







决策树比较适合分析离散数据,如果是连续数据要先转成离散数据再做分析
一个小栗子
在这个例子中,我们通过一个人的各项属性来推断他是否会买电脑
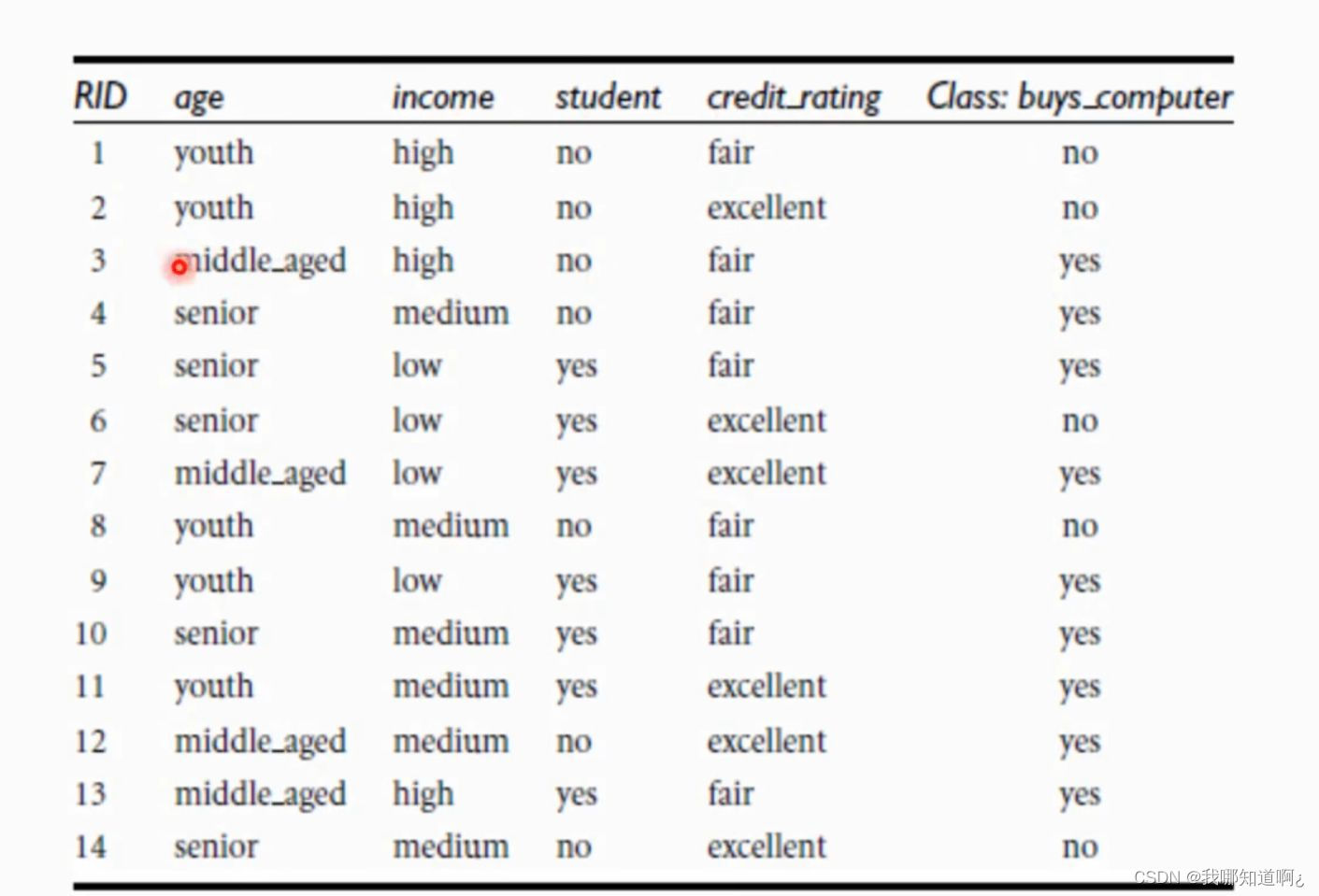
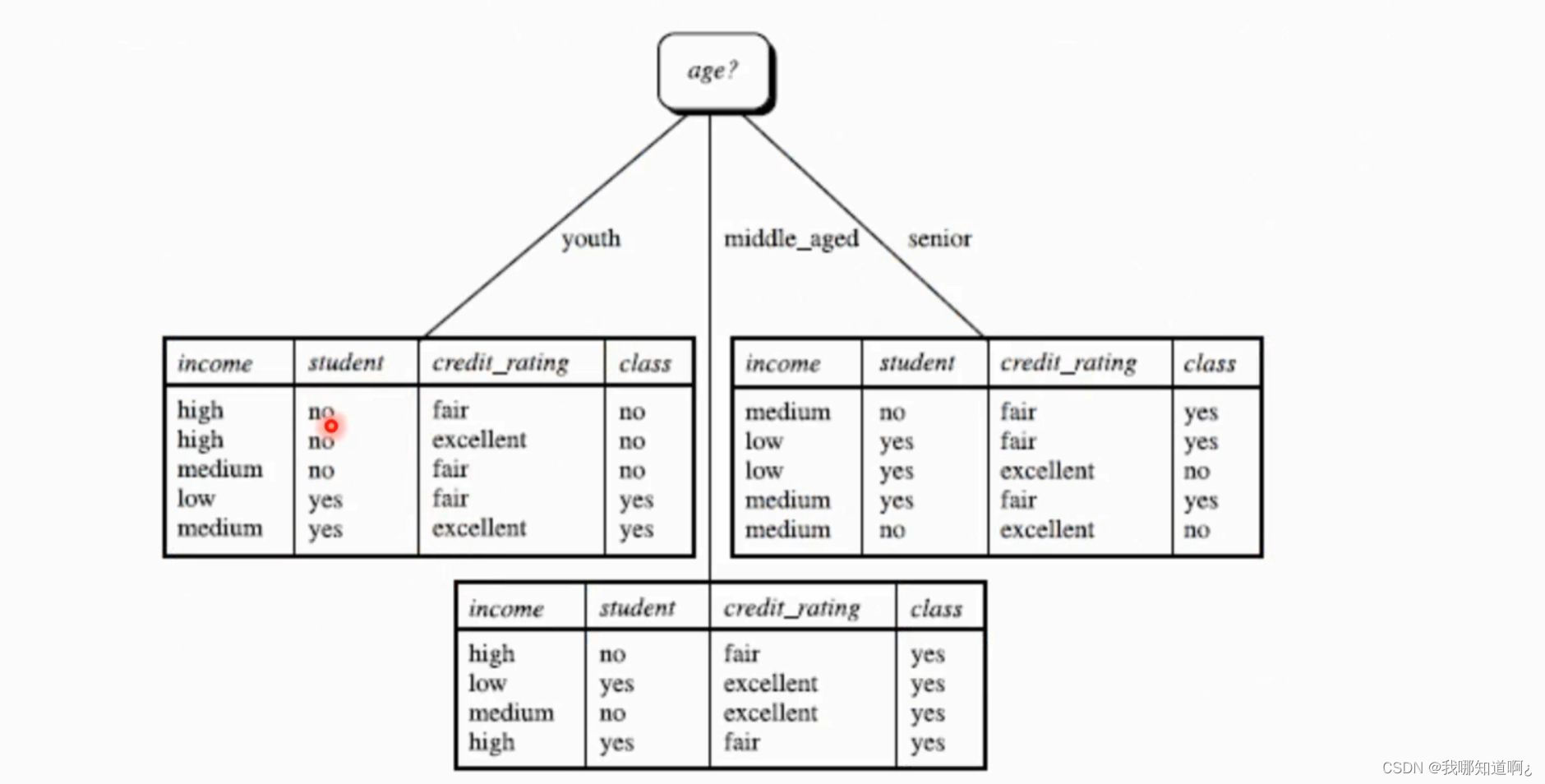
在此基础上构建出的决策树
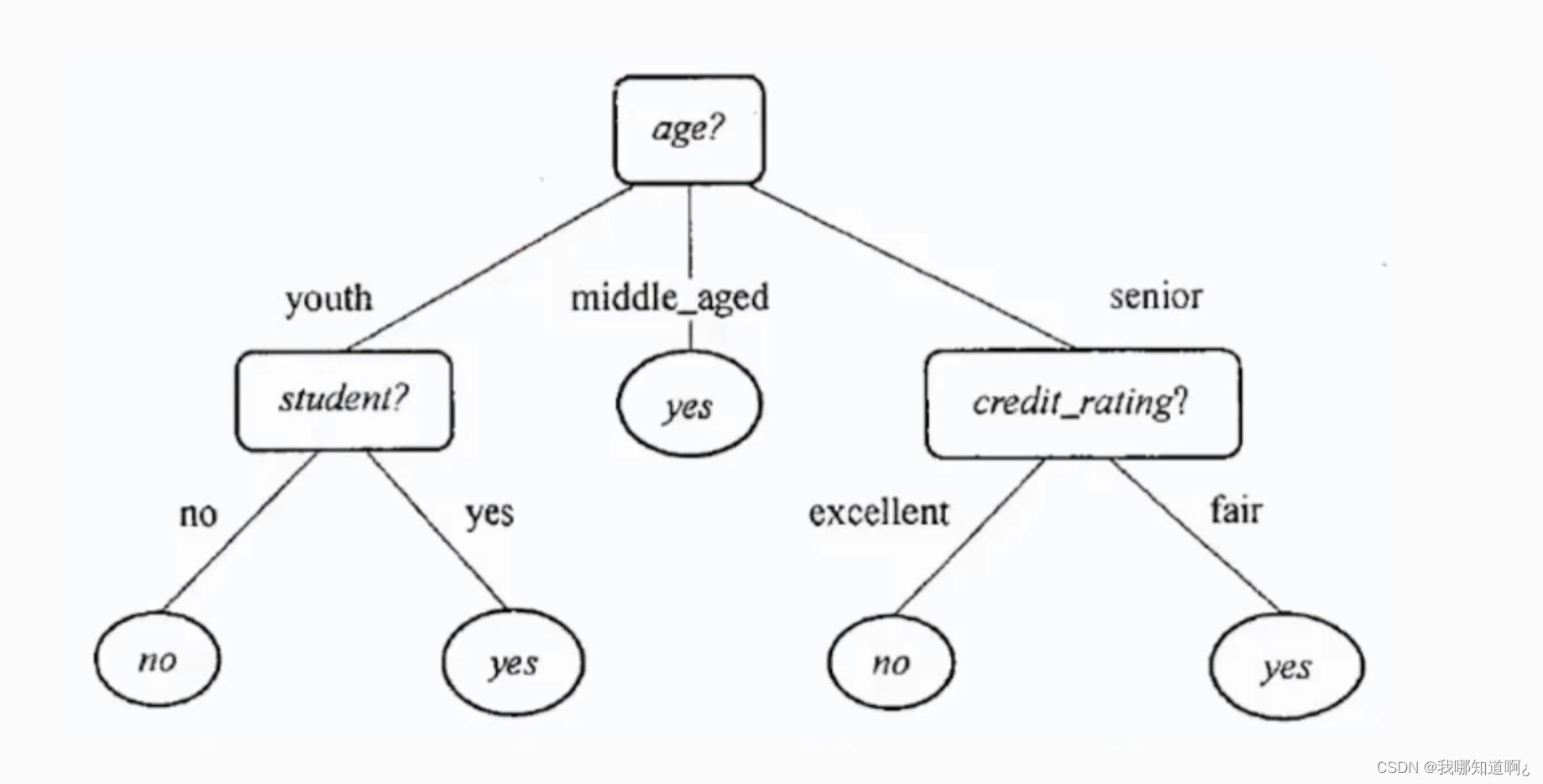
信息熵
信息熵越大,代表事物的不确定性越高
下面是一个计算信息熵的例子

ID3算法
决策树会选择最大化信息增益来对结点进行分类
下面是信息增益的计算,其中第一个式子就是信息熵
