






摘要
我们提出了一种通过神经网络生成超过数千个单词的长文档的文本摘要的方法。在生成摘要之前,我们执行一个简单的抽取步骤,然后将其用于根据相关信息对transformer语言模型进行条件调整,然后再负责生成摘要。实验表明,该抽取步骤显着改善了摘要结果。我们还表明,与以前采用复制机制的工作相比,该方法产生的摘要更多,同时仍然获得更高的rouge分数。注意:上面的摘要不是由作者编写的,它是根据本文提出的模型之一生成的。
1.介绍
语言模型(LM)经过大量文本语料训练,可以用于估计任意单词或字符序列的联合概率。它们通常将字符序列的联合概率分布
p
(
x
1
,
x
2
.
.
.
x
n
)
p(x_1,x_2...x_n)
p(x1,x2...xn)分解为条件概率
∏
i
n
p
(
x
i
∣
x
<
i
)
\prod^n_ip(x_i|x<i)
∏inp(xi∣x<i)的乘积。可以使用基于n-gram的模型,根据马尔可夫假设,通过计数来估计这些条件概率。但是,马尔可夫假设和维度灾难使n-gram LM难以建模远距离依赖关系,并难以学习序列中单词之间相似度的平滑函数。由于它们能够学习表达性条件概率分布,这导致近年来倾向于使用循环或前馈神经语言模型。
序列到序列(seq2seq)语言模型学习在给定一个序列的条件下输出另一个序列的概率。在这里,语言模型充当“解码器”,通常以编码器神经网络产生的输入序列的表示为条件。这些类型的编码器/解码器体系结构在应用于机器翻译和文本摘要等问题时特别成功。编码器和条件解码器语言模型通常被参数化为循环神经网络(RNN)。解码器中使用了注意力机制,以对编码器产生的表示提供更多的信息条件,并简化梯度流向编码器的过程。但是,RNN受其顺序性质的限制,这使它们1)难以优化和学习具有长距离依赖的长序列,并且2)难以在GPU等现代硬件上并行化,从而限制了它们的可扩展性。
因此,最近发生了向序列数据前馈体系结构的转变,例如卷积模型或被称为transformers的被广泛使用的全注意力模型。 这些技术在网络的输出与其任何输入之间具有对数或恒定的路径长度(与RNN中的线性相对),从而使梯度流变得更加容易,从而为学习远距离依赖提供了可能性。
新闻或科学论文的文本摘要通常需要编码并生成数百或数千个单词。GPT-2的最新工作表明,具有大接收域并接受了大量数据训练的transformers产生了能够捕获远距离依赖性的语言模型。
如果要创建长文档连贯的,高质量的摘要,则类似GPT的体系结构将具有许多理想的属性。他们的研究结果还表明,无条件语言模型可以隐式学习作为对其进行训练数据的结果来执行摘要或机器翻译。如果将数据格式化为文档的不同方面(简介,正文,摘要),每个方面都除以“ tl; dr”,则可以诱使模型生成这些方面之一。例如,可以通过在测试时提供类似格式的数据来使模型解决摘要任务;即后跟“ tl;dr”的文档简介和正文,它将根据这种情况生成来自语言模型的摘要。
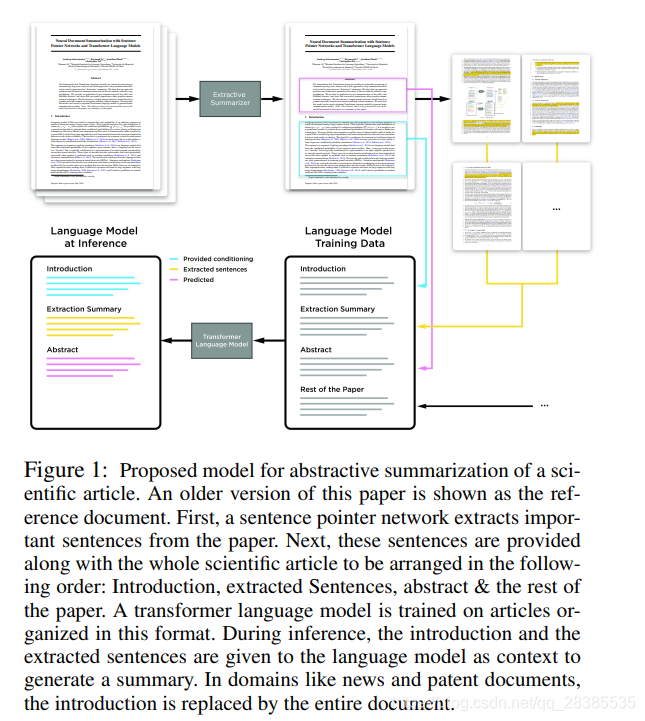
在这项工作中,我们采取了进一步的措施,取消了序列到序列框架,并格式化数据以进行文本摘要,以使transformer语言模型可以利用文档及其摘要中存在的所有可用数据(类似于机器翻译中单语数据的语言模型预训练)。具体来说,我们使用单个GPT式的Transformer LM(TLM),该LM在文档及其对应摘要数据上进行了训练。在推论过程中,我们以文档为条件从LM生成摘要(请参见图1)。与大多数以前的神经文本摘要方法不同,我们不使用带有显式编码器和解码器的seq2seq模型来生成单词。我们将任务分为两个步骤:抽取步骤和生成步骤。为了处理超过数千个单词的超长文档,我们首先使用两种不同的分层文档模型执行句子抽取:一种基于指针网络,类似于(Chen and Bansal 2018) 中提出的变体;另一个基于句子分类器。这从文档中抽取了重要的句子(在本节中进行了描述),这些句子可用于在执行摘要之前,根据相关信息更好地调节transformer LM。我们表明,该抽取步骤显着改善了摘要结果。
