







 本文介绍了MongoDB的选举机制,如何在分布式环境中通过Paxos和Raft算法确保高可用性,以及副本集、Priority、Secondary等角色在选举中的作用。讨论了其优点和可能的问题。
本文介绍了MongoDB的选举机制,如何在分布式环境中通过Paxos和Raft算法确保高可用性,以及副本集、Priority、Secondary等角色在选举中的作用。讨论了其优点和可能的问题。
What’s the problem?
今天给大家介绍一下Mongodb的选举机制。首先先明确一个前提,MongoDB是一个“分布式数据库”,一个分布式数据库会有多个节点,节点与节点之间会有通讯。
MongoDB部署分成三种方式:
- 单节点部署(Standalone)。适合测试和开发阶段使用。
- 副本集部署(Replica Sets),也就是传统数据库称呼的主副节点部署(Primary/Replica),由多个Standalone组成,通常是3个。适合生产环境高可用场景。
- 分片集群(Sharded Cluster),由多个Replica Sets组成,每个Replica Sets称为一个Shard。另外添加一个Replica Sets作为Config管理,添加Mongos作为查询路由,Mongos是无状态的。适合大数据计算的生产环境高可用场景。
下图是MongoDB集群的架构图:
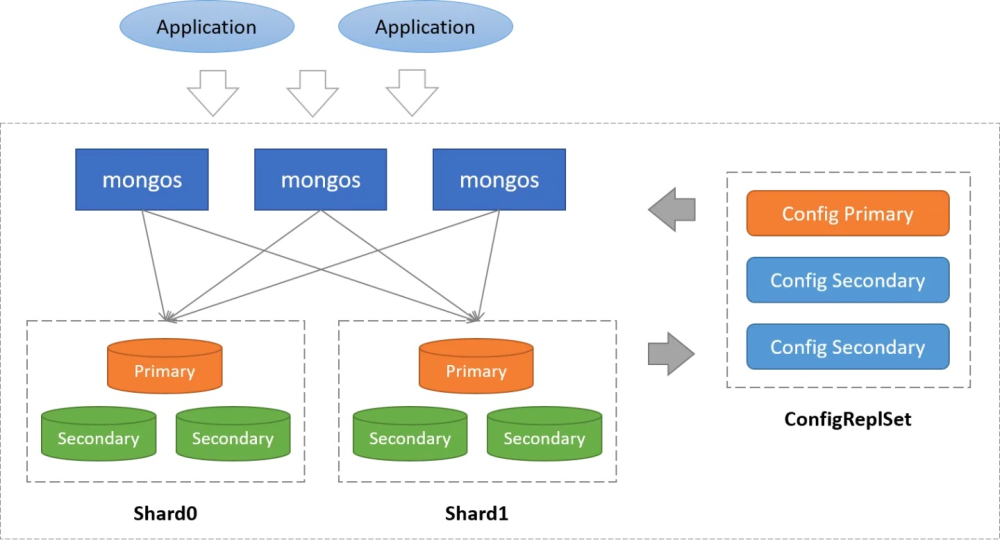
节点会有各种问题,节点与节点之间也会有各种问题,MongoDB需要有一个机制来解决分布式环境下的高可用性问题。
- 节点失效
- 机器宕机
- 进程崩溃
- 网络故障
- 高可用性
- 数据正确性
◆ The Alternative solutions
在分布式行业领域中,解决高可用性的方案有很多,我们一起看看可选方案算法
- Paxos
- Raft: 灵感来自于Paxos算法,更易于理解和实现
- ZAB (ZooKeeper Atomic Broadcast) 协议, 基于Paxos
