







 本文探讨了Java 8 Stream的distinct方法在处理流时去除重复元素的原理,通过HashSet实现去重,并指出该方法在有序和无序流中的行为差异。在项目实践中,由于distinct操作导致数据过滤,影响了结果准确性。解决方案是根据业务需求调整去重策略,确保技术应用满足业务场景。
本文探讨了Java 8 Stream的distinct方法在处理流时去除重复元素的原理,通过HashSet实现去重,并指出该方法在有序和无序流中的行为差异。在项目实践中,由于distinct操作导致数据过滤,影响了结果准确性。解决方案是根据业务需求调整去重策略,确保技术应用满足业务场景。
作用:
Stream.distinct() 是 Java 8 引入的一个新特性,用于从流中去除重复的元素。这个方法返回一个新的流,其中包含原流中所有不同的(根据 equals() 和 hashCode() 定义的相等性)元素。其内部实现通常是借助于 HashSet 来完成去重过程的,这是因为 HashSet 本身就是基于 HashMap 实现的,可以高效地进行元素的唯一性检查。
源码:
static <T> ReferencePipeline<T, T> makeRef(AbstractPipeline<?, T, ?> upstream) {
return new ReferencePipeline.StatefulOp<T, T>(upstream, StreamShape.REFERENCE,
StreamOpFlag.IS_DISTINCT | StreamOpFlag.NOT_SIZED) {
<P_IN> Node<T> reduce(PipelineHelper<T> helper, Spliterator<P_IN> spliterator) {
// If the stream is SORTED then it should also be ORDERED so the following will also
// preserve the sort order
TerminalOp<T, LinkedHashSet<T>> reduceOp
= ReduceOps.<T, LinkedHashSet<T>>makeRef(LinkedHashSet::new, LinkedHashSet::add,
LinkedHashSet::addAll);
return Nodes.node(reduceOp.evaluateParallel(helper, spliterator));
}
@Override
<P_IN> Node<T> opEvaluateParallel(PipelineHelper<T> helper,
Spliterator<P_IN> spliterator,
IntFunction<T[]> generator) {
if (StreamOpFlag.DISTINCT.isKnown(helper.getStreamAndOpFlags())) {
// No-op
return helper.evaluate(spliterator, false, generator);
}
else if (StreamOpFlag.ORDERED.isKnown(helper.getStreamAndOpFlags())) {
return reduce(helper, spliterator);
}
else {
