






 CogView通过40亿参数的Transformer和VQ-VAE tokenizer解决通用领域文本到图像生成难题。论文详述了预训练策略、微调应用及稳定训练方法,包括风格学习、超分辨率、文本图像排名和时装设计,且在模糊MSCOCO上刷新FID指标。
CogView通过40亿参数的Transformer和VQ-VAE tokenizer解决通用领域文本到图像生成难题。论文详述了预训练策略、微调应用及稳定训练方法,包括风格学习、超分辨率、文本图像排名和时装设计,且在模糊MSCOCO上刷新FID指标。
摘要
通用领域中的 Text-to-Image 生成长期以来一直是一个开放的问题,它需要强大的生成模型和跨模态理解。 我们提出了 CogView,一个 40 亿参数的 Transformer,带有 VQ-VAE tokenizer来解决这个问题。 我们展示了其在各种下游任务的微调策略,例如 风格学习、超分辨率、文本图像排名和时装设计,并且还提出了稳定预训练的方法,例如。 消除 NaN 损失。CogView(zero-shot)在模糊 MS COCO 上实现了新的最先进的 FID,优于以前的基于 GAN 的模型和最近的类似工作 DALL-E。
1.介绍


由于对比自监督预训练方法已经彻底改变了计算机视觉 (CV),为图像带来高级语义的视觉语言预训练正在成为视觉理解的下一个前沿。在各种基于文本的任务中,text-to-image生成期望模型能够:(1)从像素中分解出形状、颜色、手势和其他特征,(2)将对象和特征与相应的单词及其同义词对齐,(3)理解输入 ,(4) 学习复杂的分布,生成不同对象和特征的重叠和组合,这和绘画一样,已经超出了基本的视觉功能(与眼睛和大脑中的 V1-V4 相关),代表更高层次的认知能力 (更多与大脑中的角回有关)。
教会机器从文本生成图像的尝试可以追溯到深度生成模型的早期,当时 Mansimov et al. 将文本信息添加到 DRAW中。 接下来,生成对抗网络 (GAN) 开始主导这项任务。Reed et al. 将文本嵌入作为额外输入提供给生成器和判别器。StackGAN 将生成分解为 sketch-refinement 过程。AttnGAN使用了对单词的注意力来关注相应的子区域。ObjectGAN 按照文本→框→布局→图像过程来生成图像。DM-GAN 和 DF-GAN 引入了新的架构,例如 动态记忆或深度融合块,以获得更好的图像细化。尽管这些基于 GAN 的模型可以在简单且特定领域的数据集中进行合理的合成,例如 Caltech-UCSD Birds 200 (CUB),然而在复杂和领域无关的场景中,例如 MS COCO,生成的结果总是差强人意。
近年来,自回归生成模型开始兴起。Generative Pre-Training(GPT)模型利用 Transformers 在大规模语料库中学习一个语言模型,极大地提升了自然语言生成和小样本语言理解的性能。自回归模型在 CV 中并不是最新提出的。PixelCNN、PixelRNN 和 Image Transformer 使用不同的网络结构对图像的子像素(像素中的颜色通道)上的概率密度函数进行分解,显示出有希望的结果。然而,真实图像通常包含数百万个子像素,这表明大型模型的计算量是难以承受的。即使是最大的像素级自回归模型 ImageGPT,也在 ImageNet 上以 96 × 96 的最大分辨率进行了预训练。
Vector Quantized Variational AutoEncoders (VQ-VAE) 框架缓解了这个问题。VQ-VAE 训练一个编码器将图像压缩到一个低维离散潜在空间,在第 1 阶段,一个解码器从隐藏变量中恢复图像。然后在第 2 阶段,一个自回归模型(如 PixelCNN ) 学习拟合隐藏变量的先验。 这种离散压缩方法比直接下采样损失更少的保真度,同时保持像素的空间相关性。因此,VQ-VAE 重振了 CV 中的自回归模型。 遵循这个框架,Esser et al. 使用 Transformer 来拟合先验以及解码器训练中从 L2 loss 到 GAN loss 的进一步切换,大大提高了特定领域无条件生成的性能。
我们的 CogView 的想法非常简单:文本和图像(来自 VQ-VAE)tokens 的大规模生成联合预训练。我们收集了 3000 万个高质量(中文)文本-图像对,并用 40 亿参数预训练了一个 Transformer。然而,由于数据的异质性,大规模的文本到图像生成预训练可能非常不稳定。我们系统地分析了原因并通过提出的 Precision Bottleneck Relaxation 和 Sandwich Layernorm 解决了这个问题。因此,CogView 极大地提高了文本到图像生成的质量。
