






摘要
学习高质量句子表示有益于各种自然语言处理任务。虽然基于BERT的预训练语言模型在许多下游任务上实现了较高性能,但由于其所产生的句子表示被证明是崩塌的,因此在语义文本相似度(STS)任务上产生了较差的性能。在本文中,我们提出了ConSERT,a Contrastive Framework for Self-Supervised SEntence Representation Transfe,采用无监督和有效的方式来微调BERT以进行对比学习。通过利用未标注的文本,ConSERT解决了BERT计算句子表示的崩塌问题,并使它们更适用于下游任务。STS Datasets的实验表明,当前最先进的无监督方法甚至与有监督的SBERT-NLI相比,ConSERT达到了8%的相对改善。在进一步使用有监督NLI时,我们在STS任务上实现了新的最新性能。此外,ConSERT在只有1000个样本上获得了可比的结果,显示其在数据稀缺方案中的鲁棒性。
1.介绍
句子表示学习在自然语言处理任务中起着重要作用。好的句子表示有利于各种下游任务,特别是对于计算昂贵的任务,包括大型语义相似性比较和信息检索。
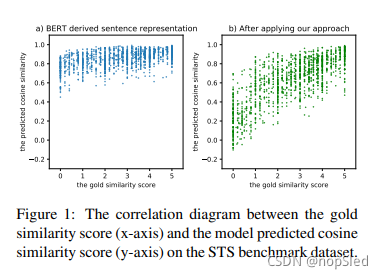
最近,基于BERT的预训练语言模型在许多下游任务中实现了高性能。然而,从BERT计算的句子表示被证明是低质量的。如图1a)所示,当直接采用基于BERT的句子表示来进行语义文本相似性(STS)任务时,即使某些被人类标注为完全无关的句子,也达到了0.6到1.0之间的相似度得分。换句话说,BERT计算的句子表示是崩塌的,这意味着几乎所有句子都映射到一个小面积,因此产生高相似性。
在几个以前的工作中也观察到这种现象。 它们发现BERT的字表示空间是各向异性的,高频词被聚集并靠近原点,而低频词稀疏地分散。当平均字符Embeddings时,那些高频词在句子表示中占主导,从而对他们的真实语义产生偏差。因此,直接人工标注是昂贵的并且通常在现实世界的情景中经常无法使用。
为了缓减BERT的崩溃问题,并减少有标注数据的需求,我们提出了一种基于对比学习的新型句子级训练目标。通过鼓励将相似句子靠得更近,不相似句子靠的更远,我们重塑BERT计算的句子表示空间并成功解决崩溃问题(如图1B所示)。此外,我们提出了多种数据增强策略,以实现对比学习,包括对抗攻击,字符打乱,cutoff和dropout,从而有效地将句子表示迁移到下游任务。我们将我们的方法命名为ConSERT,a Contrastive Framework for Self-Supervised SEntence Representation Transfe。
相比以前的方法ConSERT有几个优势。首先,它在推理期间没有额外的结构或特殊的实现。ConSERT的参数大小与BERT保持相同,使其易于使用。其次,与预训练方法相比,ConSERT更有效。只使用1,000个从目标分布中抽取的未标注文本(在现实世界应用易于收集),我们达到了35%的相对性能增益,并且只需要在单V100 gpu上训练几分钟(1-2K步)。最后,它包括几种有效和方便的数据增强方法,具有最小的语义影响。它们的效果在消融实验中验证并分析。
我们的贡献可以总结如下:
- 我们提出了一种基于对比学习的简单但有效的句子级训练目标。它减轻了BERT计算的句子表示的崩溃问题,并将它们迁移到下游任务。
- 我们探索各种有效的文本增强策略,并分析他们对无监督句子表示迁移的影响。
- 只在无监督的目标数据集上进行微调,我们的方法可以实现对STS任务的重大改进。在进一步纳入NLI监督数据时,我们的方法可以实现新的最先进的性能。我们还展示了我们在数据稀缺情景中的方法的鲁棒性。
2.相关工作
2.1 Sentence Representation Learning
Supervised Approaches。以及有几种工作使用有监督数据集进行句子表示学习。Conneau et al. (2017) 发现有监督的自然语言推理(NLI)任务可用于训练好的句子表示。他们使用基于BiLSTM的编码器并在两个NLI数据集(Stanford NLI,SNLI和多类型NLI,MNLI)上训练它。Universal Sentence Encoder采用基于Transformer的架构,并使用SNLI数据集来增加无监督的训练。SBERT提出了一个带有共享BERT编码器的双塔架构,也在SNLI和MNLI数据集上进行训练。
Self-supervised Objectives for Pre-training。BERT为语言模型的预训练提除了双向Transformer编码器。它包括一个句子级训练目标,即下一个句子预测(NSP),其预测了两个句子是否相邻。然而,NSP被证明是效果不明显的,其句子表示几乎没有贡献。之后,各种自监督的目标被提出,用于预训练BERT句子编码器。CrossThought和CMLM是两种类似的目标,基于上下文的句子表示,可在一个句子中恢复MASK字符。SLM提出了一个目标,该目标是将打乱的句子作为输入来重建正确句子顺序。但是,所有这些目标都需要文档级语料库,因此不适用于只有短文本的下游任务。