- Gossip协议: 随机, 速度较慢
- 其它: 基于Paxos或类似
由以上信息我们可以看出来,最初的算法是Paxos,由Paxos衍生或灵感催生出了其他各种算法。那么为什么已经有了Paxos,还会有其他算法产生呢?接着往下看。在这里,有必要对Paxos有一个了解,从而更容易理解MongoDB做出的选择。
◆ Paxos
Paxos算法是莱斯利·兰伯特(英語:Leslie Lamport,LaTeX中的「La」)于1990年提出的一种基于消息传递且具有高度容错特性的共识(consensus)算法。
在Paxos中有三个角色:
- Proposer: 提案者,可以有多个,负责提出议案,也就是需要修改什么值都由该角色提出
- Acceptor: 批准者,有 N 个,N必须大于1。负责对Proposer提出的修改进行审批,超过半数(N/2+1)的Acceptor通过则生效,Acceptor之间完全独立对等。
- Learner: 学习者,学习被批准的结果,当Proposer提出修改Acceptor批准得到结果后,读取数据。
注意:这里的角色是逻辑区分,非物理区分,一个物理进程逻辑意义上既可以是Proposer,也可以是Acceptor,也可以三者都是
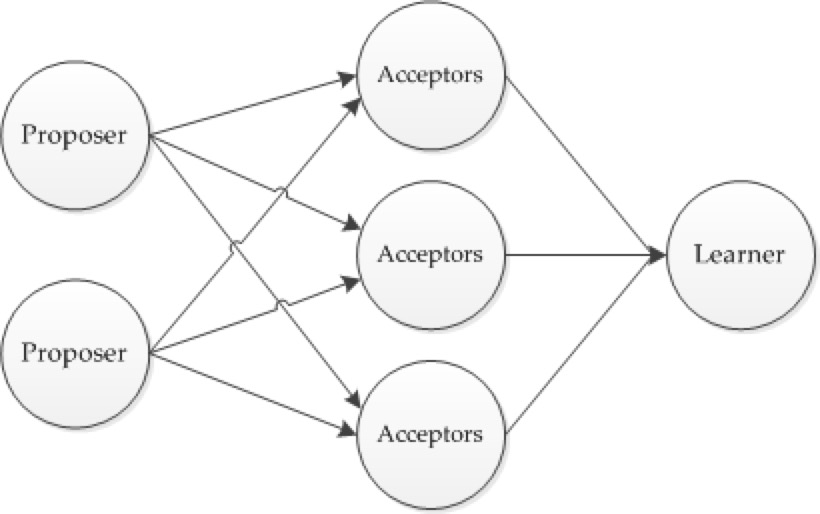
◆ Paxos基本流程
这里简单地做个介绍,了解一下基本的信息,信息来自分布式原理介绍的2.8 Paxos 协议的2.8.2.2 流程描述,详细的基本流程可以自己浏览首先先看一个最简单的例子:5 个 Acceptor,1 个 Proposer,Paxos 协议一轮一轮的进行,每轮都有一个编号。
- Proposer 向所有 Accpetor 发送“Prepare(1)”,Acceptor 如果正确处理,则回复 Promise(1, NULL),否则返回 Reject(B), B>1
- Proposer 收到 Promise(1, NULL)消息达到 N/2+1 (如全部)个,说明批准修改值,于是向所有 Acceptor 广播消息 Accept(1,v1);