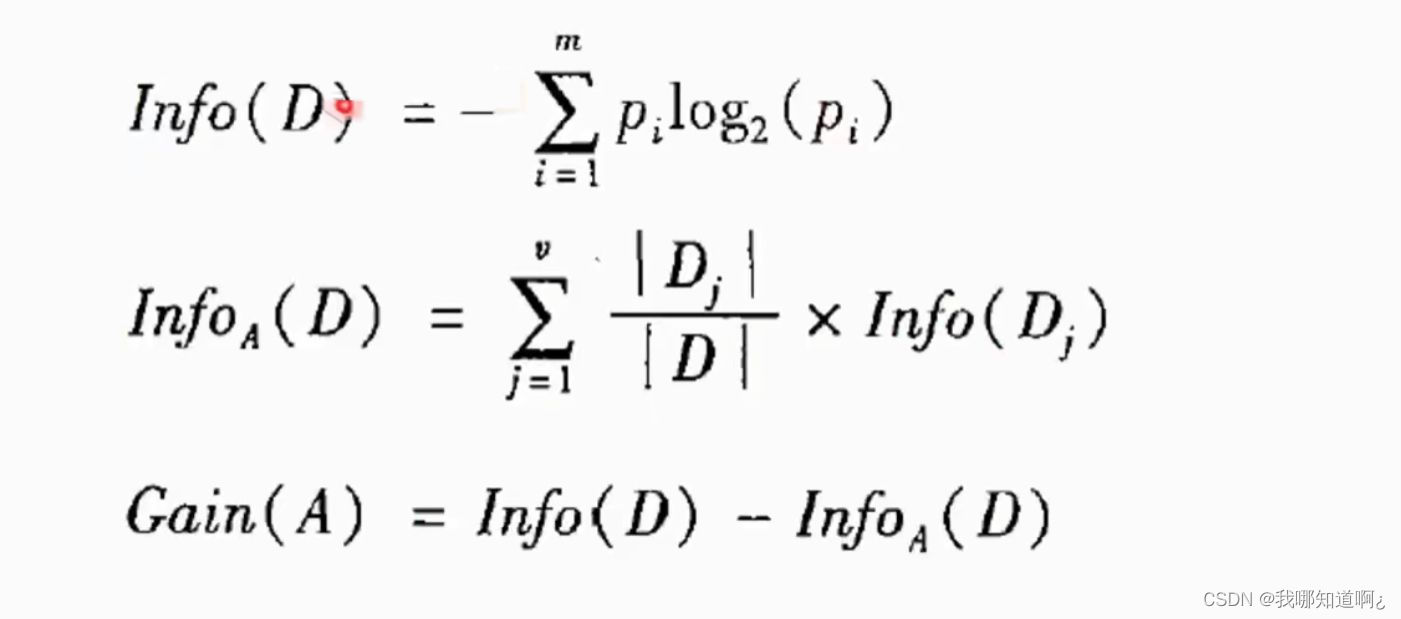
还是同样的例子,此时参数InfoA中的A=age,我们可以看到,14条数据中有五条age为youth,四条为middle_aged,五条为senior,所以式子分为三个部分,括号里的内容就是每条分别的信息熵,比如说age为youth中的人,有两个为no,三个为yes,我们就得出了Infoage中的第一个式子,后面两式子以此类推。

由此可见,age的信息增益最大,所以我们把age设为根节点,得到如下
连续变量的处理
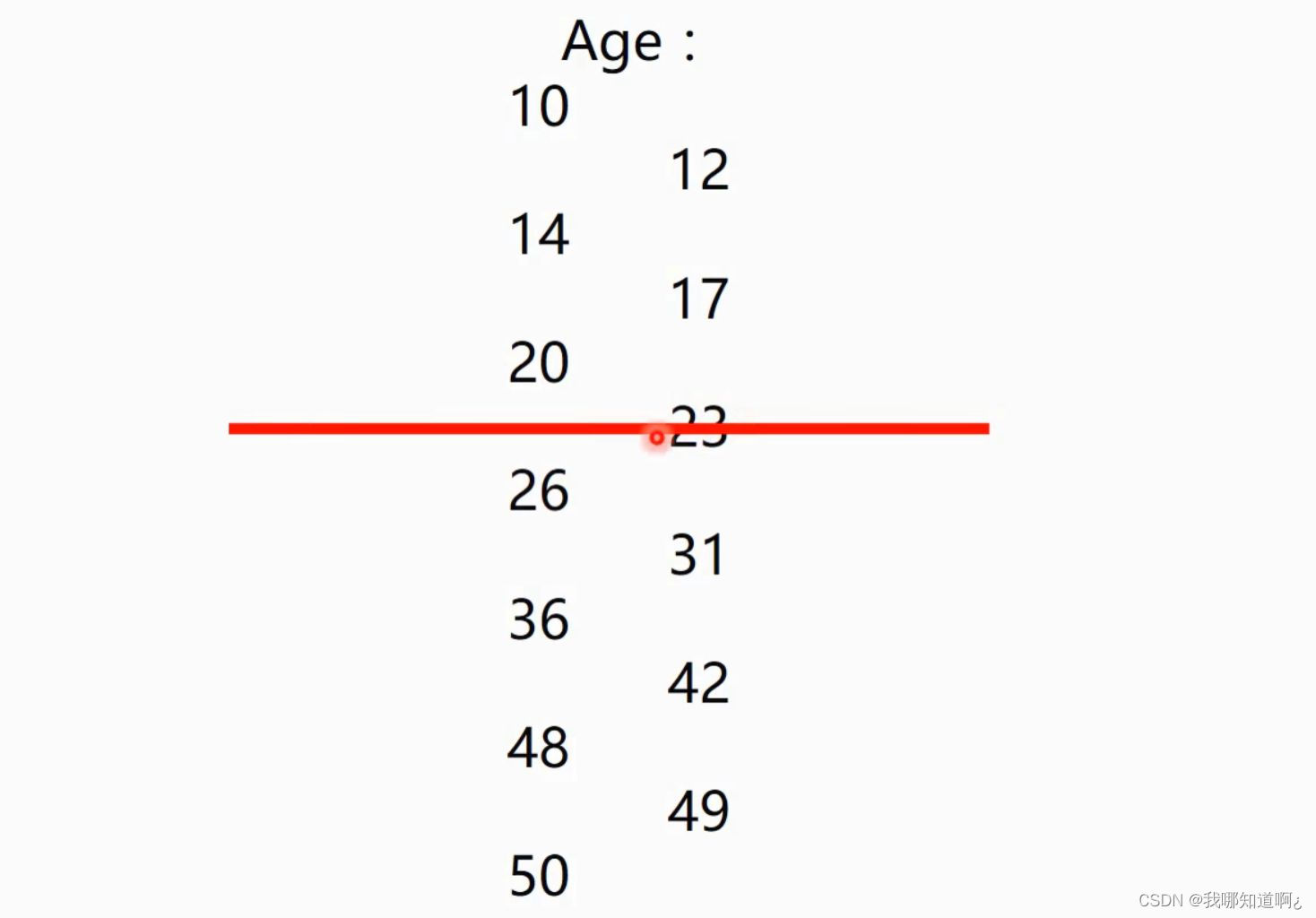