最近的一个作品 DALL-E 独立提出了同样的想法,并且比 CogView 更早发布。与DALL-E相比,CogView有以下四个方面的改进:
- 根据blurred MS COCO 上的 Fréchet Inception Distance (FID),CogView 在很大程度上优于 DALL-E 和以前的基于 GAN 的方法,并且是第一个开源的大型文本到图像transformer。
- 除了zero-shot生成之外,我们还进一步研究了微调预训练 CogView 的潜力。CogView 可以适应各种下游任务,例如风格学习(特定领域的文本到图像)、超分辨率(图像到图像)、图像字幕(图像到文本),甚至文本图像重排名。
- 微调的 CogView 支持在选择后进行自我重新排序,并在 DALL-E 中摆脱了额外的 CLIP 模型。它还提供了一个新的指标 Caption Score,以比 FID 和 Inception Score (IS) 更精细的粒度来衡量文本图像生成的质量和准确性。
- 由于我们简单有效的 PB-relaxation 和 Sandwich-LN,CogView 是第一个用 FP16 (O22) 训练的大型文本到图像transformer。这些技术可以消除forward中的溢出(表征为 NaN 损失),以稳定训练,并且可以推广到其他transformers的训练。
2.方法
2.1 理论
在本节中,我们将从 VAE 推导出 CogView 的理论:CogView 优化了图像和文本联合似然的置信下界 (ELBO)。如果没有文本
t
\textbf t
t,以下推导也变成了对 VQ-VAE 的重新解释。
假设数据集
(
X
,
T
)
=
{
x
i
,
t
i
}
i
=
1
N
(\textbf X, \textbf T)=\{x_i, t_i\}^N_{i=1}
(X,T)={xi,ti}i=1N,由 N 个独立同分布的图像变量
x
\textbf x
x及其描述文本变量
t
\textbf t
t的样本组成。我们假设图像
x
\textbf x
x可以通过涉及潜在变量
z
z
z的随机过程生成:(1)
t
i
t_i
ti首先从先验
p
(
t
;
θ
)
p(\textbf t;θ)
p(t;θ) 生成。(2)然后从条件分布
p
(
z
∣
t
=
t
i
;
θ
)
p(\textbf z|\textbf t=t_i; θ)
p(z∣t=ti;θ)中生成
z
i
z_i
zi。(3)
x
i
x_i
xi最终由
p
(
x
∣
z
=
z
i
;
ψ
)
p(\textbf x|\textbf z=z_i; ψ)
p(x∣z=zi;ψ) 生成。我们在下面的部分中使用像
p
(
x
i
)
p(x_i)
p(xi) 这样的简写形式来指代
p
(
x
=
x
i
)
p(\textbf x=x_i)
p(x=xi)。
设
q
(
z
∣
x
i
;
φ
)
q(\textbf z|x_i; φ)
q(z∣xi;φ) 是变分分布,它是 VAE 中编码器
ϕ
\phi
ϕ 的输出。对数似然和置信下界(ELBO)可以写成:
l
o
g
p
(
X
,
T
,
θ
,
ψ
)
=
∑
i
=
1
N
l
o
g
p
(
t
i
;
θ
)
+
∑
i
=
1
N
l
o
g
p
(
x
i
∣
t
i
;
θ
,
ψ
)
(1)
log~p(X,T,\theta,\psi)=\sum^N_{i=1}log~p(t_i;\theta)+\sum^N_{i=1}log~p(x_i|t_i;\theta,\psi)\tag{1}
log p(X,T,θ,ψ)=i=1∑Nlog p(ti;θ)+i=1∑Nlog p(xi∣ti;θ,ψ)(1)
≥
−
∑
i
=
1
N
(
−
l
o
g
p
(
t
i
;
θ
)
⏟
N
L
L
l
o
s
s
f
o
r
t
e
x
t
+
E
z
i
∼
q
(
z
∣
x
i
,
ϕ
)
[
−
l
o
g
p
(
x
i
∣
z
i
;
ψ
)
]
⏟
r
e
c
o
n
s
t
r
u
c
t
i
o
n
l
o
s
s
+
K
L
(
q
(
z
∣
x
i
;
ϕ
)
∣
∣
p
(
z
;
t
i
;
θ
)
)
⏟
K
L
b
e
t
w
e
e
n
q
a
n
d
(
t
e
x
t
c
o
n
d
i
t
i
o
n
a
l
)
p
r
i
o
r
)
.
