







一、线程的实现及相关操作
线程的介绍
1.线程
- 进程是操作系统中进行保护和资源分配的基本单位,操作系统分配资源以进程为基本单位,而线程是进程的组成部分,是程序执行流的最小单元
- 多个线程在同一个进程下执行,并共享相同的上下文
- 线程包括开始、执行顺序和结束三部分
- 线程可以被抢占(中断)和临时挂起(睡眠、让步)
- 线程一般是以并发的方式执行的
2.并发
- 并发是一种属性—程序、算法或问题的属性
- 并发并不等同于并行,并行只是并发问题的可能方法之一
- 并发与并行
- 并行是指两个或者多个事件在同一时刻发生,而并发是指两个或多个事件在同一时间间隔发生
- 简而言之,并发是指有处理多个任务的能力,不一定要同时;并行则是指有同时处理多个任务的能力
线程的两种实现方式
方式一:Threading模块实现线程
1.实现流程
- 创建线程:
t = threading.Tread(taget=业务函数名, name='线程名') - 启动线程:
t.start() - 挂起线程:
t.join()
2.Threading模块的常用对象
| 对象 | 描述 |
|---|---|
| Thread | 表示一个执行线程的对象 |
| Lock | 锁原语对象(和thread模块中的锁一样) |
| Condition | 条件变量对象,使得一个线程等待另一个线程满足特定的"条件",比如改变状态或某个数据值 |
| Event | 条件变量的通用版本,任意数量的线程等待某个事件的发生,在该事件发生后所有线程将被激活 |
| Semaphore | 为线程间共享的有限资源提供了一个"计数器",如果没有可用资源时会被阻塞 |
| BoundedSemaphore | 与Semaphore相似,不过他不允许超过初始值 |
| Timer | 与Thread相似,不过它要在运行前等待一段事件 |
| Barrier | 创建一个"障碍",必须达到指定数量的线程后才可以继续 |
3.Threading模块的常用方法
| 方法 | 描述 |
|---|---|
| Thread(targer=函数名, [name=“线程名”]) | 创建一个新的线程对象 |
| current_thread() | 获取当前线程对象 |
| Lock() | 获取Lock锁对象 |
| RLock() | 获取RLock锁对象 |
4.Thread对象的数据属性
| 属性 | 描述 |
|---|---|
| name | 线程名 |
| ident | 线程的标识符 |
| deamon | 布尔标志,表示这个线程是否是守护线程 |
5.Thread对象的常用方法
| 属性 | 描述 |
|---|---|
| Thread(target=业务函数名[, name=“线程名”, args=参数序列, kwargs=字典]) | 实例化一个线程对象,需要有一个可调用的target,以及参数args或kwargs, 其中args必须为序列,且元素个数要与业务函数的参数个数匹配 |
| start() | 开始执行该线程 |
| run() | 定义线程功能的方法(通常会重写此方法来运行此线程的代码) |
| join(timeout=None) | 直至启动的线程终止之前挂起主线,除非给出了timeout(秒) |
| getName() | 返回线程名 |
| setName(name) | 设置线程名 |
| isAlivel/is_alive() | 布尔标志,表示这个线程是否还存活 |
| isDaemon() | 如果是守护线程,则返回True;否则返回False |
| setDaemon() | 把线程的守护标志设置为布尔值daemonic(必须在线程start()之前调用) |
6.示例
import threading
import time
def run():
"""线程任务"""
i = 0
while i < 3:
print("目前线程{0}:{1}".format(threading.current_thread().name, i))
i += 1
time.sleep(1)
if __name__ == "__main__":
t = threading.Thread(target=run, name="测试线程")
t.start()
run()

方式二:继承Thread的实现线程
- 可以通过继承Thread重写run方法即可
import threading
import time
class MyThread(threading.Thread):
"""线程子类"""
def run(self):
n = 0
while n < 3:
print("当前线程为{0}:{1}".format(threading.current_thread().name, n))
n += 1
time.sleep(2)
if __name__ == "__main__":
t = MyThread(name="自定义线程")
t.start()
print("当前线程为{0}".format(threading.current_thread().name))

多线程并发的隐患
资源竞争
如果我们开启多个线程,都有用到一个共用资源,这个时候会出现争用资源的情况
import threading
import time
money = 1000
def change_money(num):
global money
while True:
money += num
time.sleep(1)
money -= num
print("存取{0}, 目前还剩{1}".format(num, money))
class MyThread(threading.Thread):
"""自定义线程"""
def __init__(self, num):
super().__init__()
self.num = num
def run(self):
change_money(self.num)