这项工作的贡献有两个方面:
- 我们证明,即使没有复制机制,transformer语言模型也可以有效地总结较长的科学文章,并且优于典型的seq2seq方法。
- 我们证明,与使用复制机制的先前工作相比,我们的方法产生了更多的摘要,同时仍获得了较高的ROUGE分数。
2.相关工作
自动摘要系统旨在在保留大部分重要信息和语义的同时压缩文本的大小。最早的自动摘要尝试着重于抽取技术,该技术可在文档中找到其最重要内容的单词或句子。过去,基于特定句子特征(关键字,位置,长度,频率,语言)和度量(基于结构,基于矢量和基于图的)的各种相似性评分用于估计文档中的句子及其参考摘要之间的显着性。最近,随着单词,短语和句子的分布式表示的发展,研究人员提出了使用它们来计算相似性分数的方法。(Nallapati, Zhou, and Ma 2016; Cheng and Lapata 2016; Chen and Bansal 2018) 使用编码器-解码器体系结构进一步完善了此类技术-编码器学习的表示用于选择最显着的句子。(Cheng and Lapata 2016) and (Nallapati, Zhou, and Ma 2016) 将编码器-解码器神经网络训练为二分类器,以确定文档中的每个句子是否应属于抽取性摘要。 (Nallapati et al. 2016) 也提出了一种替代方案,可以从源文档中选择无序的句子集合来构成摘要。(Chen and Bansal 2018) 使用指针网络从文档中依次抽取构成其摘要的句子。
人类生成的摘要具有四个共同的特征:(1)解释源文档,(2)区分输入文本的最重要部分的优先级,(3)将关键概念释义为连贯的段落,以及(4)生成各种输出摘要。尽管抽取方法可以说非常适合于识别最相关的信息,但此类技术可能缺乏人为生成的摘要的流利性和连贯性。生成式摘要显示了针对上述第(3)和(4)点的最大有点。摘要生成可能会产生原始输入文档中看不到的句子。由于神经网络在机器翻译实验中取得了成功,基于注意力的编码器-解码器框架最近在文本摘要中得到了广泛的研究。通过在输出序列生成期间基于解码器的隐藏状态动态访问相关信息,模型可以重新访问输入并关注重要信息。抽取,生成和基于注意力的模型的优点首先在 (Gu et al. 2016) 中与源文档中出现的OOV单词的复制机制结合在一起。同样, (See, Liu, and Manning 2017) 使用注意力得分来计算单词生成与复制的概率。还添加了一种覆盖机制,以惩罚以前参加过的单词的注意力得分,从而减少了模型重复生成的趋势。
3.框架
我们的模型包括两个截然不同且可独立训练的组件:1)分层文档表示模型,该模型指向或分类文档中的句子以构建抽取式摘要;2)Transformer语言模型,其以抽取出的句子以及整个文档为条件输入。
3.1 抽取模型
我们将在本节中描述在这项工作中使用的两个神经抽取模型。
(1)分层的Seq2Seq句子级指针网络
我们的抽取模型类似于(Chen and Bansal 2018)开发的句子指针架构,主要区别在于编码器的选择。我们使用具有单词和句子级别LSTM的分层双向LSTM编码器,而(Chen and Bansal 2018)使用卷积词级别编码器来加快训练和推理速度。 两种情况下的解码器都是LSTM。
抽取模型将文档视为由
N
N
N个句子组成的列表
D
=
(
S
1
,
.