- 2.1 如果收到的Reject(B)消息达到 N/2+1 (如全部)个,说明不批准,把轮数改为B+1,回到第1步,进行新一轮申请
- Proposer 如果设置成功,则广播 Accepted 消息。
- 3.1 Proposer收到 Nack(B),消息达到 N/2+1 (如全部)个,将轮数 b 设置为 B+1 后重新步骤 1;
大体流程如下图:
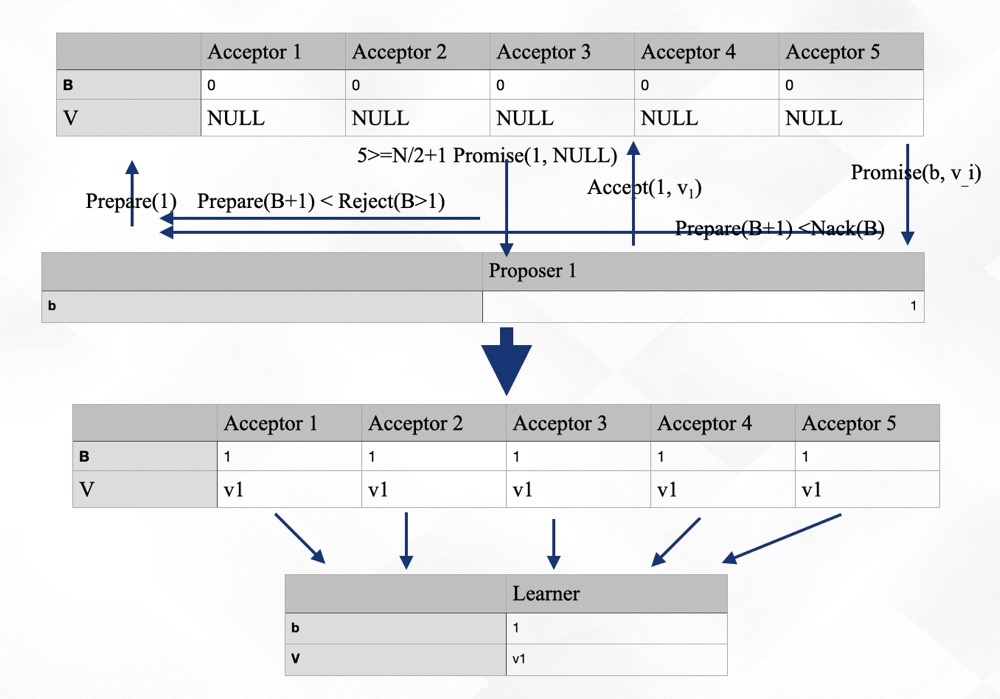
看完上面的介绍,你对Paxos的流程会有一个大体的了解。以上流程为单一法令流程,多法令却复杂到极点。
◆ Best Practice
基于Paxos算法衍生的产品,列举几个如:Chubby,Zookeeper,Megastore下面是Zookeeper简单的算法结构图:
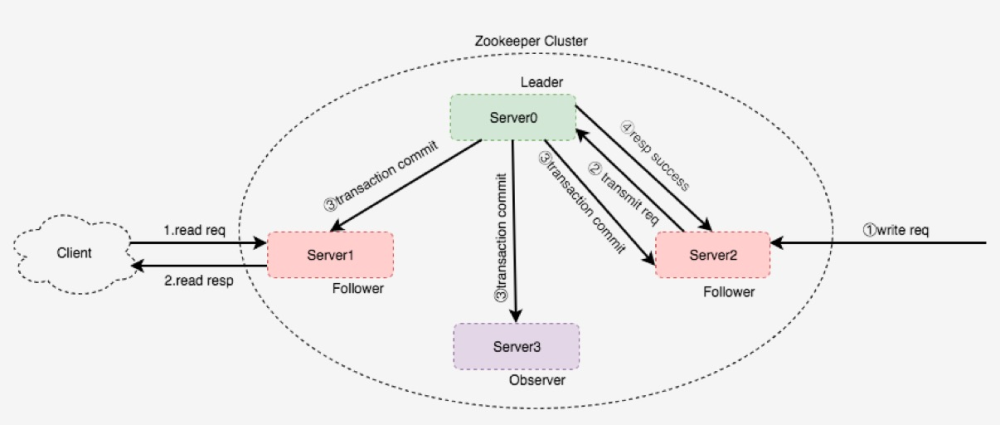
Zookeper 有Leader,Follower,Observer三个角色,它们属于物理角色。与Paxos的逻辑角色对应如下:
- Leader:Proposer, Acceptor,Learner
- Follower:Acceptor,Learner
- Observer:Learner
-
写请求:不管发送到哪个节点,都会将其转发给Leader,由Leader发起Paxos协议申请写数据,这是强一致性的。
-
读请求:在哪个节点都可以读。
◆ Raft
简单了解完Paxos和基于Paxos的修改算法之后,再来了解一下Paxos灵感产生的Raft算法就简单多了。Raft是一种用于替代Paxos的共识算法。相比于Paxos,Raft的目标是提供更清晰的逻辑分工使得算法本身能被更好地理解,同时它安全性更高,并能提供一些额外的特性。它把Paxos拆分成了3个相对独立的子问题:
- Leader election (领导者选举):当现有领导者失败时,必须选择新的领导者
- Log replication (日志复制):领导者必须接受来自客户端的日志条目,并在集群中复制它们,迫使其他日志与自己的日志一致