// Holder of null state since ConcurrentHashMap does not support null values
AtomicBoolean seenNull = new AtomicBoolean(false);
ConcurrentHashMap<T, Boolean> map = new ConcurrentHashMap<>();
TerminalOp<T, Void> forEachOp = ForEachOps.makeRef(t -> {
if (t == null)
seenNull.set(true);
else
map.putIfAbsent(t, Boolean.TRUE);
}, false);
forEachOp.evaluateParallel(helper, spliterator);
// If null has been seen then copy the key set into a HashSet that supports null values
// and add null
Set<T> keys = map.keySet();
if (seenNull.get()) {
// TODO Implement a more efficient set-union view, rather than copying
keys = new HashSet<>(keys);
keys.add(null);
}
return Nodes.node(keys);
}
}
@Override
<P_IN> Spliterator<T> opEvaluateParallelLazy(PipelineHelper<T> helper, Spliterator<P_IN> spliterator) {
if (StreamOpFlag.DISTINCT.isKnown(helper.getStreamAndOpFlags())) {
// No-op
return helper.wrapSpliterator(spliterator);
}
else if (StreamOpFlag.ORDERED.isKnown(helper.getStreamAndOpFlags())) {
// Not lazy, barrier required to preserve order
return reduce(helper, spliterator).spliterator();
}
else {
// Lazy
return new StreamSpliterators.DistinctSpliterator<>(helper.wrapSpliterator(spliterator));
}
}
@Override
Sink<T> opWrapSink(int flags, Sink<T> sink) {
Objects.requireNonNull(sink);
if (StreamOpFlag.DISTINCT.isKnown(flags)) {
return sink;
} else if (StreamOpFlag.SORTED.isKnown(flags)) {
return new Sink.ChainedReference<T, T>(sink) {
boolean seenNull;
T lastSeen;
@Override
public void begin(long size) {
seenNull = false;
lastSeen = null;
downstream.begin(-1);