(2)
\ge -\sum^N_{i=1}\bigg (\underbrace{-log~p(t_i;\theta)}_{NLL~loss~for~text}+\underbrace{\mathop{\mathbb E}\limits_{z_i\sim q(\textbf z|x_i,\phi)}[-log~p(x_i|z_i;\psi)]}_{reconstruction~loss}+\underbrace{KL\big (q(\textbf z|x_i;\phi)||p(\textbf z;t_i;\theta)\big )}_{KL~between~q~and~(text~conditional)~prior}\bigg ).\tag{2}
≥−i=1∑N(NLL loss for text
−log p(ti;θ)+reconstruction loss
zi∼q(z∣xi,ϕ)E[−log p(xi∣zi;ψ)]+KL between q and (text conditional) prior
KL(q(z∣xi;ϕ)∣∣p(z;ti;θ))).(2)
VQ-VAE 的框架与传统 VAE 的不同主要在于 KL 项。传统的 VAE 通常将先验
p
(
z
∣
t
i
;
θ
)
p(\textbf z|t_i;θ)
p(z∣ti;θ) 固定为
N
(
0
,
I
)
\mathcal N(0,I)
N(0,I),并学习编码器
ϕ
\phi
ϕ。然而,它会导致 posterior collaps,这意味着
q
(
z
∣
x
i
;
ϕ
)
q(\textbf z|x_i;\phi)
q(z∣xi;ϕ) 有时会沿着先验崩溃。VQ-VAE 固定
ϕ
\phi
ϕ 并用另一个由
θ
θ
θ 参数化的模型拟合先验
p
(
z
∣
t
i
;
θ
)
p(\textbf z|t_i;θ)
p(z∣ti;θ)。这种技术消除了posterior collaps,因为编码器
ϕ
\phi
ϕ 现在只更新以优化重建损失。作为交换,对于不同的
x
i
x_i
xi,近似后验
q
(
z
∣
x
i
;
ϕ
)
q(\textbf z|x_i;\phi)
q(z∣xi;ϕ) 可能非常不同,所以我们需要一个非常强大的
p
(
z
∣
t
i
;
θ
)
p(\textbf z|t_i;θ)
p(z∣ti;θ) 模型来最小化 KL 项。
目前,最强大的生成式模型Transforme(GPT),是通过在离散字典上生成tokens序列来使用的。为了使用它,我们使得
z
∈
{
0
,
.
.
.
,
∣
v
∣
−
1
}
h
×
w
z\in \{0,...,|v|-1\}^{h\times w}
z∈{0,...,∣v∣−1}h×w,其中
∣
v
∣
|v|
∣v∣是字典的大小,
h
×
w
h×w
h×w是
z
\textbf z
z的维度。序列
z
i
s
z_is
zis可以从
q
(
z
∣
x
i
;
ϕ
)
q(\textbf z|x_i;\phi)
q(z∣xi;ϕ)中取样,或直接
z
i
=
a
r
g
m
a
x
z
q
(
z
∣
x
i
;
ϕ
)
z_i=argmax_z q(\textbf z|x_i;\phi)
zi=argmaxzq(z∣xi;ϕ)。为了简单起见,我们选择后者,因此
q
(
z
∣
x
i
;
ϕ
)
q(\textbf z|x_i;\phi)
q(z∣xi;ϕ)成为
z
i
z_i
zi的单点分布。等式(2)可以重写为:
−
∑
i
=
1
N
(
E
z
i
∼
q
(
z
∣
x
i
,
ϕ
)
[
−
l
o
g
p
(
x
i
∣
z
i
;
ψ
)
]
⏟
r
e
c
o
n
s
t
r
u
c
t
i
o
n
l
o
s
s
−
l
o
g
p
(
t
i
;
θ
)
⏟
N
L
L
l
o
s
s
f
o
r
t
e
x
t
−
l
o
g
p
(
z
i
∣
t
i
;
θ
)
⏟
N
L
L
l
o
s
s
f
o
r
z
)
.
