






前言
学习资料来自b站,视频链接为:FasterRCNN_哔哩哔哩_bilibili
1、Faster R-CNN算法流程
Faster R-CNN算法流程可分为3个步骤:
- 将图像输入网络得到相应的特征图(feature maps);
- 使用RPN结构生成候选框,将RPN生成的候选框投影到特征图上获得相应的特征矩阵(feature vector);
- 将每个特征矩阵通过ROI pooling层缩放到7x7大小的特征图,接着将特征图展平通过一系列全连接层得到预测结果 ;
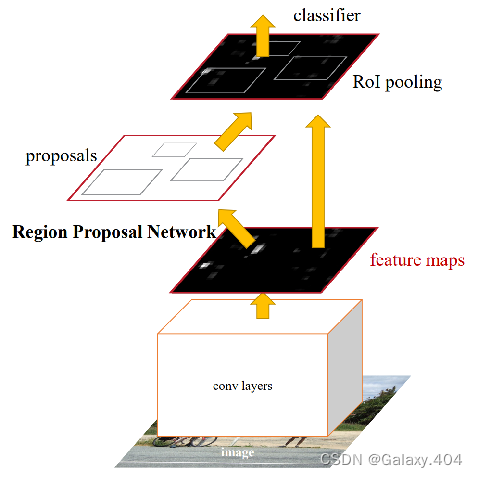