- Safety(安全操作)
在这里我们抓重点,只讲解1. Leader election
◆ Leader election
选举有三个状态:Follower, Candidate, Leader过程如下:
- 节点启动时是Follower
- 如果发现集群中没有Leader,则转变角色为:Candidate,然后发起选举
- 选举成功,Leader节点定时给所有节点发起心跳,其它节点切换状态为Follower
-
选举比较简单,与Paxos的简单例子比较类似,但是先到先得,完成第1,2后即可完成选举,然后强行推送,没有第3步。
-
需要注意的是这种方式容易出现活锁,比如说每个节点同时选举,都选自己,会大大影响效率,因此Raft使用随机化的选举超时来确保分裂投票。
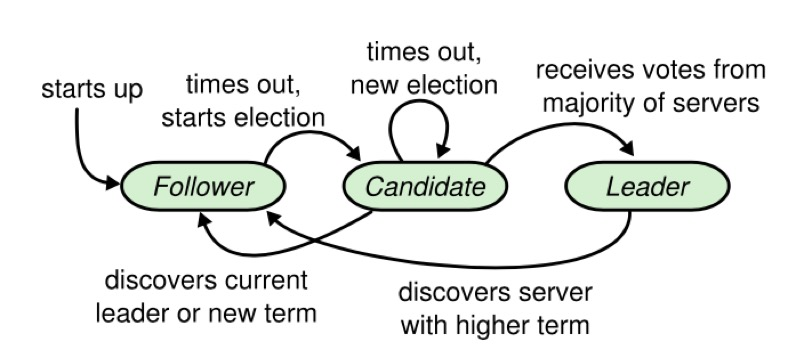
服务器状态。追随者只响应来自其他服务器的请求。如果一个follower没有收到任何通讯,它就成为candidate并发起选举。从整个集群中获得大多数选票的候选人成为新的领导者。领导者通常会一直运作到失败为止。
◆ Leader 任期
值得注意的是,Raft的Leader有一个任期的概念,它不是说每隔一段时间就会进行一次选举。
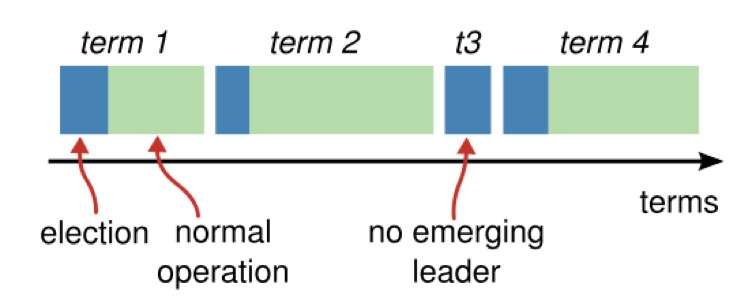
时间被分为多个任期,每个任期都以一次选举开始。在成功的选举后,一个单一的领导者负责管理集群,直到该任期结束。有些选举可能会失败,此时任期会在未选择领导者的情况下结束。不同服务器上可能在不同时间观察到任期之间的过渡。
◆ The Best Solution
了解完以上算法之后,如果要让你从上面的算法中选择一个来实现的话。只要你喜欢把问题简单化,无疑都会选择Raft算法。Raft算法除了选举之外,还有Log replication (日志复制)和Safety(安全操作),这是一个用于管理复制日志的算法,这也是MongoDB需要的特性。最后MongoDB的选择不言而喻:Raft算法附上管理复制日志的算法,MongoDB的日志复制也是基于该算法实现