其中,左侧为数据,右侧为每两个数据的平均值,现在假设我们认为大于23为青年,小于23为少年,并且经过计算,这样分类算出来的信息增益最大,我们便把本来连续型的数据变成了大于23和小于23的离散型数据。
python建立模型
import numpy as np
from sklearn.feature_extraction import DictVectorizer
from sklearn import tree
from sklearn import preprocessing
import csv#表单里都是字符,所以使用csv读取数据
#读取数据
Dtree=open("E:\\Temp\\tennis.csv","r")
reader=csv.reader(Dtree)
#获取第一行数据(表头)
headers=reader.__next__()
#print(headers)
#定义两个列表
featureList=[]#保存特征
labelList=[]#保存标签
for row in reader:
#把label存入list(即no或者yes)
labelList.append(row[-1])
#创建一个空的字典
rowDict={}
for i in range(1,len(row)-1):
# 建立一个数据字典
rowDict[headers[i]]=row[i]
#把数据字典存入list
featureList.append(rowDict)
#print(featureList)
#机器不能分析字符,所以我们要把数据转换成01表示
vec=DictVectorizer()
x_data=vec.fit_transform(featureList).toarray()
print(str(x_data))
#打印属性名称(对应了上面01数据的每一列)
print(vec.get_feature_names_out())
#打印标签
print(str(labelList))
#把标签转化成01表示
lb=preprocessing.LabelBinarizer()
y_data=lb.fit_transform(labelList)
print(str(y_data))
#创建决策树模型