if __name__ == "__main__":
t1 = MyThread(5)
t2 = MyThread(8)
t1.start()
t2.start()
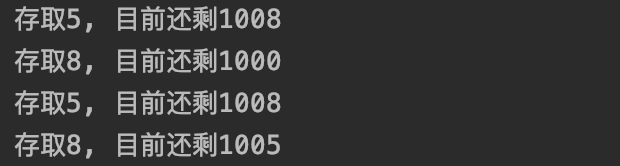
- 如上述结果,本应该每次执行都剩下1000的,但是由于线程a对共用资源进行加操作后在还未执行减操作时,程序就切换到线程b进行了存取操作,因此出现了资源异常的现象,想要解决这个问题,就需要用到多线程的锁
多线程中的锁
1.Python中的三种线程锁
以下三种锁都是threading模块中的
- Lock
- Rloc
- Condition
2.Lock
- 锁住:
acquire() - 解锁:
release()
import threading
import time
money = 1000
my_lock = threading.Lock()
def change_money(num):
global money
while True:
try:
my_lock.acquire()
money += num
money -= num
print("存取{0}, 目前还剩{1}".format(num, money))
finally:
my_lock.release()
class MyThread(threading.Thread):
"""自定义线程"""
def __init__(self, num):
super().__init__()
self.num = num
def run(self):
change_money(self.num)
if __name__ == "__main__":
t1 = MyThread(5)
t2 = MyThread(8)
t1.start()
t2.start()
- 注意: 如果同一段代码对
Lock进行多次acquire()操作,会造成死锁 - 锁也能使用
with lock语句,会自动释放锁
while True:
with my_lock:
money += num
money -= num
print("存取{0}, 目前还剩{1}".format(num, money))
3.RLock
- RLock的使用跟Lock的使用是一样的,两者间的主要区别在于:在同一线程内,对
RLock进行多次acquire()操作,程序不会堵塞,不会造成死锁
多线程的调度及优化
线程也是一种资源,我们不能无限度的去开启线程,这样会造成资源浪费甚至程序崩溃,Python为我们提供了一些线程的优化手段,接下来对线程池的实现进行学习
1.Python的两种线程池
- 通过
multiprocessing.dummy模块提供的Pool类实现线程池 - 通过
ThreadPoolExecutor实现线程池
2.multiprocessing.dummy模块实现线程池
Pool(最高线程数): 构造Pool对象map(任务函数名, 参数序列):批量加入线程任务, 第一个参数为需要线程运行的函数名,第二个参数为需要传给函数的参数序列,map会逐一将序列中的元素一一传给任务函数close(): 关闭进程池,不再接受新的进程join(): 主进程阻塞等待子进程的退出,注意,调用此方法前需要先调用close()- 示例
import threading
import time
from multiprocessing.dummy import Pool
def run(num):
"""线程运行内容"""
print(threading.current_thread().name, num)
time.sleep(2)
def dummy_pool():
t1 = time.time()
n_list = range(100)
pool = Pool(10)
pool.map(run, n_list)
pool.close()
pool.join()
print(time.time() - t1)
if __name__ == "__main__":
dummy_pool()
3.ThreadPoolExecutor实现线程池
- ThreadPoolExecutor常用函数
| 函数 | 描述 |
|---|---|
| ThreadPoolExecutor(max_workers=10) | 构造十个线程的线程池对象 |
| submit(任务函数名[,*args[,**kwargs]]) | 为线程池提交单个线程任务,返回一个Future对象,为异步调用,可以通过submit(...).result()来实现同步调用 |
| map(任务函数名, 参数序列) | 加入线程任务,第一个参数为需要线程运行的函数名,第二个参数为需要传给函数的参数序列,map会逐一将序列中的元素一一传给任务函数,为异步调用,返回一个迭代器里面存放了所有的返回结果 |
| shutdown([wait=True]) | 释放线程池资源,类似于close()+join(),当wait=True(默认)时表示等线程池执行完毕再执行主线程,如果使用with语句则会自动使用(wait=True) |
- Future的常用函数
| 函数 | 描述 |
|---|---|
| done() | 判断任务是否完成,任务完成则返回True |
| result([timeout=None]) | 获取任务返回结果,如果任务未完成,则会等任务完成后再取得任务结果,如果设置了timeout,当等待时间超过timeout则抛出异常 |
| add_done_callback(fn) | 添加回调函数,当任务被取消或顺利完成时,将会将future对象作为参数调用fn |
| cancel() | 取消任务,取消成功返回True,当任务正在执行或已执行完成则无法取消 |
| cancelled() | 判断任务是否被取消成功,是则返回True |
| running() | 如果任务正在进行无法被取消则返回True |
| exception([timeout=None]) | 获取该任务抛出的异常 |
