






摘要
在多轮对话中,每一个语句并不总是使用完整上下文的句子,其自然地使理解对话上下文变得更加困难。但是,完全掌握对话上下文并生成合理的响应是必不可少的。因此,在本文中,我们提出通过检测模型回答阅读理解问题的能力来提高响应生成的性能,其中问题只要专注于对话中被省略的信息。受多任务学习方法的启法,我们提出了一个联合框架来统一这两个任务,通过使用相同的编码器来提取公共且任务无关的特征,然后使用不同的解码器来学习特定任务的特征。在编码部分,为了更好的融合问题和对话历史的信息,我们提出通过使用一个memory updater来增强Transformer架构,memory updater旨在选择性地存储和更新历史对话信息,以便支持下游任务。在实验中,我们采用人工标注员来编写和检查大型对话阅读理解数据集,然后在该数据集上进行了广泛的实验。结果表明,该模型在两个任务中的多个强基线上带来了大幅改进。通过这种方式,我们证明推理确实可以有助于更好的响应生成,反之亦然。另外,我们开源了我们的大型数据集以提供研究员进一步的研究。
1.介绍

近年来,文本生成取得了令人印象深刻的进步,开放领域的对话生成已成为自然语言处理的研究热点,这是因为其具有广泛的应用前景(例如聊天机器人,虚拟个人助理等)。但研究显示,使用对话系统的用户倾向于使用简洁的语言,这些语言通常省略了先前使用过的语句中所表述的实体或概念。为了做出合适的响应,对话系统必须具备能够理解这些不完整语句的能力。这自然导致需要依赖阅读理解任务,即正确回答需要理解的对话上下文中的问题。
例如,参考表1中的示例2,括号中的内容是语句中省略的信息。人类能够根据先前的语句和常识来理解这缺失的信息。例如,
A
3
A_3
A3表示需要将MV而不是礼物发送给
B
B
B。然而,虽然这很重要,模型难以在没有特定设计的情况下捕获语句之间的隐式依赖性,这就是提出阅读理解任务的原因。在这种情况下,通过使用具有关键字
M
V
MV
MV的推理和正确回答问题,模型学习到对话的重点放在MV上,这导致在音乐相关对话中也能做出正确响应。根据Pan et al. (2019) 的调查,为了完全理解当前语句,需要依赖大约60%的历史上下信息。 这启发我们提出了一个多任务框架,该框架能同时生成响应和回答阅读理解问题,这可以同时提高这两个任务的性能。
我们的多任务响应生成器(MRG)增强了之前提出的Transformer架构,其能够以基于问题方式编码多个语句。所提出的模型首先使用问题和对话单词之间的cross-attention机制来识别对话中的代表性单词。具体地,我们提出了一个memory updater,它使用当前输入和先前的存储器状态更新存储器。存储器状态可以被解释为能够高度总结对话历史信息的容器。在cross-attention过程中,使用来自前一步骤的存储器状态来增强当前对话表示。然后MRG使用分层内部注意力,首先对每个语句中的不同单词计算注意力,然后在对话历史的所有话语中计算注意力,从而连续学习句子级特征。最后,MRG利用句子级和问题特征来选择问题的答案,同时生成响应单词。
由于缺少大规模对话阅读理解数据集,因此我们聘请了一个标注团队来构建对话阅读理解数据集(DRCD)。 具体地,基于 Pan
et al. (2019) 提出的Restoration-200K数据集,其中被省略的单词跨度由人工标注,我们要求标注者在答案是缺失短语的地方写下问题。我们手动构建了10K条数据,然后训练了一个问题生成器并利用模型来构建数据集其余部分的问题。 我们在DRCD上基准测试几种经典对话生成和阅读理解基线。我们还开展了实验,表明所提出的模型在两个任务上对这些基线都带来了大幅的改进。通过这种方式,我们证明推理可以确实有助于更好的响应生成,反之亦然。
我们的贡献可以总结如下:
- 我们提出了多任务学习框架,能够回答阅读取理解问题,并在多轮对话场景中生成合适的响应。
- 我们使用memory updater来增强Transformer架构,这有助于选择性地存储和更新历史对话信息。