model=tree.DecisionTreeClassifier(criterion='entropy')#这个参数表示我们使用ID3算法
#输入数据建立模型
model.fit(x_data,y_data)
C4.5 算法
这个其实就是上面一种算法的改进,因为信息增益的方法倾向于首先选择因子数较多的变量,我们提出了增益率,SplitInfoA(D),并用信息增益除以增益率来改进ID3算法
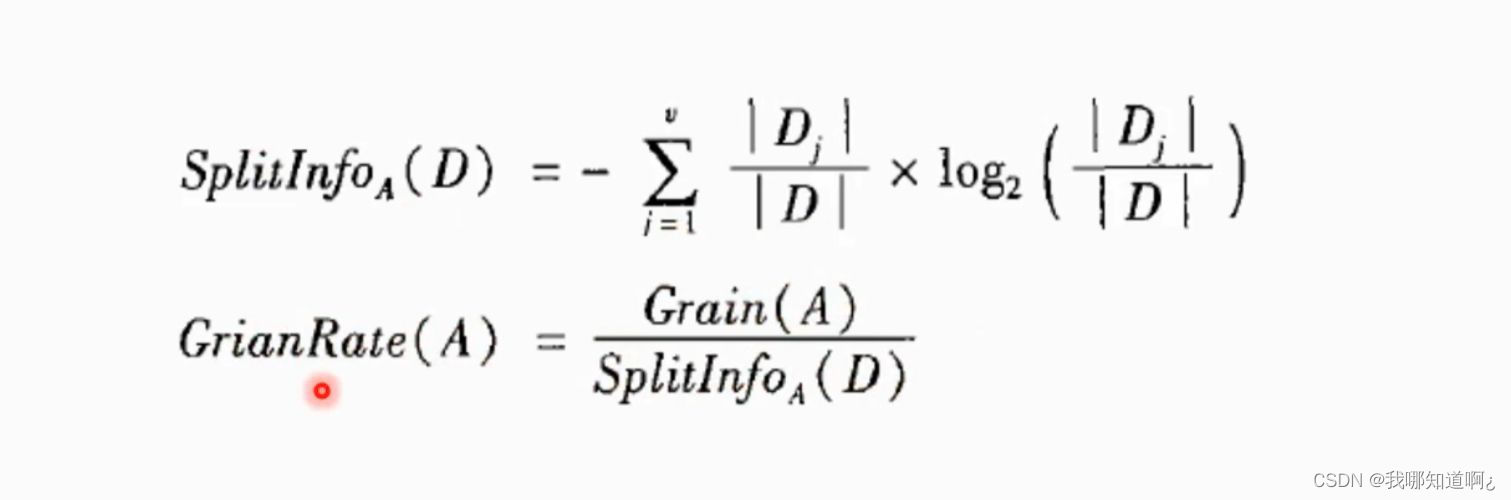














 2823
2823











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