(3)
-\sum^N_{i=1}\bigg (\underbrace{\mathop{\mathbb E}\limits_{z_i\sim q(\textbf z|x_i,\phi)}[-log~p(x_i|z_i;\psi)]}_{reconstruction~loss}\underbrace{-log~p(t_i;\theta)}_{NLL~loss~for~text}\underbrace{-log~p(z_i|t_i;\theta)}_{NLL~loss~for~\textbf z}\bigg ).\tag{3}
−i=1∑N(reconstruction loss
zi∼q(z∣xi,ϕ)E[−log p(xi∣zi;ψ)]NLL loss for text
−log p(ti;θ)NLL loss for z
−log p(zi∣ti;θ)).(3)
然后,可以将学习过程分为两个阶段:(1)学习编码器
ϕ
\phi
ϕ和解码器
ψ
\psi
ψ以最小化重构损失;(2)单个GPT通过将文本
t
i
t_i
ti和
z
i
z_i
zi作为输入序列来优化两个负对数似然(NLL)损失。
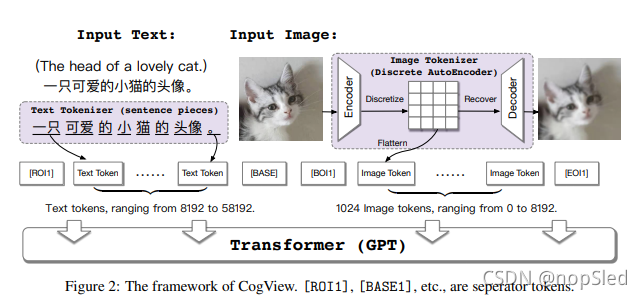
因此,第一阶段简化为纯离散的自编码器,以作为 image tokenizer 将图像转换为字符序列;第二阶段的GPT承担了大部分建模任务。图2说明了Cogview的框架。
2.2 Tokenization
在本节中,我们将介绍有关文本和图像tokenizer的详细信息。
关于文本的tokenizer已经有很好地研究,例如, BPE和SentencePiece。在Cogview中,我们在大型汉语语料库上运行SentencePiece,以提取50000大小的tokens。
关于图像的tokenizer是一个离散的自编码器,其类似于VQ-VAE或D-VAE的第1阶段。更具体地,编码器
ϕ
\phi
ϕ将形状为
H
×
W
×
3
H×W×3
H×W×3的图像
x
x
x映射到形状为
h
×
w
×
d
h×w×d
h×w×d的
E
n
c
ϕ
(
x
)
Enc_{\phi}(x)
Encϕ(x)中,然后将每个
d
d
d维向量量化为可学习字典
{
v
0
,
.
.
.
,
v
∣
V
∣
−
1
}
,
∀
v
k
∈
R
d
\{v_0, ...,v_{|V|-1}\},\forall v_k∈\mathbb R^d
{v0,...,v∣V∣−1},∀vk∈Rd中的邻近嵌入。量化结果可以由
h
×
w
h\times w
h×w的嵌入索引表示,然后我们得到潜在的变量
z
∈
{
0
,
.
.
.