Unsupervised Approaches。BERT-flow提出了一种基于flow的方法,将BERT词嵌入映射到标准高斯潜在空间,该空间中的嵌入更适合于比较。然而,这种方法引入了额外的模型结构,需要专门的实现,这可能会限制其应用场景。
2.2 Contrastive Learning
Contrastive Learning for Visual Representation Learning。最近,对比学习已经成为了学习具有强大性能的无监督视觉表示的一种非常流行的技术。这些工作认为,良好的表示应该能够识别相同的目标,同时从其他目标中区别处自身。基于这种直觉,这些工作应用图像转换(例如裁剪,旋转,切片等),以随机生成每个图像的两个增强版本,并使它们在表示空间中彼此接近。这种方法可以被视为对输入样本的不变性建模。Chen et al. (2020a) 提出了一个简单的对比学习框架SimCLR。它们使用normalized temperature-scaled cross-entropy loss (NT-Xent)作为训练损失,这在以前的文献中也称为InfoNCE。
Contrastive Learning for Textual Representation Learning。最近,对比学习已广泛应用于NLP任务。许多工作使用对比学习来进行语言模型预训练。IS-BERT提出在BERT顶部添加1-D卷积神经网络层,并通过最大化全局句子嵌入与其对应的局部上下文嵌入之间的交互信息(MI)来训练CNN。CERT采用与MOCO类似的结构,并使用反向翻译进行数据增强。但是,momentum编码器需要额外的内存,并且反向翻译可能会生成假正例。BERT-CT使用两个单独的编码器进行对比学习,这也需要额外的记忆。此外,他们只采样7个负例,导致训练效率低。DeCLUTR采用SimCLR的架构,并使用对比目标和屏蔽语言模型目标来共同训练模型。然而,他们只使用span用于对比学习,这导致语义碎片。CLEAR使用与DeCLUTR相同的架构和目标。它们都用于预训练语言模型,者需要大语料库并需要大量资源。
3.方法
在本节中,我们提出了用于句子表示迁移的ConSERT。给定类似于BERT的预训练语言模型 M \textbf M M和无监督的数据集 D \mathcal D D,我们的目标是在 D \mathcal D D上进行微调 M \textbf M M,以使句子表示与任务相关,并适用于下游任务。我们首先展示了我们方法的一般框架,然后我们介绍了几种用于对比学习的数据增强策略。最后,我们讨论可以进一步纳入监督信号的三种方法。
3.1 General Framework
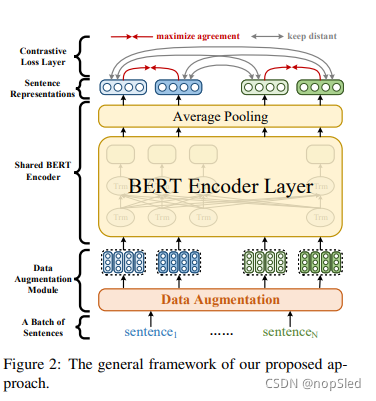
我们的方法主要受到SimCLR的启发。如图2所示,我们的框架中有三个主要组件:
- 数据增强模块,为嵌入层的输入生成不同的样本。
- 共享BERT编码器,可计算每个输入文本的句子表示。在训练期间,我们使用最后一层嵌入的平均池化来获取句子表示。
- BERT编码器顶部的对比损失层。它在最大化句子表示与其相应增强后句子之间的相似性的同时,最小化相同批次中的其他句子表示的相似性。
对于每个输入文本
x
x
x,我们首先将其传递给数据增强模块,其应用两个转换操作
T
1
T_1
T1和
T
2
T_2
T2来生成两种类型的字符嵌入:
e
i
=
T
1
(
x
)
,
e
j
=
T
2
(
x
)
e_i= T_1(x),e_j=T_2(x)
ei=T1(x),ej=T2(x),其中
e
i
,
e
j
∈
R
L
×
d
e_i,e_j∈\mathbb R^{L×d}
ei,ej∈RL×d,
L
L
L是序列长度,
d
d
d是隐藏的维度。之后,
e
i
e_i
ei和
e
j
e_j
ej都将由BERT中的多层transformer块编码,并通过平均池化来产生句子表示
r
i
r_i
ri和
r
j
r_j
rj。
与 Chen et al. (2020a) 相同,我们采用正则化的温度缩放的交叉熵损失((NT-Xent)作为对比目标。在每个训练步骤中,我们随机地从KaTeX parse error: Undefined control sequence: \mnathcal at position 1: \̲m̲n̲a̲t̲h̲c̲a̲l̲ ̲D中采样
N
N
N个文本以构建mini-batch,经增强模块后将会得到
2
N
2N
2N个表示。训练每个数据点,以在
2
(
N
−
1
)
2(N-1)
2(N−1)个样本中找到其对应的正例:
L
i
,
j
=
−
l
o
g
e
x
p
(
s
i
m
(
r
i
,
r
j
)
/
τ
)
∑
k
=
1
2
N
1
[
k
≠
i
]
e
x
p
(
s
i
m
(
r
i
,
r
k
)
/
τ
)
(1)