- 示例
import threading
import time
from concurrent.futures.thread import ThreadPoolExecutor
def run(num):
"""线程运行内容"""
print(threading.current_thread().name, num)
time.sleep(2)
return "ok---{0}".format(num)
def call_back(f):
print("任务完成:", f.result())
def thread_pool():
t1 = time.time()
n_list = range(5)
future_list = []
with ThreadPoolExecutor(max_workers=10) as executor:
for n in n_list:
future_list.append(executor.submit(run, n))
for future in future_list:
future.add_done_callback(call_back)
print(time.time() - t1)
if __name__ == "__main__":
thread_pool()

二、进程的实现及相关操作
进程的介绍
- 进程是一个执行中的程序,是操作系统中进行保护和资源分配的基本单位,操作系统分配资源以进程为基本单位
- 每个进程都有自己的地址空间、内存、数据栈以及其他用于跟踪执行的辅助数据
- 操作系统管理其上所有进程的执行,并为这些进程合理地分配时间
- 进程也可以通过派生(fork或spawn)新的进程来执行其他任务
进程模块-multiprocessing
multiprocessing模块用于实现多进程代码
1.multiprocessing模块常用函数
| 函数 | 描述 |
|---|---|
| Process(target=业务函数名[, name=“线程名”][, args=参数序列][, kwargs=字典][, daemon=布尔值]) | 实例化一个进程对象,其中args参数必须是序列而且元素的数量要跟业务函数的参数个数一致,kwargs则必须为字典 |
| current_process() | 获取当前进程对象 |
| Lock() | 获取Lock锁对象 |
| RLock() | 获取RLock锁对象 |
2.Process对象的常用属性
| 属性 | 描述 |
|---|---|
| name | 进程名 |
| ident | 进程的标识符 |
| deamon | 布尔标志,表示这个进程是否是守护进程 |
| pid | 返回进程id |
3.Process对象的常用函数
| 函数 | 描述 |
|---|---|
| Process(target=业务函数名[, name=“线程名”][, args=参数序列]) | 实例化一个进程对象,其中args参数必须是序列,而且元素的数量要跟业务函数的参数个数一致 |
| start() | 开始执行该线程 |
| run() | 定义进程功能的方法(通常会重写此方法来运行此进程的业务逻辑代码) |
| join(timeout=None) | 直至启动的进程终止之前主程序不会结束,除非给出了timeout(秒) |
| is_alive() | 布尔标志,表示这个进程是否还存活 |
| close() | 关闭进程,释放资源 |
| terminate() | 强制终止进程 |
进程实现的两种方式
进程的实现方式其实跟线程的实现是很相似,也分为两种
方式一:Process类实现进程
import os
import time
from multiprocessing import Process
def run(process_name):
print("当前线程-{0}, ID-{1}".format(process_name, os.getpid()))
time.sleep(15)
if __name__ == "__main__":
process = Process(target=run, args=["my process"])
process.start()
process.join()
方式二:继承Process的子类来实现进程
import os
import time
from multiprocessing import Process
class MyProcess(Process):
def __init__(self, process_name, *args, **kwargs):
super().__init__(*args, **kwargs)
self.process_name = process_name
def run(self):
print("当前线程-{0}, ID-{1}".format(self.process_name, os.getpid()))
time.sleep(15)
if __name__ == "__main__":
p = MyProcess("my process")
p.start()
p.join()
进程之间的通信
在Python中我们可以通过Queue、Pipes等实现进程之间的通信,下面我们学习一下Queue模块的使用
1.Queue的常用函数
- 这里说的Queue是指multiprocessing模块中的Queue,该类继承了queue.Queue中除了
task_done()和join()外的所有方法
| 函数 | 描述 |
|---|---|
| Queue([maxsize]) | 实例化一个Queue对象,可指定最大队列数,当maxsize为0或负数时,表示无限,默认为0 |
| put(somthing[,block,timeout]) | 向队列放入消息,当block为True(默认)且timeout为None(默认)时,如果队列满了会一直等到队列有空位了再放入;当block为False或者设定了timeout,如果队列满了则会直接抛出异常或者等待timeout秒后抛出异常 |