,
∣
V
∣
−
1
}
h
×
w
\textbf z\in \{0,...,|V|-1\} ^{h×w}
z∈{0,...,∣V∣−1}h×w。解码器
ψ
\psi
ψ将量化向量映射回(模糊的)图像以重建输入。在我们的具有4B参数的Cogview中,
∣
V
∣
=
8192
,
d
=
256
,
H
=
W
=
256
,
h
=
w
=
32
|V|=8192,d=256,H=W=256,h=w=32
∣V∣=8192,d=256,H=W=256,h=w=32。
由于涉及离散选择,图像tokenizer的训练是非常重要的**。在这里,我们介绍了三种方法来训练图像tokenizer**。
第一种方法是the nearest-neighbor mapping, straight-through estimator,由原始VQVAE提出。这种方法关注的是,当字典大而没有较好地初始化时,由于维度的灾难,只会使用较小的嵌入。我们在实验中没有观察到这种现象。
第二种方法是Gumbel sampling, straight-through estimator。如果我们遵循原始VAE中基于矢量之间距离,来重参数化潜在变量
z
\textbf z
z的类别分布(即
p
(
z
i
×
w
+
j
=
v
k
∣
x
)
=
e
−
∣
∣
v
k
−
E
n
c
ϕ
(
x
)
i
j
∣
∣
2
/
τ
∑
k
=
0
∣
V
∣
−
1
e
−
∣
∣
v
k
−
E
n
c
ϕ
(
x
)
i
j
∣
∣
2
/
t
a
u
p(\textbf z_{i\times w+j}=v_k|x)=\frac{e^{-||v_k-Enc_{\phi}(x)_{ij}||_{2/\tau}}}{\sum^{|V|-1}_{k=0}e^{-||v_k-Enc_{\phi}(x)_{ij}||_{2/tau}}}
p(zi×w+j=vk∣x)=∑k=0∣V∣−1e−∣∣vk−Encϕ(x)ij∣∣2/taue−∣∣vk−Encϕ(x)ij∣∣2/τ),那么无偏差的采样策略是
z
i
×
w
+
j
=
a
r
g
m
a
x
k
g
k
−
∣
∣
v
k
−
E
n
c
ϕ
(
x
)
i
j
∣
∣
2
/
τ
,
g
k
〜
g
u
m
b
e
l
(
0
,
1
)
z_{i×w+j}=argmax_kg_k-||v_k-Enc_{\phi}(x)_{ij}||_{2/τ},g_k〜gumbel(0,1)
zi×w+j=argmaxkgk−∣∣vk−Encϕ(x)ij∣∣2/τ,gk〜gumbel(0,1),其中温度
τ
τ
τ逐渐降低到0。然后梯度可以通过直straight-through estimator来传播。
第三种方法是Gumbel sampling, softmax approximation。类似于第二种,但使用可分微分的softmax近似argmax的one-hot分布。DALL-E采用了这种方法,并使用了许多其他技巧才能稳定训练。
在我们的实验中,我们发现这三种方法基本相当,并且如果初始化适当,则字典中嵌入的学习不是必不可少的。我们可以定期将它们更新为量化向量的平均值,甚至固定它们。最后,我们使用第一种方法并简单地使用移动平均更新。
有关数据的介绍以及tokenization更多细节在附录A中。
2.3 Auto-regressive Transformer
CogView的主网络是单向Transformer(GPT)。Transformer有48层,隐藏的大小为2560,40个注意力头和40亿个参数。如图2所示,四个Seperator字符,
[
R
O
I
1
]
[ROI1]
[ROI1](reference text of image),
[
B
A
S
E
]
[BASE]
[BASE],
[
B
O
I
1
]
[BOI1]
[BOI1](beginning of image),
[
E
O
I
1
]
[EOI1]
[EOI1](end of image)被添加到每个序列中以指示文字和图像的边界。我们将所有序列裁剪或补全到1088的长度上。
预训练的pretext任务是从左到右预测字符,也称语言建模。图像和文本字符都以同样方式训练。DALL-E提出降低文本字符的损失权重。相反的是,在小规模数据的实验期间,我们惊奇地发现文本建模是文本到图像预训练成功的关键。如果文本字符的损失权重设置为零,则模型将无法在文本和图像之间找到连接,并生成与输入文本完全不相关的图像。我们假设文本建模抽象了隐藏层中的知识,可以在稍后的图像建模期间有效地利用。