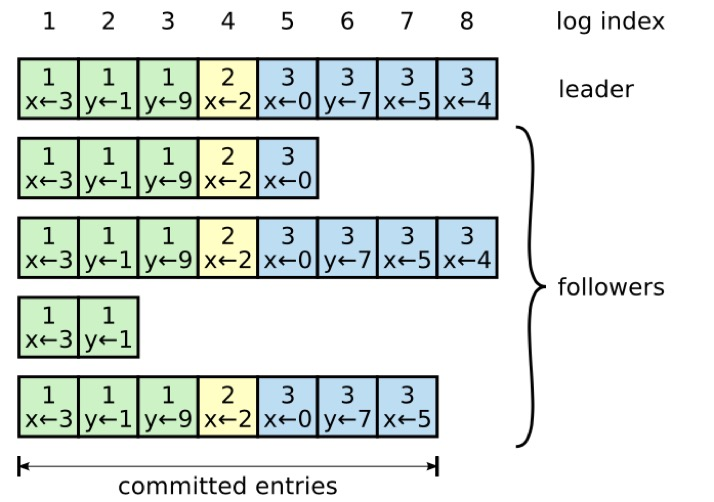
日志由一系列顺序编号的条目组成。每个条目包含创建它的任期(方框中的数字)和用于状态机的命令。如果一个条目可以安全地应用于状态机,则被视为已提交。
◆ MongoDB's election techniques
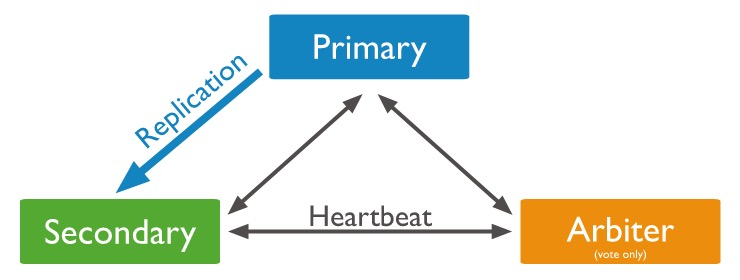
基于Paxos和Raft的知识,再去看MongoDB的选举,就轻松多了。回顾一下MongoDB的部署模式,单节点部署没有高可用,副本集部署是高可用,而分片集群部署是基于副本集做的集群。选举的运行就在副本集上。MongoDB的副本集节点都称为Members,有三个物理角色,先说两个主要物理角色:Priority,Secondary两个物理角色分别对应Raft的逻辑角色:
- Priority:Leader
- Secondary:Follower
Members之间以心跳保证其存活状态,当Secondary在一定时间里收不到Priority的心跳后,按照Raft协议进行新的选举,如下图:
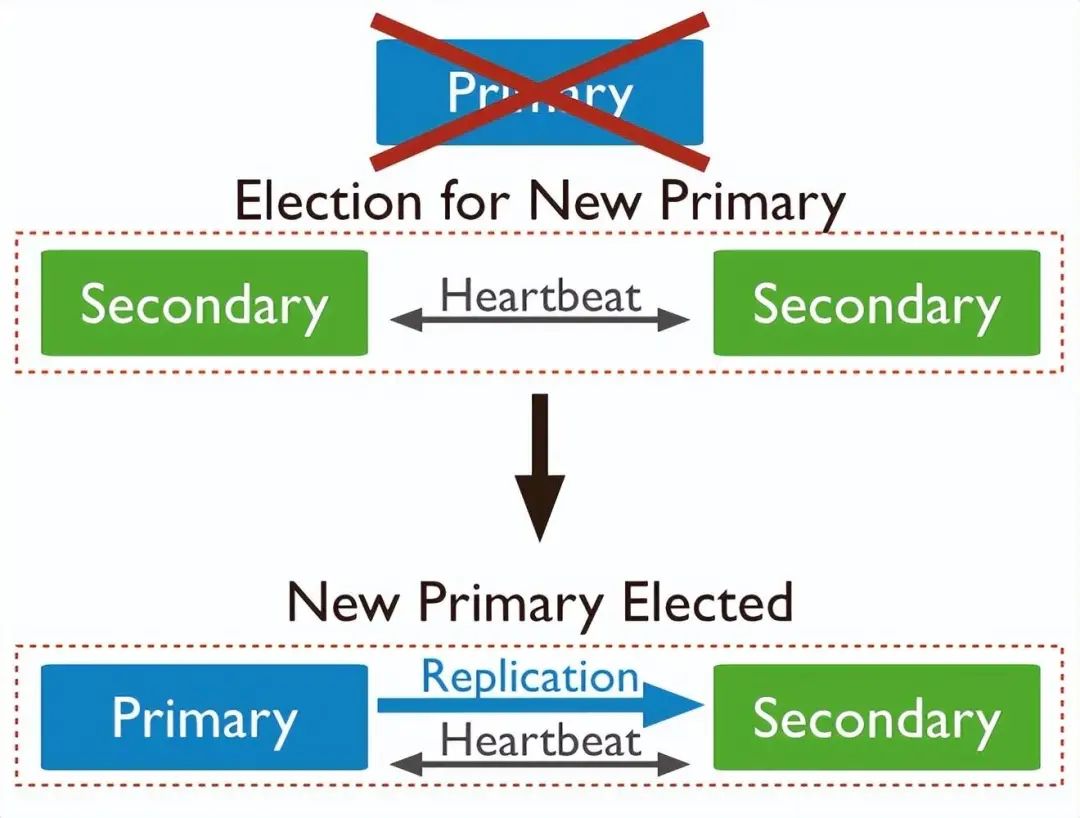
注意:MongoDB在原Raft的随机等待选举的基础上,加上了节点选举优先级的策略,根据优先级加减等待选举时间,以确保优先级高(比如网络更好,延迟更小)的节点有更大可能选举为Priority,优先级在配置里,具体自己产看MongoDB文档。为了确保MongoDB的效率,MongoDB对Members做了些限制,主要有两个:
-
Members个数最多只能有50个
-
参加选举的个数最多7个,可以使用配置的方式进行配置

当副本集的成员只有2个时,如果Priority不可用的话,Secondary节点是选举不出一个Priority的,因为选举出结果需要N/2+1=2个节点通过,这时候集群其实不是高可用的。如果由于硬件原因导致无法满足三个及以上节点运行,MongoDB提供了一个仲裁节点,从而满足高可用的需求。它的角色为Arbiter,它只参与选举的推选,不参与选举和存储事宜。
