







 本文探讨了深度学习中的Filter Concatenation概念,通过分析Google的Inception模型,解释了卷积核大小与图像尺寸的关系,并澄清了关于Filter Concatenation的工作原理的常见误解。实际上,Filter Concatenation是将多个图像按深度维度拼接成一个新的图像。
本文探讨了深度学习中的Filter Concatenation概念,通过分析Google的Inception模型,解释了卷积核大小与图像尺寸的关系,并澄清了关于Filter Concatenation的工作原理的常见误解。实际上,Filter Concatenation是将多个图像按深度维度拼接成一个新的图像。
学习深度学习,有几篇论文大多数人都会读到。
其中一篇就是《Going deeper with convolutions》,google在这片论文中提到了一个inception模型(示意版,简单模式):
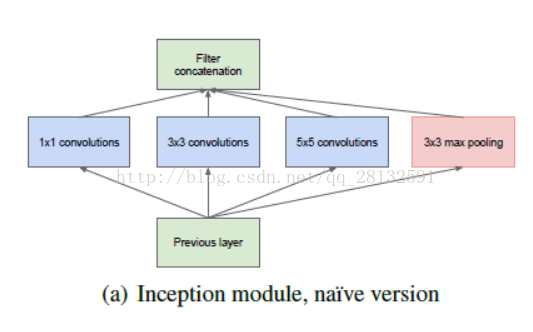
对于我这种基础知识不牢靠,学习时间非常短的人来说,对深度神经网络的理解还没到位,经常看论文一知半解,很多概念搞不清楚。
看到上面这个图,我就产生了一个疑问:
上图中的Filter Concatenation是怎么工作的,明明下面是三个不同大小的核卷积出来的,难道有个Filter Concatenation操作可以把不同大小的图混合在一起?
首先这是我的第一个误解,估计只有很少人会有:
就是在没有特殊说明的情况下卷积后的图像大小只和步长有关和卷积核大小无关,卷积核如果超出边缘会有相应策略填充:
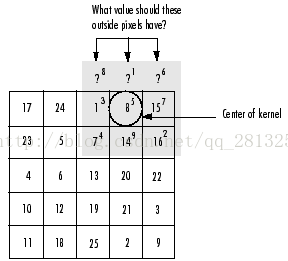
如图 上面超
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1258
1258

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