我们用大小为6144条序列的btach(每btach为670万令牌)来训练模型,在512 V100 GPU(32GB)上的训练步数为144,000步。参数由adam更新,带有最大学习率
l
r
=
3
×
1
0
−
4
,
β
1
=
0.9
,
β
2
=
0.95
lr=3×10^{-4},β_1=0.9,β_2=0.95
lr=3×10−4,β1=0.9,β2=0.95,权重衰减
=
4
×
1
0
−
2
=4×10^{-2}
=4×10−2。学习率在前2%的步骤中warm up,并使用consine退火衰减。在适当的hyperparameters范围内,我们发现培训损失主要取决于训练的字符总数(tokens per batch × steps),这意味着训练了相同数量的字符导致非常相似的损失。因此,我们使用相对较大的batch-size来改善并行性,并降低通信时间的百分比。我们还设计了三个区域稀疏注意力,以加速训练,节省内存而不伤害性能,者在附录B中介绍。
2.4 Stabilization of training
目前,预训练的大型模型(> 2B参数)通常依赖于16位精度来保存GPU存储器并加快计算。许多框架,例如 DeepSpeed ZeRO,甚至只支持FP16参数。但是,在16位精度下,text-to-image任务预训练会非常不稳定。训练一个4B大小的传统Pre-LN Transformer将在1,000次迭代中快速导致NaN loss。稳定训练是Cogview最具挑战性的部分。
我们总结了Dall-E中解决训练过程中数值问题的方案。由于这些数值和梯度在不同层中急剧变化,因此它们提出了一种新的混合精度框架,per-resblock loss scaling,并将所有增益,偏差,嵌入和非嵌入以32位精度储存。此解决方案复杂,消耗额外的时间和内存,不受当前框架的支持。
cogview是通过对数值正规化来实现的。我们发现有两种不稳定性:溢出(表现为NaN loss)和下溢(表现为loss不收敛)。因此,我们提出了以下技术来解决这些技术。
Precision Bottleneck Relaxation (PB-Relax)。在分析模型训练之后,我们发现溢出始终发生在两个瓶颈操作中, final LayerNorm 或 attention 中。
- 在深层网络中,LayerNorm中输出的值可能会爆炸到 1 0 4 〜 1 0 5 10^4〜10^5 104〜105,从而导致溢出。幸运的是,令 L a y e r N o r m ( x ) = L a y e r N o r m ( x / m a x ( x ) ) LayerNorm(x)=LayerNorm(x/max(x)) LayerNorm(x)=LayerNorm(x/max(x)),我们可以通过除以 x x x的最大值来松弛这个瓶颈。
- 注意力分数
Q
T
K
/
d
Q^TK /\sqrt{d}
QTK/d可能明显大于输入元素,并导致溢出。将计算顺序更改为
Q
T
(
K
/
d
)
Q^T(K/\sqrt{d})
QT(K/d)能缓减该问题。为了消除溢出,我们注意到
s
o
f
t
m
a
x
(
Q
T
K
/
d
)
=
s
o
f
t
m
a
x
(
Q
T
K
/
d
−
c
o
n
s
t
a
n
t
)
softmax(Q^TK/\sqrt{d})=softmax(Q^TK/\sqrt{d}-constant)
softmax(QTK/d)=softmax(QTK/d−constant),这意味着我们可以将注意力变更为:
s o f t m a x ( Q T K d ) = s o f t m a x ( ( Q T α d K ) − m a x ( Q T α d K ) × α ) , (4) softmax(\frac{Q^TK}{\sqrt{d}})=softmax\bigg((\frac{Q^T}{\alpha \sqrt{d}}K)-max(\frac{Q^T}{\alpha \sqrt{d}}K)\times \alpha\bigg),\tag{4} softmax(dQTK)=softmax((αdQTK)−max(αdQTK)×α),(4)
其中 α α α是一个较大的数字,例如 α = 32 α=32 α=32。通过这种方式,注意力分数的最大(绝对值)被除以α来防止其溢出。关于 CogVie注意力的详细分析在附录C。