可以理解为是RPN+Fast R-CNN。
2、RPN网络结构
2.1 anchor
在特征图(feature maps)上使用滑动窗口,每滑动到一个位置就生成一个一维向量,在这个向量的基础上通过两个全连接层分别输出目标概率(2k scores)以及边界框回归参数(4k coordinates)。k是anchor boxes的个数,2k就是针对每一个anchor生成的两个概率(背景概率与前景概率)。
这里的256是使用ZF网络作为Fsaster R-CNN的backbone时它所生成的特征图的深度(channel),如果使用的是VGG16的话那就是512,所以这里一维向量的元素个数是根据使用的backbone输出特征矩阵的深度确定的。
对于特征图上的每个3x3的滑动窗口,计算出滑动窗口中心点对应原始图像上的中心点,并以这个点为中心计算出生成k个anchor boxes。 【例如计算x的坐标:[原图宽度/特征图宽度]=步距,特征图上的x坐标乘以步距即可得到原图中的x坐标,y坐标的计算同理。】
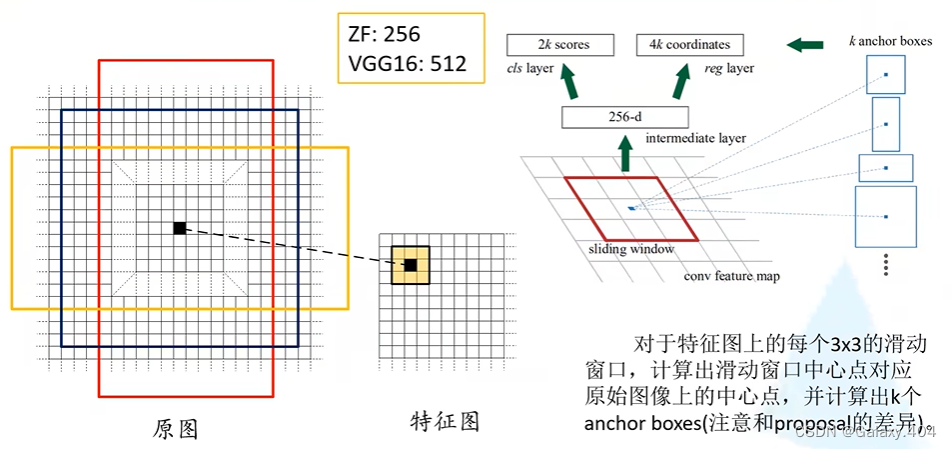
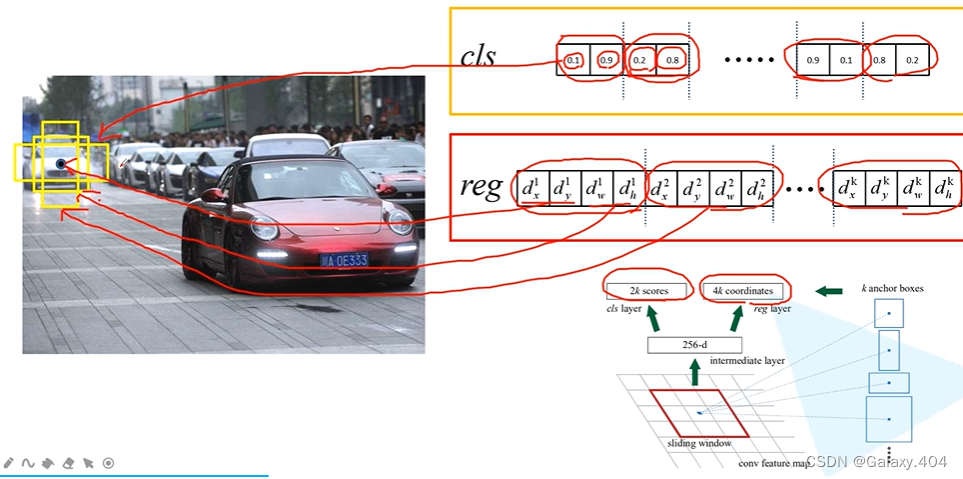