}
@Override
public void end() {
seenNull = false;
lastSeen = null;
downstream.end();
}
@Override
public void accept(T t) {
if (t == null) {
if (!seenNull) {
seenNull = true;
downstream.accept(lastSeen = null);
}
} else if (lastSeen == null || !t.equals(lastSeen)) {
downstream.accept(lastSeen = t);
}
}
};
} else {
return new Sink.ChainedReference<T, T>(sink) {
Set<T> seen;
@Override
public void begin(long size) {
seen = new HashSet<>();
downstream.begin(-1);
}
@Override
public void end() {
seen = null;
downstream.end();
}
@Override
public void accept(T t) {
if (!seen.contains(t)) {
seen.add(t);
downstream.accept(t);
}
}
};
}
}
};
}总结:
-
使用 HashSet 进行去重:当调用
distinct()时,流会为每个元素调用hashCode()和equals()方法,并尝试将它们添加到一个内部的HashSet中。由于HashSet不允许重复元素,因此任何重复的元素(根据它们的hashCode()和equals()结果判断)都不会被添加进去。 -
有状态的中间操作:
distinct()是一个有状态的中间操作,意味着它在处理过程中需要维护一些内部状态(即上述的HashSet),这会影响到并行处理的策略。 -
稳定性:在有序流中,
distinct()的行为是稳定的,即它会保留第一个出现的元素实例。而在无序流中,由于并行处理或实现细节,保留的元素实例可能会有所不同,尽管从语义上讲结果流应包含相同的不同元素集。 -
性能考量:由于使用了
HashSet,整体的时间复杂度通常为 O(n),其中 n 是流中元素的数量。但这也依赖于hashCode()的实现质量,好的hashCode()分布能减少碰撞,提高效率。
事故:
项目中有这么一个工具类,把原对象转换成另一个对象列表,其中使用了Stream.distinct()进行对象去重。
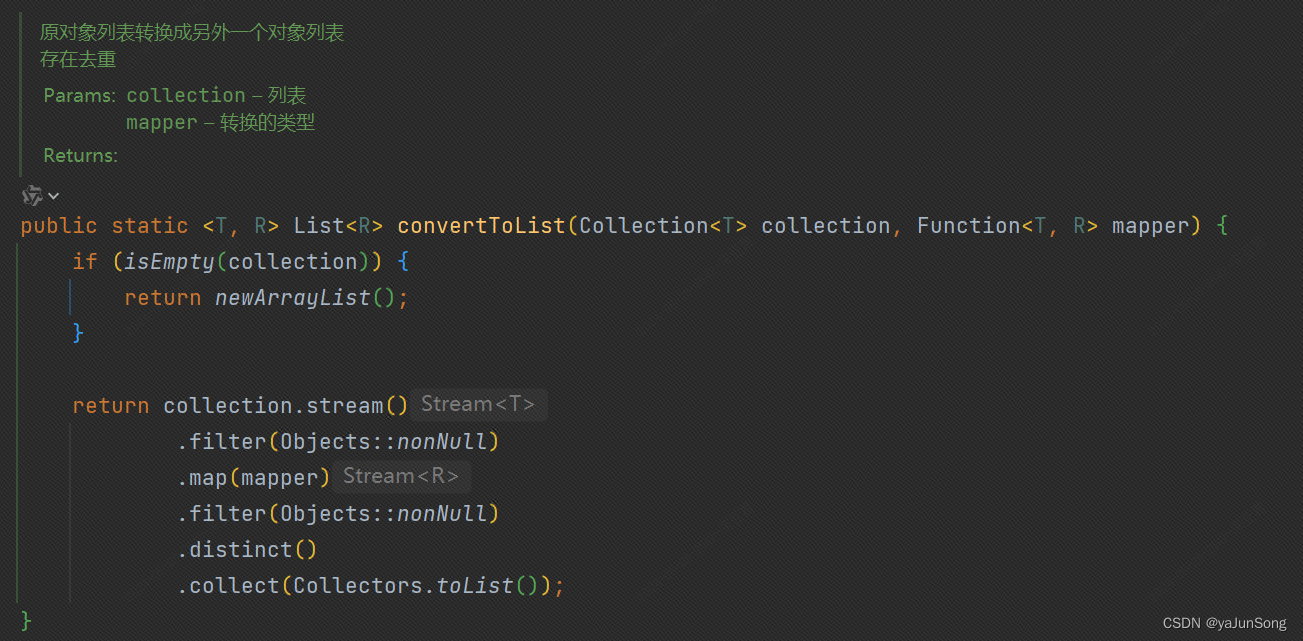
行为日志数据转换过程中,发现有数据被过滤掉,多次debug发现源数据是有xx条,通过工具转换后发现xx-yy条,数据条数发生了变化,导致结果出现了偏差。
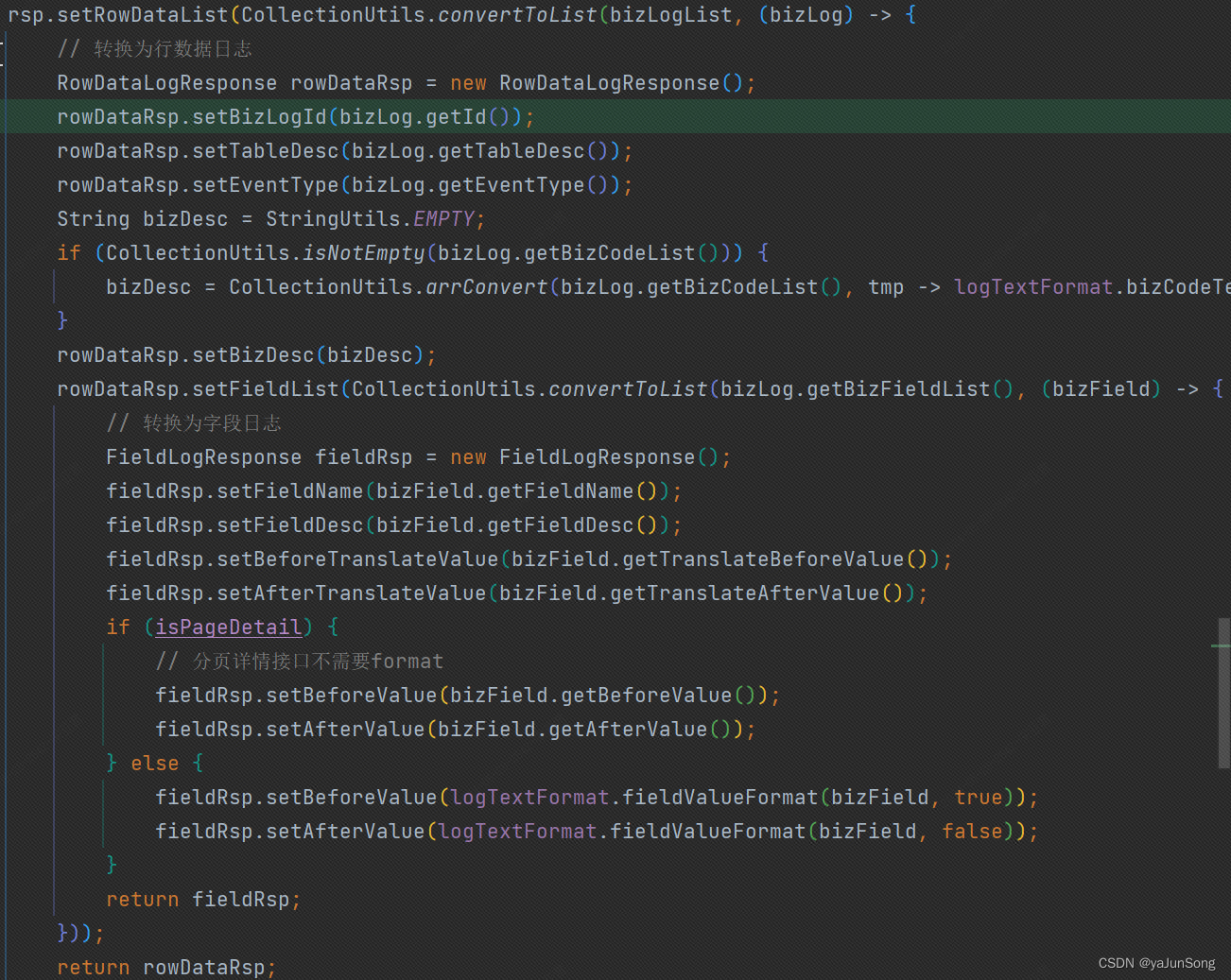
解决:
结合对Stream.distinct()源码的分析,去重基于 hashCode() 和 equals() 结果判断,如果进行重写,那么所有元素都将会不相同,背离业务场景,通过新增

保障业务的可用性,技术没有好坏前提是必须要满足业务场景使用!















 1036
1036

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