◆ MongoDB的Raft
细心的读者可能已经发现了,MongoDB的选举虽然算法是Raft,但是它的角色确有多个。甚至可以说,它的逻辑角色分类更像Paxos。
- Priority(Leader):Proposer, Acceptor,Learner
- Secondary Voting Members(Follower):Proposer,Acceptor,Learner
- Secondary Non-Voting Members:Acceptor,Learner
- Arbiter: Acceptor
虽然它的角色分类更像Paxos,实现算法确确实实是Raft,这个勿容质疑。到此,MongoDB的选举内容基本了解清楚。
◆ Pros/Cons
虽然MongoDB的优缺点都众所周知,但是在这里还是有必要提上一提,最近AI比较火爆,问了一下得到下面的答案,还是很中肯的。请看内容
◆ Pros
- 高可用性:MongoDB的选举机制能够确保在主节点宕机或者网络故障等情况下,系统能够快速地自动切换到备用节点,保障了系统的高可用性。
- 可扩展性:由于MongoDB的选举机制支持多个副本集,因此系统具有很好的可扩展性,可以根据实际需要动态地添加或删除副本集节点。
- 可靠性:MongoDB的选举机制使用了基于心跳检测的算法,能够检测到节点的健康状况,确保了系统的可靠性。
◆ Cons
- 延迟问题:当主节点宕机时,备用节点需要进行选举,可能会出现一段时间的延迟,这可能会导致系统性能下降。
- 一致性问题:由于MongoDB的选举机制是基于心跳检测的算法,存在一定的误判概率,可能会导致副本集中的数据不一致。
- 可靠性问题:当集群规模较大时,由于选举机制本身的复杂性,可能会导致选举过程不够稳定,出现节点频繁切换等问题。

















 7508
7508

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