每个anchor都会生成2个score,2k scores两两为一组,第一个是预测为背景的概率,第二个是预测为目标的概率(仅仅是预测为前景/背景,没有进行分类)。回归参数4k个,每4个为一组,dx和dy是中心坐标的预测偏移量,dw和dh是对anchor的宽度及高度的调整。目的是为了更好的框选出前景。
anchor有三种尺度(面积){128²,256²,512²},三种比例{1:1,1:2,2:1},所以每个位置(每个滑动窗口)在原图中都有对应的3*3=9个anchor。所以在每个位置上都会生成2*9=18个类别分数,以及4*9=36个边界回归参数。【面积问题在论文中说是经验所得】
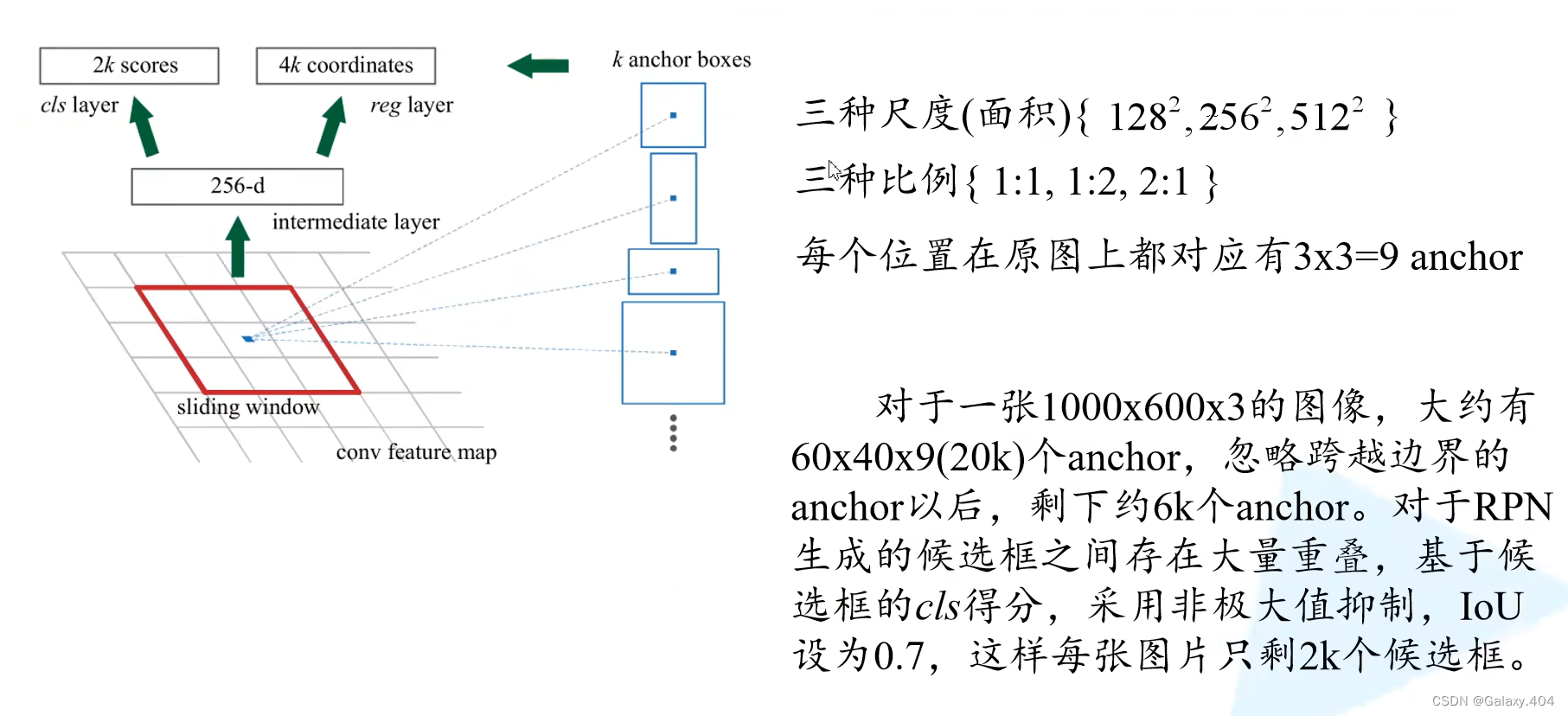