- 我们开源了一个大规模对话阅读理解数据集。在此数据集上的实验结果展示了我们提出的框架的有效性。
2.相关工作
Multi-turn Dialog。近年来,文本生成取得了令人印象深刻的进步,而多轮对话模型旨在基于历史的信息和语句作为输入来生成响应。通过简单地将多个句子拼接成一个句子,先前的一些工作将多转对话问题简化为单轮问题,并利用基于RNN或Transformer的基本Seq2seq来建模长序列。为了更好地利用多轮中的各语句,Xing et al. (2017) 对单词级和句子级信息应用分层注意力。同时先前工作还提出各种对话数据集。但是,这些数据集都不包含阅读理解任务的问题答案对。
Machine Reading Comprehension。机器阅读理解(MRC)重点关注问题和参考文档之间的语义匹配,通过读取完整的文本以选择相关文本跨度,然后推断出答案。Choi et al. (2017) 提出分层由粗到的方法,以模仿人类的阅读模式。Huang et al. (2017) 提出fully-aware fusion的注意力机制,并将其应用于MRC任务。同时,MRC的大型数据集也相应被提出。CommonsenseQA是从ConceptNet中提取的常识问题回答数据集。DROP和COSMOS分别专注于事实理解和常识理解。在本文中,我们提出了另一个MRC数据集,专注于对话语料库的机器理解。
Multi-task Learning。多任务学习(MTL)是机器学习中的学习框架,其目标是利用多个相关任务中包含的互补信息来帮助提高这些任务的泛化性能。存在大量的基于多任务学习的自然语言处理任务,例如单词分段,POS,依存解析和文本分类。Collobert
and Weston (2008) 描述了一个单一的卷积网络,该网络联合训练了几个NLP任务,例如词性标注,分块,命名实体识别,语义角色标注。Liu et al. (2015)开发了一个多任务深度神经网络来组合多个领域的分类任务和信息检索任务,以学习多个任务的表示。在这项工作中,我们对对话的响应生成和阅读理解应用多任务学习。
3.问题定义
在提出我们基于对话阅读理解的多任务学习方法之前,我们首先介绍我们的符号和关键概念。
我们假设一段对话在两个用户之间进行,而且对话中已经进行了
N
u
N^u
Nu轮,所以我们将历史语句表示为
X
=
(
X
1
,
X
2
,
.
.
.
,
X
N
u
)
X=(X_1,X_2,...,X_{N^u})
X=(X1,X2,...,XNu),其中每个语句
X
j
X_j
Xj可以被被分解为
X
j
=
(
x
1
j
,
x
2
j
,
.
.
.
,
x
N
j
j
)
X_j=(x^j_1,x^j_2,...,x^j_{N_j})
Xj=(x1j,x2j,...,xNjj),其中
x
i
j
x^j_i
xij表示一个单词。因此,MRG旨在预测第
(
N
u
+
1
)
(N^{u+1})
(Nu+1)个语句,基于历史表达
X
X
X的响应
Y
=
(
y
1
,
y
2
,
.
.
.
,
y
N
y
)
Y=(y_1,y_2,...,y_{N^y})
Y=(y1,y2,...,yNy)的预测概率为:
p
(
Y
∣
X
)
=
∏
i
=
1
N
y
p
(
y
i
∣
X
,
y
1
,
.
.
.
,
y
i
−
1
)
(1)
p(Y|X)=\prod^{N^y}_{i=1}p(y_i|X,y_1,...,y_{i-1})\tag{1}
p(Y∣X)=i=1∏Nyp(yi∣X,y1,...,yi−1)(1)
除了响应生成,我们还为模型设计了一个问题回答任务。即,在缺少一些关键字的第
N
u
N^u
Nu个语句上,有一个问题
Q
=
(
q
1
,
q
2
,
.
.
.
,
q
N
q
)
Q=(q_1,q_2,...,q_{N^q})
Q=(q1,q2,...,qNq),用以询问这些缺失的信息,而答案是一个从先前的话语中提取的缺失关键字的分数矢量
A
=
(
a
1
,
a
2
,
.
