







概述
本文研究背景是法律专业人员常用的演绎推理方法,即法律演绎,用于案例分析。
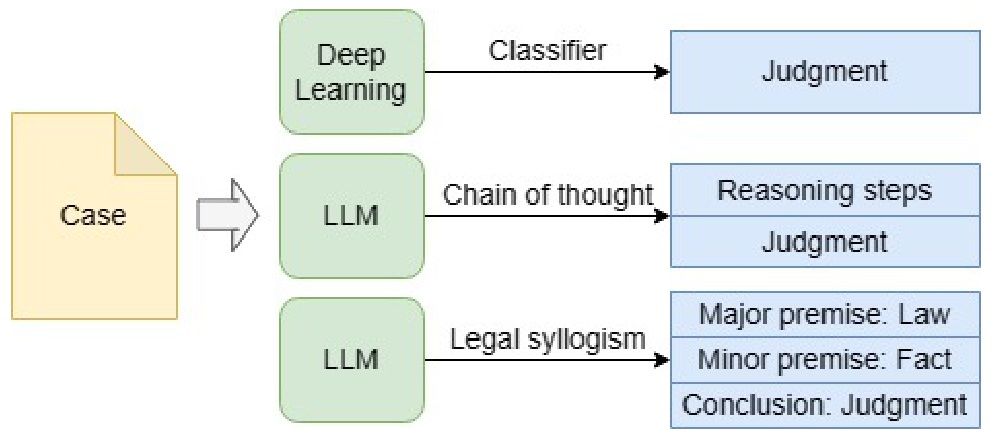
过去的方法主要是通过学习、微调或示例来教授大型语言模型(LLM)进行法律判决预测。这些方法存在的问题是学习样本有限,解释性差。因此,本文提出了面向法律判决预测的简单提示方法——法律演绎提示(LoT),使模型能够根据法律大前提、事实小前提以及结论进行演绎推理并给出判决,无需学习、微调或示例。
本文提出的研究方法是使用法律演绎提示教授LLMs进行法律判决预测。该方法使模型能够集中于与判决相关的关键信息,并正确理解行为的法律含义。
本文在中国刑事案例数据集CAIL2018上对GPT-3模型进行了零-shot判决预测实验。实验结果表明,使用法律演绎提示的LLMs相比于基准方法和思维链提示(目前的最先进提示方法)在多样化的推理任务上实现了更好的性能。法律演绎提示使模型能够预测判决,同时附带法律条文和解释,显著提高了模型的可解释性。

重要问题探讨
1. 为什么当前的法律判决预测模型缺乏可解释性?
○ 当前的法律判决预测模型仅提供最终的判决结果,但缺乏提供法律推理过程的中间步骤。
○ 这限制了模型的可解释性,因为判断的依据无法被
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 690
690

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