并联两个1×1的卷积层实现类别预测以及边界框回归预测,cls layer采用1×1大小的2k个卷积核进行处理,reg layer采用1×1大小的4k个卷积核进行处理。
2.2 训练样本的采样
原论文中指出,只使用256个anchor,包括正样本和负样本,比例大概为1:1,当正样本数不足128时,使用负样本数填充。①当anchor与group-truth box的IoU大于0.7时,认为这个anchor为正样本;②当anchor与group-truth box的最大IoU大于0.3时,也可以认为这个anchor为正样本;③当anchor与所有group-truth box的最大IoU都小于0.3时,认为这个anchor为负样本。对于正样本与负样本之外的anchor全部丢弃。
3、LOSS
3.1 RPN Multi-task loss
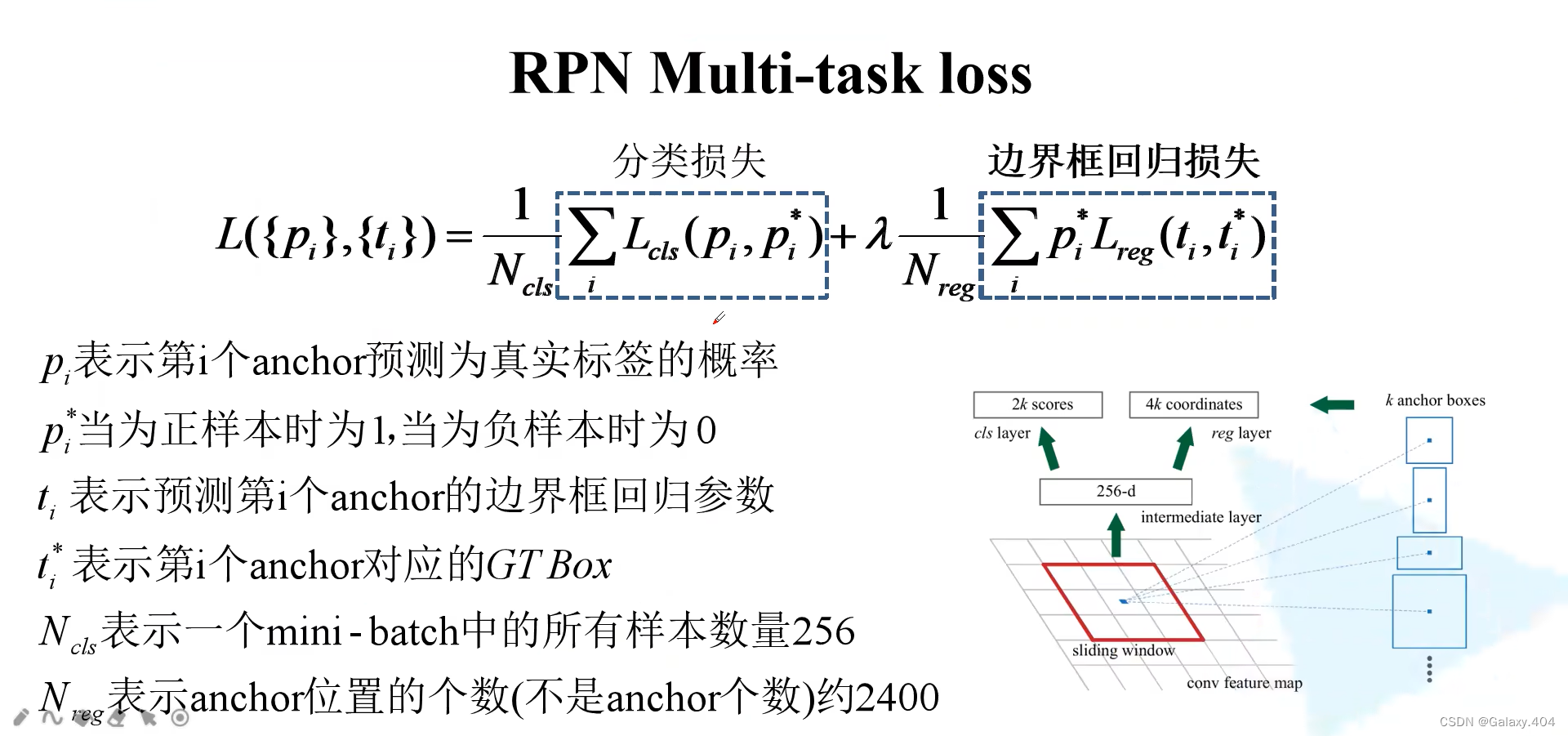
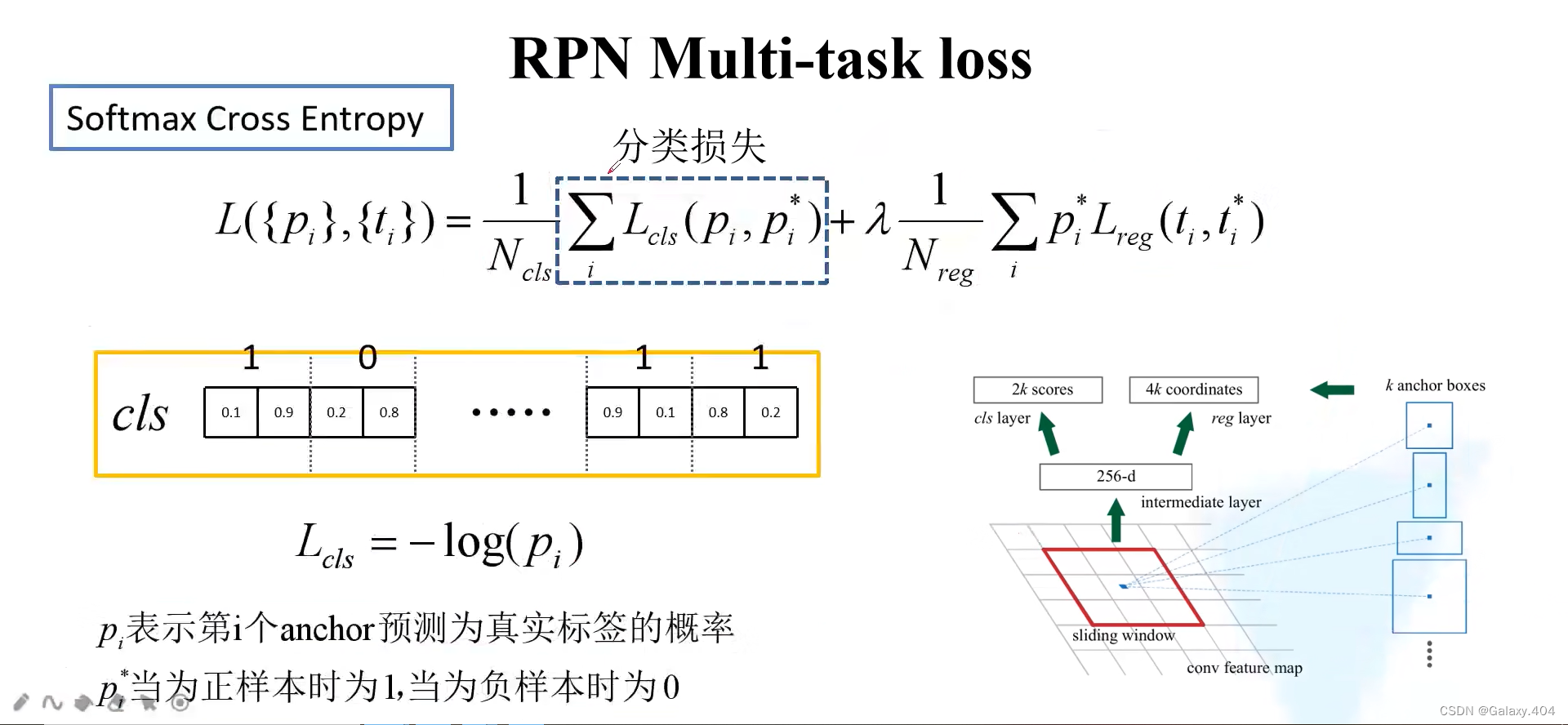
使用多分类计算交叉熵损失:
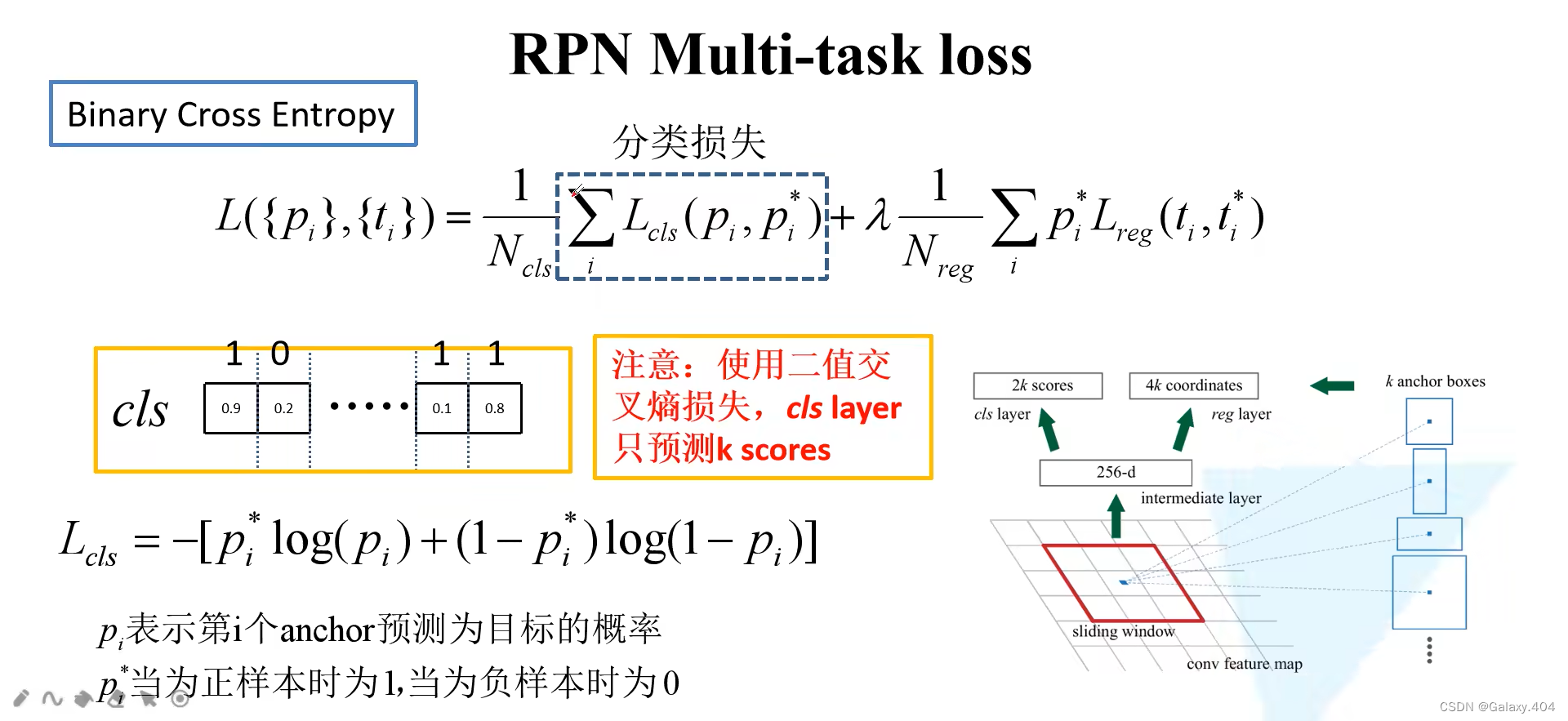
使用二分类计算交叉熵损失:

3.2 Fast R-CNN Multi-task loss