.
.
,
a
N
a
)
A=(a_1,a_2,...,a_{N^a})
A=(a1,a2,...,aNa),
N
a
=
∑
i
=
1
N
u
N
i
N^a=\sum^{N^u}_{i=1}N_i
Na=∑i=1NuNi。每个分数
a
i
∈
0
,
1
a_i∈{0,1}
ai∈0,1表示是(1)或不是(0)选择第
i
i
i个字。目标是在给定输入
X
X
X的情况下,最大化所有单词标签
A
A
A的概率:
p
(
A
∣
X
)
=
∏
i
=
1
N
a
p
(
a
i
∣
X
)
(2)
p(A|X)=\prod^{N^a}_{i=1}p(a_i|X)\tag{2}
p(A∣X)=i=1∏Nap(ai∣X)(2)
4. MRG模型
4.1 Overview
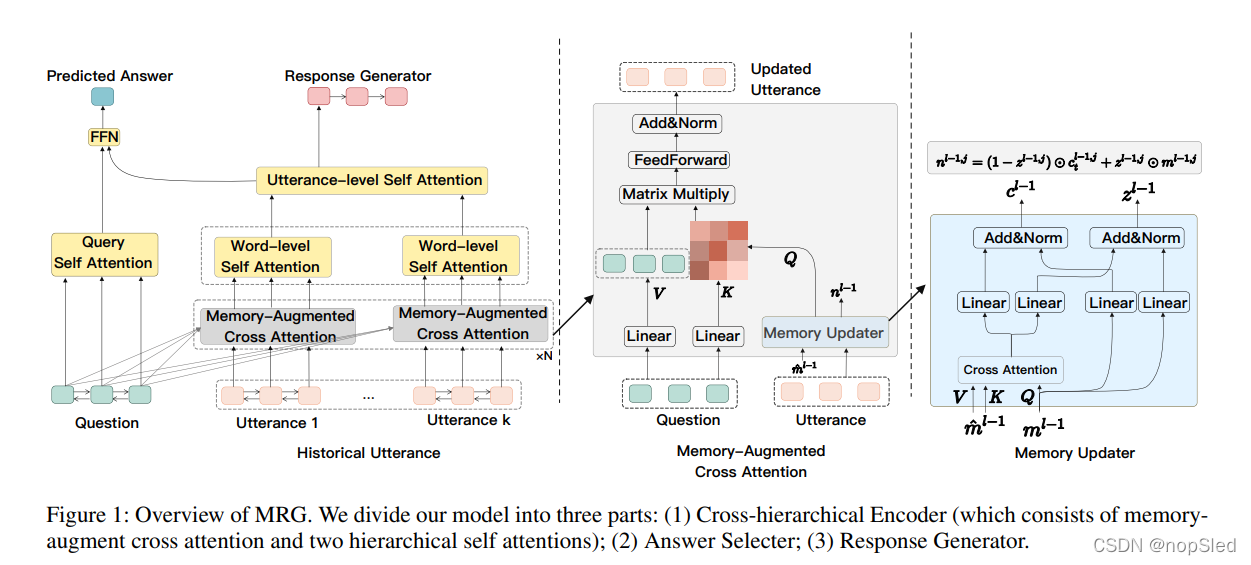
在本节中,我们提出了多任务响应生成器,缩写为MRG。MRG的概述如图1所示,可以分为三个主要部分:
- Cross-hierarchical encoder。编码器首先在问题和对话单词之间使用memory-augmented cross-attention机制,以在问题的帮助下识别对话中的代表性单词。然后,它使用分层内部注意力,首先在每个语句中覆盖不同的单词,然后在对话历史中所有语句中,连续学习句子级特征。
- Answer selecter。选择器将问题表示和句子级特征作为输入来预测答案。
- Response generator。生成器通过引入句子级特征来生成响应。
4.2 Cross-hierarchical Encoder
首先,我们使用嵌入矩阵
e
e
e将
X
,
Q
X,Q
X,Q中的每个单词的one-hot表示映射到高维向量空间。然后,我们使用双向循环神经网络(Bi-RNN)来建模单词之间的序列交互:
h
i
x
,
j
=
B
i
−
R
N
N
x
(
e
(
x
i
j
)
,
h
i
−
1
x
,
j
)
,
h
i
q
=
B
i
−
R
N
N
y
(
e
(
q
i
)
,
h
i
−
1
q
)
(3)
\begin{array}{cc} h^{x,j}_i=Bi-RNN_x(e(x^j_i),h^{x,j}_{i-1}),\\ h^q_i=Bi-RNN_y(e(q_i),h^q_{i-1}) \end{array}\tag{3}
hix,j=Bi−RNNx(e(xij),hi−1x,j),hiq=Bi−RNNy(e(qi),hi−1q)(3)