\mathcal L_{i,j}=-log\frac{exp(sim(r_i,r_j)/\tau)}{\sum^{2N}_{k=1}1_{[k\ne i]}exp(sim(r_i,r_k)/\tau)}\tag{1}
Li,j=−log∑k=12N1[k=i]exp(sim(ri,rk)/τ)exp(sim(ri,rj)/τ)(1)
其中
s
i
m
(
⋅
)
sim(·)
sim(⋅)表示余弦相似函数,
τ
τ
τ控制温度,
1
1
1是指示函数。最后,我们平均所有
2
N
2N
2N个样本的分类损失,以获得最终的对比损耗
L
c
o
n
\mathcal L_{con}
Lcon。
3.2 Data Augmentation Strategies
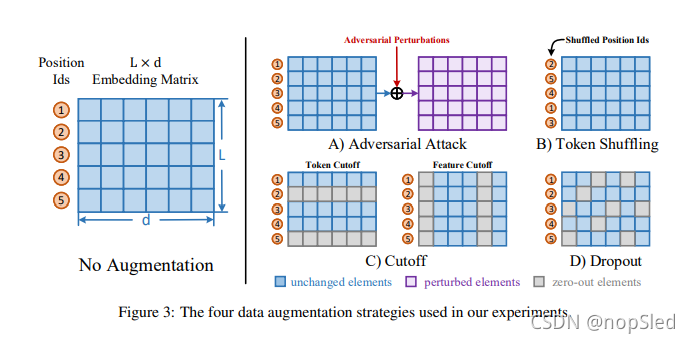
我们探索四种不同的数据增强策略,以产生对比学习的不同数据,包括 adversarial attack,token shuffling,cutoff和dropout,如图3所示。
Adversarial Attack。对抗训练通常用来改善模型训练的鲁棒性。它们通过向输入样本添加worst-case扰动来产生对抗性样本。我们通过快速梯度值(FGV)来实现此策略,该策略直接使用梯度来计算扰动,因此比两步替代方法更快。请注意,此策略仅适用于与有监督样本联合训练,因为它依赖于有监督损失来计算对抗扰动。
Token Shuffling。在此策略中,我们的目标是随机打乱输入序列中的字符顺序。由于transformer架构中的词袋性质,位置编码是关于顺序信息的唯一因素。因此,类似于Lee et al. (2020),我们通过将随机的位置ID传递给嵌入层来实现此策略,同时保持字符ID的顺序不变。
Cutoff。Shen et al. (2020) 提出了一种简单有效的数据增强策略,称为Cutoff。它们随机擦除
L
×
d
\mathcal L×d
L×d特征矩阵中的一些字符(token Cutoff),或特征维度(feature Cutoff),或字符跨度(span Cutoff)。在我们的实验中,我们只使用token Cutoff和feature Cutoff。
Dropout。Dropout是一种广泛使用的避免过拟合的正则化方法。然而,在我们的实验中,我们还将其作为增强战略的有效性,以实现对比学习。对于此设置,我们通过特定概率随机丢弃字符嵌入层中的元素,并将其值设置为零。请注意,此策略与Cutoff不同,因为每个元素被单独考虑。
3.3 Incorporating Supervision Signals
除了无监督的迁移外,我们的方法也可以与有监督学习合并。我们以NLI有监督数据为例。它是一个句子对分类任务,其中模型被训练以区分两个句子之间的关系,即contradiction,entailment和neutral。分类目标可以表达如下:
f
=
C
o
n
c
a
t
(
r
1
,
r
2
,
∣
r
1
−
r
2
∣
)
L
c
e
=
C
r
o
s
s
E
n
t
r
o
p
y
(
W
f
+
b
,
y
)
(2)
\begin{array}{ll} f=Concat(r_1,r_2,|r_1-r_2|) \\ \mathcal L_{ce}=CrossEntropy(Wf+b,y) \end{array}\tag{2}
f=Concat(r1,r2,∣r1−r2∣)Lce=CrossEntropy(Wf+b,y)(2)
其中
r
1
r_1
r1和
r
2
r_2
r2是两个句子的表示。
我们提出了三种方法来纳入额外的监督信号:
- Joint training (joint)。我们在NLI数据集上使用有监督和无监督目标来联合训练模型,即 L j o i n t = L c e + α L c o n \mathcal L_{joint}=\mathcal L_{ce} +α\mathcal L_{con} Ljoint=Lce+αLcon。其中 α α α是平衡两个目标的超参数。
- Supervised training then unsupervised transfer (sup-unsup)。我们首先在NLI数据集上使用 L c e \mathcal L_{ce} Lce训练模型,然后在目标数据集中使用 L c o n \mathcal L_{con} Lcon将其Finetune。
- Joint training then unsupervised transfer (joint-unsup)。我们首先将模型在NLI数据上训练 L j o i n t \mathcal L_{joint} Ljoint,然后在目标数据集上使用 L c o n \mathcal L_{con} Lcon进行微调。

















 2432
2432

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