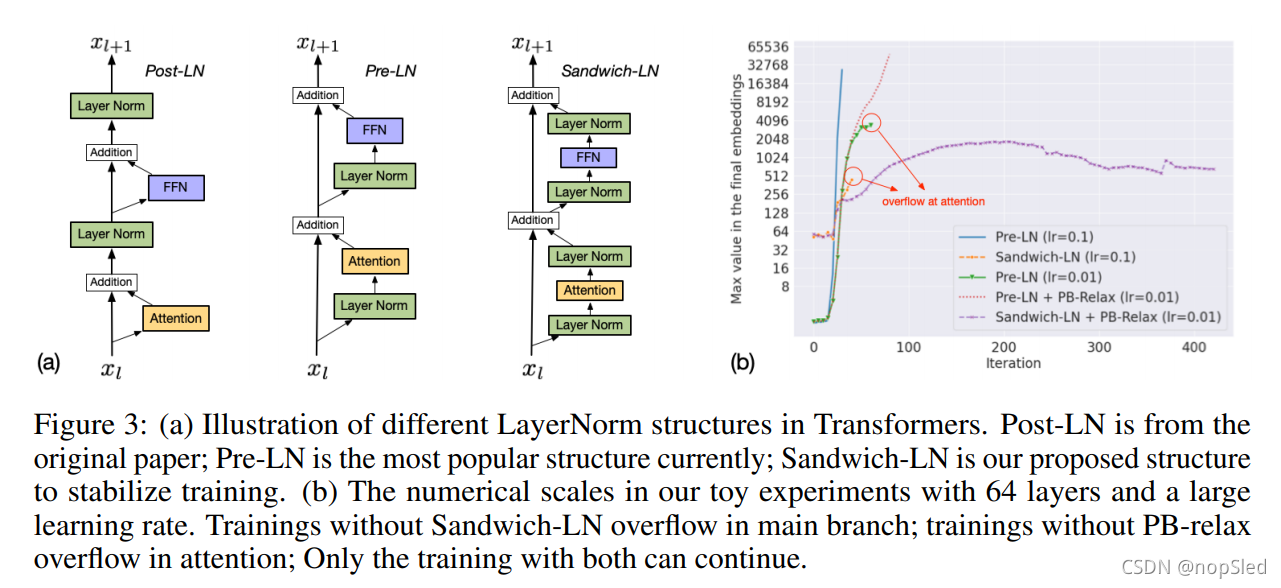
Sandwich LayerNorm (Sandwich-LN) 。 Transformer中的 LayerNorm对于稳定训练至关重要。Pre-LN被证明相比原始LN可以更快地收敛,也更稳定,并且成为最近工作中Transformer层的默认结构。但是,这对于text-to-image预训练是不够的。 LayerNorm的输出
(
x
−
x
~
)
d
∑
i
(
x
i
−
x
~
)
2
γ
+
β
\frac{(x-\tilde{x})\sqrt{d}}{\sqrt{\sum_i(x_i-\tilde x)^2}}\gamma+\beta
∑i(xi−x~)2(x−x~)dγ+β,基本上与
x
x
x的隐藏维度大小的平方根成比例,在Cogview中为
d
=
2560
≈
50
\sqrt d=\sqrt {2560}≈50
d=2560≈50。 如果某些维中的输入值明显大于其他维,这对于Transformer 中相应维的输出值也会大(
1
0
1
〜
1
0
2
10^1〜10^2
101〜102)。在残差分支中,这些较大的值被放大并加回到主分支,这会加剧下一Transformer层中的这种现象,从而最终导致深层的value explosion。
value explosion背后的原因激励我们限制逐层累加。我们提出了Sandwich LayerNorm,其在每个残差分支结束时添加一个新的LayerNorm。Sandwich LayerNorm确保了每层的输入值的比例在一个合理范围内,训练一个500M模型的实验表明,其对收敛的影响是可忽略不计的。图3(a)说明了Transformers中的不同LayerNorm结构。
Toy Experiments。图 3(b) 显示了 PB-relax 和 Sandwich-LN 在一个简易实验中的有效性,因为训练许多大型模型以进行验证是不现实的。我们发现深层transformers(64层,1024个隐藏维度),大学习率(0.1或0.01),小的btach size(4)可以模拟合理超参训练中的value explosion。PB-Relax + Sandwich-LN甚至可以稳定toy experiments。
Shrink embedding gradient。虽然我们没有观察到使用Sandwich-LN后溢出的任何迹象,但我们发现字符嵌入的梯度远大于其他参数的梯度,从而简单地通过令 α = 0.1 α= 0.1 α=0.1,以增加动态损耗比例来防止下溢,该方法可以通过Pytorch中的 e m b = e m b ∗ a l p h a + e m b . d e t a c h ( ) ∗ ( 1 − a l p h a ) emb = emb*alpha+emb.detach()*(1-alpha) emb=emb∗alpha+emb.detach()∗(1−alpha)实现。它似乎减缓了字符嵌入的更新,但实际上在我们的实验中没有损害性能,这也与最近的工作MoCo v3中的结果相符。
Discussion。 PB-relax 和 Sandwich-LN 成功地稳定了8.3B参数Cogview-large的训练。它们也适用于所有Transformer预训练,并能够训练非常深的Transformer。作为证据,我们使用PB-relax成功消除10B参数GLM训练中的溢出。然而,一般而言,语言模型预训练中的精确问题相比text-to-image预训练来说并不重要。我们假设其根本是数据的异构性,因为我们观察到文本和图像字符以某些隐藏状态的规模而区分。
3.Finetuning
Cogview比DALL-E更进一步进行了finetune。特别是,我们可以通过finetuning Cogview来改进text-to-image的生成,以获得超分辨率图像和self-reranking。我们的一个重要发现是,在微调大型GPT-like模型之前,我们必须从预训练中加载优化器状态,或者用一个大的步长热启动。由于预训练中的优化器状态通常不会向公众发布,因此它们的价值观在很大程度上低估了。所有FineTuning任务都可以在单个DGX-2上一天内完成。
3.1 Style Learning