.
.
,
S
N
)
D=(S_1,...,S_N)
D=(S1,...,SN),并将其中的每个句子视为字符列表。我们给出了由
M
M
M个句子组成的真实抽取摘要
(
S
i
1
,
.
.
.
,
S
i
M
)
(S_{i_1},...,S_{i_M})
(Si1,...,SiM),其中
i
1
<
.
.
.
<
i
M
i_1 <...<i_M
i1<...<iM是抽取的句子的索引。确定真实抽取目标的过程与之前的工作相同-在文档中找到与摘要中的每个句子ROUGE得分最高的句子。
我们为此抽取器使用编码器-解码器体系结构。
编码器具有将字符和句子级RNN组合在一起的分层结构。首先,“sentence-encoder”或字符级RNN是对每个句子进行编码的双向LSTM。从两个方向来看,最后一层的最后一个隐藏状态会产生句子嵌入:
(
s
1
,
.
.
.
,
s
N
)
(\textbf s_1,...,\textbf s_N)
(s1,...,sN),其中
N
N
N是文档中句子的数量。句子级别的LSTM或另一个双向LSTM的“document encoder”对该句子嵌入序列进行编码,以生成文档表示形式:
(
d
1
,
.
.
.
,
d
N
)
(\textbf d_1,...,\textbf d_N)
(d1,...,dN)。
解码器是一种自回归LSTM,它将先前提取的句子的句子级LSTM隐藏状态作为输入并预测下一个提取的句子。设
i
t
i_t
it为时刻
t
t
t之前抽取的句子的索引。解码器的输入为
s
i
t
s_{i_t}
sit或在时间步
t
=
0
t=0
t=0时为零向量。解码器的输出是通过注意力机制根据文档表示
(
d
1
,
.
.
.
,
d
N
)
(d_1,...,d_N)
(d1,...,dN)以及解码器的隐藏状态
h
t
h_t
ht来计算的。我们使用了 (Luong, Pham, and Manning
2015) 中的点积注意力方法。注意力权重
a
t
\textbf a_t
at产生上下文向量
c
t
\textbf c_t
ct,其随后被用于计算基于注意力的隐藏状态
h
~
t
\tilde \textbf{h}_t
h~t。遵循 (Luong, Pham, and Manning 2015) 的输入馈送方法,在下一个时刻中将基于注意力的隐藏状态
h
~
t
\tilde \textbf{h}_t
h~t连接到输入,给出以下循环形式
h
t
=
L
S
T
M
(
[
s
i
t
T
,
h
~
t
−
1
T
]
T
,
h
t
−
1
)
\textbf h_t=LSTM([\textbf s^T_{i_t},\tilde {\textbf h}^T_{t-1}]^T,\textbf h_{t−1})
ht=LSTM([sitT,h~t−1T]T,ht−1),其中:
h
~
t
=
W
h
~
[
c
t
h
t
]
,
c
t
=
∑
i
=
1
N
a
t
(
i
)
d
i
,
α
t
(
i
)
=
d
i
T
h
t
,
(1)
\tilde \textbf{h}_t=\textbf W_{\tilde h} \left[ \begin{matrix} \textbf c_t \\ \textbf h_t \end{matrix} \right],\quad \textbf c_t=\sum^N_{i=1}a_t(i)\textbf d_i, \quad \alpha_t(i)=\textbf d^T_i\textbf h_t,\tag{1}
h~t=Wh~[ctht],ct=i=1∑Nat(i)di,αt(i)=diTht,(1)
a
t
(
i
)
=
e
x
p
(
α
t
(
i
)
)
∑
i
′
e
x
p
(
α
t
(
i
′
)
)
,
f
o
r
i
=
1..
N
.
(2)
a_t(i)=\frac{exp(\alpha_t(i))}{\sum_{i'}exp(\alpha_t(i'))},\quad for\quad i=1..N.\tag{2}
at(i)=∑i′exp(αt(i′))exp(αt(i)),fori=1..N.(2)
注意力权重用作文档句子的输出概率分布,用于抽取下一个句子。我们约定,通过将相同的句子索引连续两次抽取来表示结束。因此,解码器的输入为以下序列:
0
,
s
i
1
,
.
.
.
,
s
i
M
\textbf 0,s_{i_1},...,s_{i_M}
0,si1,...,siM,输出为:
i
1
,
.
.
.