其中
h
i
x
,
j
h^{x,j}_i
hix,j和
h
i
q
h^q_i
hiq分别表示
X
j
X_j
Xj和
Q
Q
Q在Bi-RNN中的第
i
i
i步的隐藏状态。与 (Zhao, Zhao, and Eskenazi 2017; Chen et al. 2018) 相同,我们选择长短期记忆网络(LSTM)作为Bi-RNN的单元。
Memory-augmented Cross Attention。该模块通过将问题引入对话上下文中,从而使问题信息融合到对话表示中。具体来说,该模块具有由
L
L
L个相同层组成的栈结构。在每层中,我们通过 Memory-augmented Cross Attention Module (MCAM) 迭代地将来自问题单词的信息融合到对话单词中。为了方便起见,我们第
l
l
l个编码器层的输出作为
m
i
l
,
j
m^{l,j}_i
mil,j,第一层的输入
m
i
0
,
j
m^{0,j}_i
mi0,j被初始化为
h
i
x
,
j
h^{x,j}_i
hix,j。具体地说,MCAM基于传统的横向注意力模块(CAM) Transforme架构。我们首先介绍原始 CA,然后再介绍我们的修改。
CAM的第一个输入用于作为query
Q
Q
Q,第二个输入用于key
K
K
K和value
V
V
V,我们分别将其表示为
x
i
x_i
xi和
h
∗
q
h^q_*
h∗q:
m
i
l
,
j
=
C
A
M
(
m
i
l
−
1
,
j
,
h
∗
q
)
.
(4)
m^{l,j}_i=CAM(m^{l-1,j}_i,h^q_*).\tag{4}
mil,j=CAM(mil−1,j,h∗q).(4)
每个输出元素
m
i
l
,
j
m^{l,j}_i
mil,j被计算为输入值线性变换的的加权和:
m
i
l
,
j
=
∑
k
=
1
N
j
α
i
,
k
l
,
j
(
h
k
q
W
V
)
.
(5)
m^{l,j}_i=\sum^{N_j}_{k=1}\alpha^{l,j}_{i,k}(h^q_kW^V).\tag{5}
mil,j=k=1∑Njαi,kl,j(hkqWV).(5)
每个权重系数
α
i
,
k
l
,
j
\alpha^{l,j}_{i,k}
αi,kl,j使用softmax函数计算:
α
i
,
k
l
,
j
=
exp
(
β
i
,
k
l
,
j
)
∑
k
=
1
N
j
e
x
p
(
β
i
,
k
l
,
j
)
.