虽然CogView是通过尽可能地覆盖各种图像来进行预训练,但扔无法满足生成特定风格或主题的图像这一需求。我们在四种风格上Finetune模型:中国画,油画,草图和动画。这些风格的图像是从包括Google,Baidu和Bing等的搜索引擎页面中自动提取,这些图像带有关键字“An image of {style} style”,其中{style}是风格的名称。我们分别为不同的风格finetune模型,每个风格包含1,000个图像。在finetuning期间,图像的相应文本是“An image of {style} style”。生成时,文本是“A {object} of {style} style”,其中{object}是要生成的对象。图4显示了样式的示例。
3.2 Super-resolution

我们首先将Cogview finetune为一个从16×16图像字符到32×32字符的超分辨率模型。该模型还可以通过图5中的中央连续滑动窗策略将32×32字符的图像放大64×64字符(512×512像素)的图像。
为了准备数据,我们将大约2百万图像裁剪到256×256个区域,并将其下采样到128×128。在tokenization之后,我们得到32×32和16×16序列对,用于不同的分辨率。FineTuning序列的模式是“
[
R
O
I
1
]
t
e
x
t
t
o
k
e
n
s
[
B
A
S
E
]
[
B
O
I
1
]
16
×
16
i
m
a
g
e
t
o
k
e
n
s
[
E
O
I
1
]
[
R
O
I
2
]
[
B
A
S
E
]
[
B
O
I
2
]
32
×
32
i
m
a
g
e
t
o
k
e
n
s
[
E
O
I
2
]
[ROI1]~text~tokens~[BASE]~[BOI1]~16×16~image~tokens~[EOI1]~[ROI2]~[BASE]~[BOI2]~32×32~image~tokens~[EOI2]
[ROI1] text tokens [BASE] [BOI1] 16×16 image tokens [EOI1] [ROI2] [BASE] [BOI2] 32×32 image tokens [EOI2]”,该序列要远大于最大嵌入长度1087。为了解决这个问题,我们将位置为
[
R
O
I
2
]
[ROI2]
[ROI2]处的索引重置为0。
3.3 Image Captioning and Self-reranking

对于finetune CogView以进行图像标题生成是很直接的:在输入序列中交换文本和图像字符的顺序。由于该模型已经学习了文本和图像之间的相应关系,因此反向生成并不难。我们没有评估其性能,主要是因为(1)没有权威的中文图像标题基准,(2)图像标题不是这项工作的重点。FineTuning这样的模型的主要目的是为了self-reranking。我们提出了标题评分(CAP)来评估图像和文本之间的对应关系。更具体地,
C
a
p
S
(
x
,
t
)
=
∏
i
=
0
∣
t
∣
p
(
t
i
∣
x
,
t
0
:
i
−
1
)
∣
t
∣
CapS(x,t)=\sqrt[|t|]{\prod^{|t|}_{i=0}p(t_i|x,t_{0:i-1})}
CapS(x,t)=∣t∣∏i=0∣t∣p(ti∣x,t0:i−1),其中
t
t
t是文本字符,
x
x
x是图像序列。
l
o
g
C
a
p
S
(
x
,
t
)
log CapS(x, t)
logCapS(x,t)是文本字符的交叉熵损失,并且该方法可以被视为对图像生成的反向提示的调整。 最后,选择具有最高
C
a
p
S
(
x
,
t
)
CapS(x, t)
CapS(x,t)的图像将被选择。
3.4 Industrial Fashion Design

当在单个领域内生成目标时,文本的复杂性大大降低。在这些方案中,我们可以(1)训练一个VQGAN来代替VQVAE,(2)降低参数的数量并增加序列的长度以获得更高分辨率。我们的三个区域稀疏关注(附录B)可以在这种情况下加速生成高分辨率图像。
我们使用50×50 VQGAN图像字符,在大约1000万时尚标题对数据上训练3B参数模型,并将它们解码成800×800像素。图7显示了时装设计的CogView样本,这已成功部署到Alibaba Rhino fashion production。

















 1182
1182

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