,
i
M
,
i
M
i_1,...,i_M,i_M
i1,...,iM,iM,其中
M
M
M是抽取的摘要的长度,两个序列都具有
M
+
1
M+1
M+1个元素。训练模型以最小化在每个解码器时刻选择正确句子的交叉熵。推断时,我们使用集束搜索来生成抽取的摘要。
(2)句子级分类器
与指针网络一样,我们使用分层LSTM对文档进行编码,并生成一系列句子表示
d
1
,
.
.
.
,
d
N
d_1,...,d_N
d1,...,dN,其中
N
N
N是文档中句子的数量。我们计算最终文档表示如下:
d
=
t
a
n
h
(
b
d
+
W
d
1
N
∑
i
=
1
N
d
i
)
(3)
\textbf d=tanh(\textbf b_d+\textbf W_d\frac{1}{N}\sum^N_{i=1}\textbf d_i)\tag{3}
d=tanh(bd+WdN1i=1∑Ndi)(3)
其中
b
d
\textbf b_d
bd和
W
d
\textbf W_d
Wd是可学习的参数。最后,每个句子属于摘要的概率由下式给出:
o
i
=
σ
(
W
o
[
d
i
d
]
+
b
o
)
(4)
o_i=\sigma(\textbf W_o\left[ \begin{matrix} \textbf d_i \\ \textbf d \end{matrix} \right]+\textbf b_o)\tag{4}
oi=σ(Wo[did]+bo)(4)
其中
σ
σ
σ是sigmoid激活函数。训练模型以使真实抽取摘要中的句子的二进制交叉熵损失最小。
(3)模型细节
模型使用大小为300的单词嵌入。字符级LSTM(句子编码器),句子级LSTM(文档编码器)和解码器分别具有2个512单元的层,并且在每个中间层的输出处施加0.5的dropout。我们使用Adam训练了该模型,学习率0.001,权重衰减为10−5,batch sizes为32。我们每200次更新对模型进行一次评估,耐心值为50。推断时,我们使用集束搜索对指针模型进行解码,其中beam size大小为4,对于句子分类器,从中选择k个最可能的句子,其中
k
k
k是整个训练数据集摘要中句子的平均数量。
3.2 Transformer语言模型(TLM)
我们没有使用编码器-解码器体系结构将文本摘要表示为seq2seq问题,而是仅使用从头开始训练的单个Transformer语言模型,并带有适当的“格式化”数据(参见图1,我们还将在本节稍后描述格式化数据)。
我们使用与 (Radford et al. 2019) 相同的Transformer语言模型(TLM)结构。我们的模型具有220M参数,20层,768维嵌入,3072维逐元素MLP和12个注意力头。在我们的网络结构中,唯一的区别是我们不会在初始化时缩放权重。 我们在单个Nvidia DGX-2盒子上的16个V100 GPU上训练了5天的语言模型。在前40,000个更新中,我们使用了线性加速学习率计划,最大学习速率为
2.5
×
e
−
4
2.5×e^{-4}
2.5×e−4,然后使用Adam优化器在接下来的200,000个步骤中使用cosine学习率下降。我们使用了混合精度训练,batch size为256个序列,每个序列1024个字符。
为了获得无条件语言模型进行文本摘要,我们可以利用以下事实:通过对词的联合分布进行自回归分解来训练LM。我们组织了LM的训练数据,以使真实摘要遵循模型所使用的信息来生成系统摘要。这样,我们在训练期间对文档和摘要的联合分布进行建模,并在推断时从给定文档的摘要的条件分布中采样。
当处理很长的文档时,可能不适合使用Transformer语言模型所看到的单个字符窗口,例如整篇科学文章,我们将其introduction作为代理,以获取足够的信息来生成摘要,并使用本文的其余部分作为领域内的语言模型训练数据(图1)。在这种情况下,我们按以下方式组织arXiv和PubMed数据集:1)论文introduction;2)从句子指针模型中抽取的句子;3)摘要4)本文的其余部分。在其他数据集上,论文introduction将是整个文档,而不包含本文的其余部分。这确保了推断时,我们可以为语言模型提供论文introduction和抽取的句子作为生成摘要的条件。我们发现,在训练过程中使用真实抽取的句子,推理中使用模型提取的句子比在训练时使用模型抽取的句子效果更好。
我们使用一个特殊的字符来表示摘要的开始,并在测试时使用它来向模型发送信号以开始生成摘要。本文的其余部分将作为LM的领域内训练数据提供。整个数据集被细分为每个1,024个字符的不重叠示例。我们在推论中使用“ top-k”采样,
k
=
30
k=30
k=30,softmax temperature为0.7,以生成摘要。














 659
659











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