| get([block, timeout]) | 消费队列信息,参数用法与put一样 |
| qsize() | 获取队列消息数量 |
| empty() | 返回布尔值,表示队列是否为空 |
| full() | 返回布尔值,表示队列是否已满 |
| close() | 关闭队列,不再向队列放入信息 |
| join_thread() | 挂起主线程,使用前必须先调用close() |
2.示例
import time
from multiprocessing import Process, current_process, Queue
class GetProcess(Process):
"""自定义进程--获取信息"""
def __init__(self, q, *args, **kwargs):
self.q = q
super().__init__(*args, **kwargs)
def run(self):
"""获取通信的业务逻辑"""
while True:
result = self.q.get()
if result is None:
break
print("获取内容:{0}---{1}".format(result, current_process().name))
class PutProcess(Process):
"""自定义进程--发送信息"""
def __init__(self, q, *args, **kwargs):
super().__init__(*args, **kwargs)
self.q = q
def run(self):
"""发送信息业务逻辑"""
ls = [
"静夜诗",
"床前明月光",
"疑是地上霜",
"举头望明月",
"低头思故乡"
]
for l in ls:
print("写入内容:{0}--{1}".format(l, current_process().name))
self.q.put(l)
time.sleep(2)
# 结束标识符
self.q.put(None)
if __name__ == "__main__":
queue = Queue()
put_thread = PutProcess(queue)
get_thread = GetProcess(queue)
put_thread.start()
get_thread.start()
put_thread.join()
get_thread.join()
多进程的锁
1.Python中的三种进程锁
以下三种锁都是multiprocessing模块中的
- Lock
- Rloc
- Condition
2.Lock
- 锁住:
acquire() - 解锁:
release() - 注意不要对同一段代码进行重复、嵌套锁,会造成死锁
import time
from multiprocessing import Process
from multiprocessing import Lock
class MyProcess(Process):
""" 自定进程 """
def __init__(self, num, lock, *args, **kwargs):
super().__init__(*args, **kwargs)
self.num = num
self.lock = lock
def run(self):
""" 进程业务代码 """
with self.lock:
with open("test_process_lock.txt", "a+", encoding="utf-8") as f:
for i in range(5):
content = "进程锁测试,目前进程:{0}----{1}\n".format(self.num, i)
f.write(content)
print(content)
time.sleep(1)
if __name__ == "__main__":
lock = Lock()
p1 = MyProcess(1, lock)
p2 = MyProcess(2, lock)
p3 = MyProcess(3, lock)
p1.start()
p2.start()
p3.start()
进程池的实现
ProcessPoolExecutor实现线程池
- ProcessPoolExecutor常用函数
| 函数 | 描述 |
|---|---|
| ProcessPoolExecutor(max_workers=10) | 构造十个线程的线程池对象 |
| submit(任务函数名[,*args,**kwargs]) | 为进程池提交单个线程任务,返回一个Future对象,为异步调用,可以通过submit(...).result()来实现同步调用 |
| map(任务函数名, 参数序列) | 加入进程任务,为异步调用,第一个参数为需要进程运行的函数名,第二个参数为需要传给函数的参数序列,map会逐一将序列中的元素一一传给任务函数,返回一个迭代器里面存放了所有的返回结果 |
| shutdown([wait=True]) | 释放进程池资源,类似于close()+join(),当wait=True(默认)时表示等进程池执行完毕再执行主进程,如果使用with语句则会自动使用(wait=True) |
- 示例
import threading
import time
from concurrent.futures.process import ProcessPoolExecutor
from concurrent.futures.thread import ThreadPoolExecutor
def run(num):
"""线程运行内容"""
print(threading.current_thread().name, num)
time.sleep(2)
return "ok---{0}".format(num)