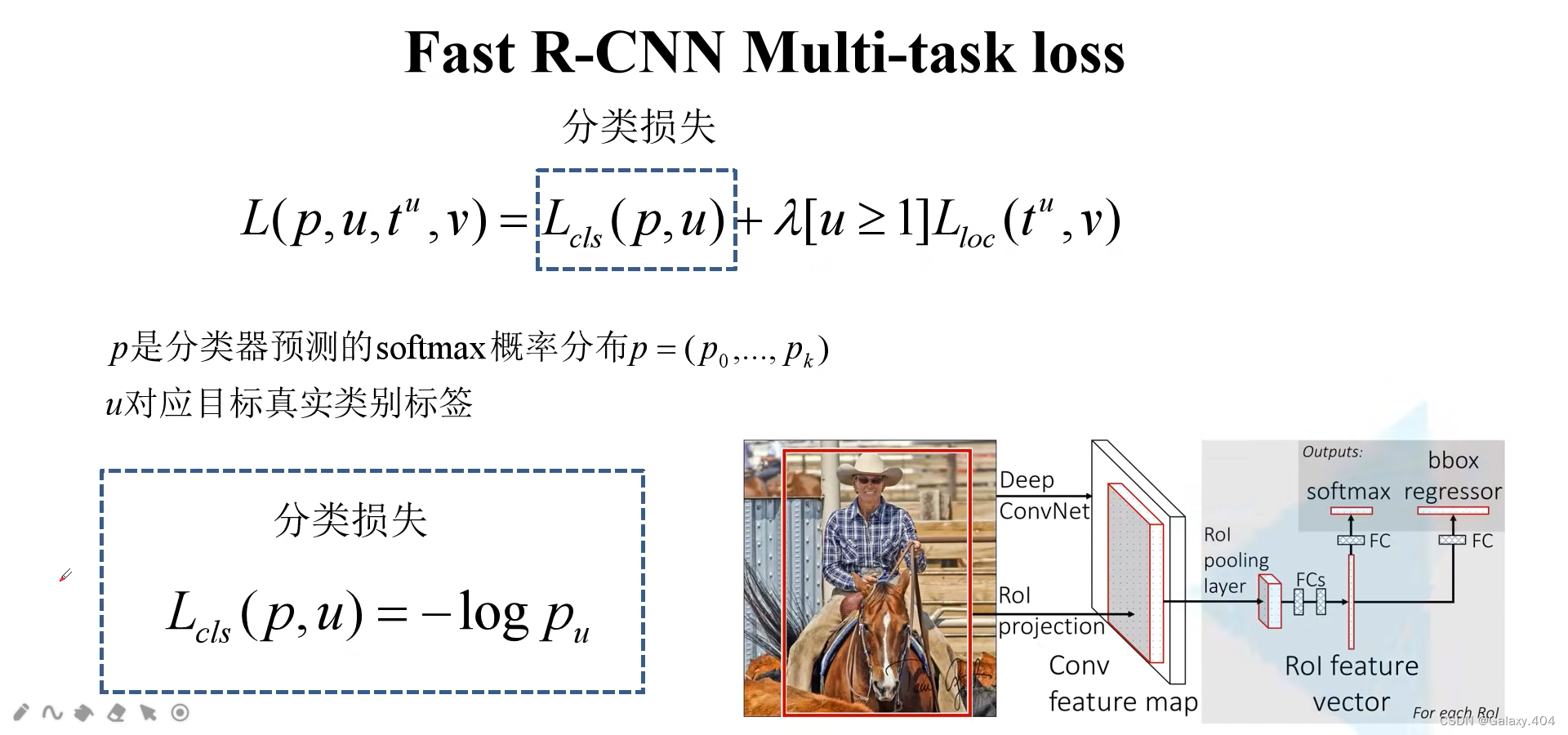
 Faster R-CNN训练直接采用RPN Loss+ Fast R-CNN Loss的联合训练方法。
Faster R-CNN训练直接采用RPN Loss+ Fast R-CNN Loss的联合训练方法。
4、总结

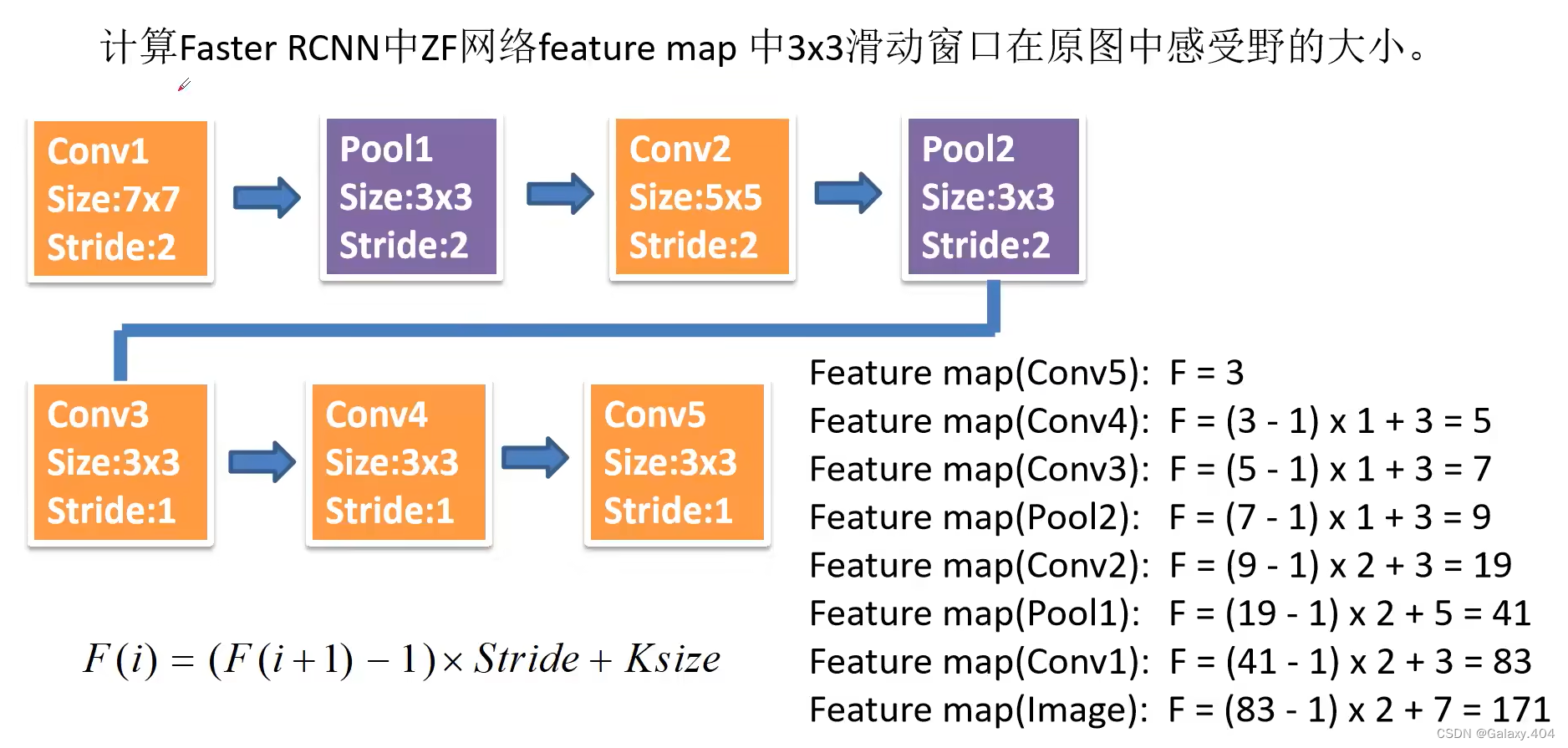
5、拓展-感受野















 151
151











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









