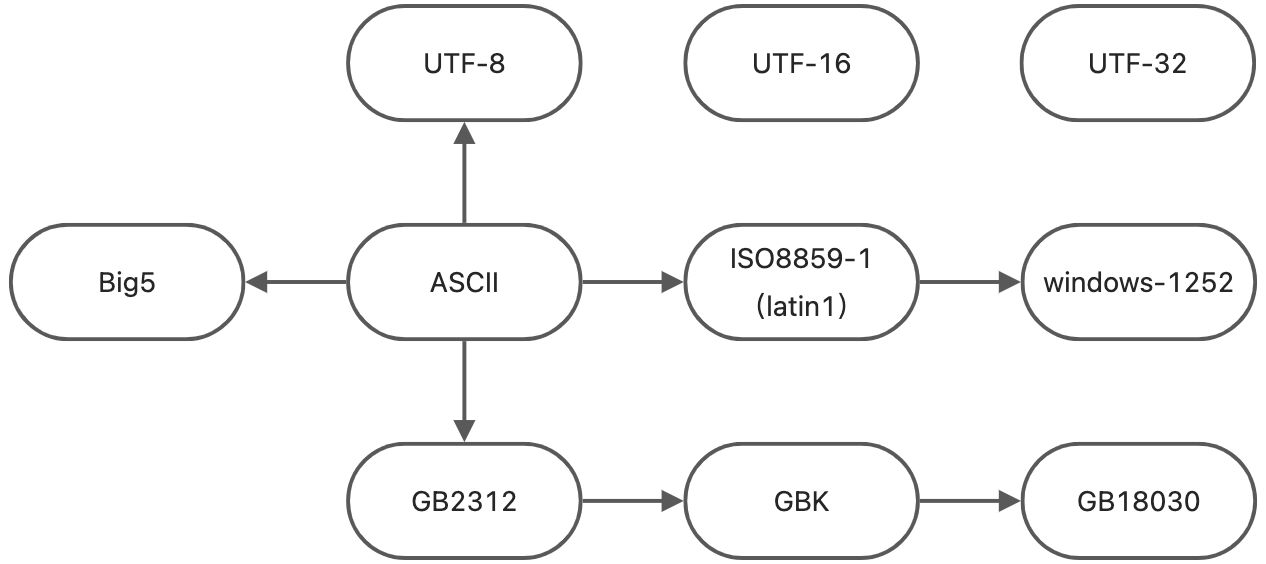
ASCII
长度:一个字节
格式:0xxx xxxx
兼容:GB2312,GBK,GB18030,ISO8859-1(Latin-1),windows-1252
ISO8859-1(latin1)
长度:一个字节
格式:
0xxx xxxx 兼容 ASCII
1xxx xxxx 其他字符,128-159 控制字符,160-255 西欧字符
windows-1252
长度:一个字节
和 ISO8859-1 基本一样,区别在于使用 128-159 中的一些表示打印字符
基本上可以认为,ISO8859-1已被Windows-1252取代,在很多应用程序中,即使文件声明它采用的是ISO 8859-1编码,解析的时候依然被当作Windows-1252编码。
HTML5 甚至明确规定,如果文件声明的是ISO 8859-1编码,它应该被看作Windows-1252编码
GB2312
长度:变长,一个或二个字节
格式:
0xxx xxxx xxxx xxxx 由 0 开头,则是一个 ASCII,第二个字节没有用
1xxx xxxx 1xxx xxxx 两个字节都是 1 开头的
GB2312标准主要针对的是简体中文常见字符,包括约7000个汉字和一些罕用词和繁体字。
GBK
长度:变长,一个或二个字节
格式:
0xxx xxxx xxxx xxxx 由 0 开头,则是一个 ASCII,第二个字节可以省略
1xxx xxxx 0xxx xxxx 低位字节是可以 0 开头的
GBK建立在GB2312的基础上,向下兼容GB2312,也就是说,GB2312编码的字符和二进制表示,在GBK编码里是完全一样的。GBK增加了14 000多个汉字,共计约21 000个汉字,其中包括繁体字。
GB18030
长度:变长,1,2,4 三种长度
长度为 2 的时候就是 GBK
GB18030向下兼容GBK,增加了55 000多个字符,共76 000多个字符,包括了很多少数民族字符,以及中日韩统一字符。
解析二进制时,如何知道是两个字节还是4个字节表示一个字符呢?看第二个字节的范围,如果是0x30~0x39就是4个字节表示,因为两个字节编码中第二个字节都比这个大。
Big5
长度:二个字节
Big5是针对繁体中文的,广泛用于我国台湾地区和我国香港特别行政区等地。Big5包括13 000多个繁体字,和GB2312类似,一个字符同样固定使用两个字节表示。在这两个字节中,高位字节范围是0x81~0xFE,低位字节范围是0x40~0x7E和0xA1~0xFE。
Unicode
统一字符的编码,为每个字符都分配了一个编号,但是没有规定要怎么存储
UTF-32
长度:四个字节
这个最简单,就是 Unicode 字符编号的整数二进制形式,4个字节。
UTF-16
长度:变长,2,4 字节
计算机存储处理效率高,所以计算机内部多使用该编码方式
UTF-8
长度:变长,1,2,3,4 字节
格式:
0xxx xxxx 兼容 ASCII
110x xxxx 10xx xxxx
1110 xxxx 10xx xxxx 10xx xxxx
1111 0xxx 10xx xxxx 10xx xxxx 10xx xxxx 第一个字节表示一共有几个字节
计算机处理效率低,编码费劲,但是节省空间,常用于传输

















 870
870











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