def call_back(f):
print("任务完成:", f.result())
def thread_pool():
"""自定义线程池"""
t1 = time.time()
n_list = range(10)
future_list = []
with ProcessPoolExecutor(max_workers=10) as executor:
for n in n_list:
future_list.append(executor.submit(run, n))
for future in future_list:
future.add_done_callback(call_back)
print(time.time() - t1)
if __name__ == "__main__":
thread_pool()
三、协程
协程是什么
协程也称为微线程,是python中另外一种实现多任务的方式,只不过比线程占用更小执行单,可以理解为在一个线程中的某个函数,可以在任何地方保存当前函数的一些临时变量等信息,然后切换到另外一个函数中执行,注意不是通过调用函数的方式做到的,并且切换的次数以及什么时候再切换到原来的函数都由开发者自己确定(此段内容来自 https://www.cnblogs.com/zhangfengxian/p/10163416.html)
协程的实现
1.使用生成器(yield)实现—3.5版本之前
yiled:可以在当前语句停顿,保存状态协程对象.send(some):可以把数据传到协程对象内,并切换调用协程对象、返回结果,使用前必须先启动协程对象协程对象.close():关闭协程- 启动协程对象:
next(协程对象)或协程对象.__next__()或协程对象.send(None) - 示例
def consumer():
r = ''
while True:
n = yield r
if not n:
return
print('[CONSUMER] Consuming %s...' % n)
r = '200 OK'
def produce(c):
c.send(None)
n = 0
while n < 5:
n = n + 1
print('[PRODUCER] Producing %s...' % n)
r = c.send(n)
print('[PRODUCER] Consumer return: %s' % r)
c.close()
c = consumer()
produce(c)

- 首先调用
c.send(None)启动生成器 - 然后,一旦生产了东西,通过
c.send(n)切换到consumer执行 - consumer通过
yield拿到消息,处理,又通过yield把结果传回 - produce拿到consumer处理的结果,继续生产下一条消息
- produce决定不生产了,通过
c.close()关闭consumer,整个过程结束
2.使用asyncio模块实现—3.5版本之后(推荐)
asyncio模块是通过使用async、await关键字语法编写并发代码的模块,被用作多个提供高性能Python异步框架的基础,包括网络和网站服务,数据库连接库,分布式任务队列等等
-
async- 用于定义特殊函数,当该函数被调用时,不执行里面的代码,而是返回一个协程对象。在事件循环中调度该协程对象执行前,该对象不会执行任何操作
- 语法:
async def test_async_f(): pass -
await- 用于挂起阻塞的异步调用接口(在协程中等待其他协程对象执行完成)
- 语法:
async def test_async_f(): await asyncio.sleep(1) -
asyncio模块的常用函数
函数 描述 run(coroutine) 运行一个协程,主要用于运行入口协程的主函数 create_task(coroutine) 创建Task对象,并自动添加进事件循环中,可以使得这些添加的协程同时(并发)运行(底层应该是get_running_loop()和loop.create_task(coro)的封装) gather(*args) 将多个协程对象添加到事件循环中,返回一个task对象(略不同) sleep(num) 返回一个协程对象,该协程对象的作用是当前协程停顿num秒 get_event_loop() 获取事件循环对象Loop,当前没有事件循环时则新建一个并返回 new_event_loop() 创建一个新的事件循环 get_running_loop() 返回当前正在运行的事件循环对象 set_event_loop(loop) 将传入的事件循环设置为当前线程事件循环 iscoroutinefunction(fn) 判断该函数是不是协程函数,是则返回True iscoroutine(obj) 判断对象是否是协程对象,是则返回True - 使用scyncio模块实现协程—同步运行
import asyncio import time async def say_something(delay, words): """ 协程函数 """ await asyncio.sleep(delay) print(words) async def main(): """ 协程入口 """ start_time = time.time() print("开始运作协程......") await say_something(2, "Hello") await say_something(2, "Python") print("协程任务运作结束......共使用{0}秒".format(time.time()- start_time)) if __name__ == "__main__": asyncio.run(main())
- 使用scyncio模块实现协程—并发运行
import asyncio import time async def say_something(delay, words): """ 协程函数 """ await asyncio.sleep(delay) print(words) async def main(): """ 协程入口 """ start_time = time.time() task = asyncio.gather(say_something(2, "Hello"), say_something(2, "Python")) print("开始运作协程......") await task print("协程任务运作结束......共使用{0}秒".format(time.time() - start_time)) if __name__ == "__main__": asyncio.run(main())![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-rDafFGsm-1576059487173)(http://note.youdao.com/yws/res/46778/BBCC9D2C50294B299699CD06A600EF97)]](https://img-blog.csdnimg.cn/20191211203159616.png)
-
Task(事件循环任务)是Future的子类,用法与Future是相似的,可以参考上文中的Future
4.用事件循环对象实现协程
官方上更加推荐使用asyncio模块的方式去实现协程,但是asyncio底层上很多地方也是使用了loop的方式来实现的,所以这里稍微学习一下,后期有兴趣再深入了解
- 事件循环(Loop)常用函数
函数 描述 create_task(协程对象) 为事件循环添加任务,返回Task对象 run_until_complete(future) 等待循环任务执行结束 run_forever() 事件循环一直运行,直至stop()被调用 stop() 停止事件循环 close() 关闭事件循环 - 通过Loop实现协程
import asyncio import time async def say_something(delay, words): """ 协程函数 """ await asyncio.sleep(delay) print(words) async def main(the_loop): """ 协程入口 """ start_time = time.time() task1 = the_loop.create_task(say_something(2, "Hello")) task2 = the_loop.create_task(say_something(2, "Python")) print("开始运作协程......") await task1 await task2 print("协程任务运作结束......共使用{0}秒".format(time.time() - start_time)) if __name__ == "__main__": loop = asyncio.get_event_loop() loop.run_until_complete(main(loop))
协程之间的通信
Python中,协程之间的通信可以通过asyncio模块下的Queue类来实现
- asyncio.Queue的常用属性
| 属性 | 描述 |
|---|---|
| maxsize | 最大队列数 |
- asyncio.Queue的常用函数
| 函数 | 描述 |
|---|---|
| Queue(maxsize) | 构造协程队列对象 |
| get() | 删除并获取队列中的一条信息,如果队列是空的则一直等待到队列有消息,此函数也是协程函数(需要await) |
| put(item) | 向队列放入信息,如果队列满了 ,则一直等待到队列有空位再传入,此函数为协程函数(需要await) |
| qsize() | 返回队列中的消息数量 |
| join() | 挂起当前线程,直到队列中的消息全部被消费(需要每次get都用task_done告知),此函数为协程函数(需要await) |
| task_done() | 在每次调用了get()后使用,告知队列该消息已经消费完成 |
| empty() | 如果队列为空则返回True |
| full() | 如果队列满了则返回True |
| get_nowait() | 不等待直接获取队列消息,如果队列为空则抛出异常 |
| put_nowait(item) | 不等待直接放入消息,如果队列满了则抛出异常 |
- 示例
import asyncio
async def putter(q, name):
""" 队列消息生产者 """
await asyncio.sleep(1)
for i in range(5):
print("我是生产者:{0}---放入{1}---剩余消息数:{2}".format(name, i, q.qsize()))
await q.put(i)
async def getter(q, name):
""" 队列消费者 """
for i in range(10):
msg = await q.get()
print("我是消费者:{0}---{1}---剩余消息数:{2}".format(name, msg, q.qsize()))
q.task_done()
async def main():
""" 协程入口 """
queue = asyncio.Queue(3)
task = asyncio.gather(putter(queue, "生产者1号"), putter(queue, "生产者2号"), getter(queue, "毁灭者"))
await task
await queue.join()
if __name__ == "__main__":
asyncio.run(main())
















 1826
1826











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