(6)
\alpha^{l,j}_{i,k}=\frac{\exp(\beta^{l,j}_{i,k})}{\sum^{N_j}_{k=1}exp(\beta^{l,j}_{i,k})}.\tag{6}
αi,kl,j=∑k=1Njexp(βi,kl,j)exp(βi,kl,j).(6)
β
i
,
k
l
,
j
\beta^{l,j}_{i,k}
βi,kl,j是使用两个元素作为输入的兼容函数来计算得到:
β
i
,
k
l
,
j
=
(
m
i
l
−
1
,
j
W
Q
)
(
h
k
q
W
K
)
T
d
,
(7)
\beta^{l,j}_{i,k}=\frac{(m^{l-1,j}_iW^Q)(h^q_kW^K)^T}{\sqrt{d}},\tag{7}
βi,kl,j=d(mil−1,jWQ)(hkqWK)T,(7)
其中
d
d
d代表隐藏维度。
W
Q
,
W
K
,
W
V
∈
R
d
×
d
W^Q,W^K,W^V\in \mathbb R^{d×d}
WQ,WK,WV∈Rd×d是参数矩阵。
虽然上述vanilla CAM是一种强大的方法,但由于无法充分利用历史对话信息,因而不太适合多轮对话。因此,我们使用一个外部存储器模块增强它,该模块有助于以多槽方式记住和更新历史对话信息,如图1所示。通过memory updator,query的输入,即
m
i
l
−
1
,
j
m^{l-1,j}_i
mil−1,j被更新为
n
i
l
−
1
,
j
n^{l-1,j}_i
nil−1,j,然后将其送入等式4中的CAM。具体地,使用多头注意力,memory updator 从其中间隐藏状态
m
^
i
l
−
1
(
m
^
l
−
1
∈
R
N
j
×
d
)
\hat m^{l-1}_i(\hat m^{l-1}\in \mathbb R^{N_j×d})
m^il−1(m^l−1∈RNj×d)和来自上一层的语句(memory)状态
m
i
l
−
1
,
j
m^{l-1,j}_i
mil−1,j进行信息聚合。具体地,query Q的输入是
m
i
l
−
1
,
j
m^{l-1,j}_i
mil−1,j,并且key
K
K
K和value
V
V
V的输入是
[
m
^
I
l
−
1
;
m
i
l
−
1
,
j
]
[\hat m^{l-1}_I;m^{l-1,j}_i]
[m^Il−1;mil−1,j]。使用前馈层进一步编码memory增强的隐藏状态,然后使用残差连接和层归一化与中间隐藏状态
m
^
l
−
1
\hat m^{l-1}
m^l−1合并。我们将处理过程总结如下:
s
i
l
−
1
,
j
=
C
A
M
(
m
i
l
−
1
,
j
,
m
^
i
l
−
1
)
,
c
i
l
−
1
,
j
=
t
a
n
h
(
W
a
l
−
1
m
i
l
−
1
,
j
+
W
b
l
−
1
s
i
l
−
1
,
j
)
,
z
i
l
−
1
=
s
i
g
m
o
i
d
(
W
c
l
−
1
m
i
l
−
1
,
j
+
W
d
l
−
1
s
i
l
−
1
,
j
)
,
n
i
l
−
1
,
j
=
(
1
−
z
i
l
−
1
,
j
)
⊙
c
t
l
−
1
,
j
+
z
i
l
−
1
,
j
⊙
m
i
l
−
1
,
j
,
\begin{array}{cc} s^{l-1,j}_i=CAM(m^{l-1,j}_i,\hat m^{l-1}_i),\\ c^{l-1,j}_i=tanh(W^{l-1}_am^{l-1,j}_i+W^{l-1}_bs^{l-1,j}_i),\\ z^{l-1}_i=sigmoid(W^{l-1}_cm^{l-1,j}_i+W^{l-1}_ds^{l-1,j}_i),\\ n^{l-1,j}_i=(1-z^{l-1,j}_i)\odot c^{l-1,j}_t+z^{l-1,j}_i\odot m^{l-1,j}_i, \end{array}
sil−1,j=CAM(mil−1,j,m^il−1),cil−1,j=tanh(Wal−1mil−1,j+Wbl−1sil−1,j),zil−1=sigmoid(Wcl−1mil−1,j+Wdl−1sil−1,j),nil−1,j=(1−zil−1,j)⊙ctl−1,j+zil−1,j⊙mil−1,j,
其中
⊙
\odot
⊙表示哈达玛积,
W
a
l
−
1
W^{l-1}_a
Wal−1,
W
b
l
−
1
W^{l-1}_b
Wbl−1,
W
c
l
−
1
W^{l-1}_c
Wcl−1和
W
d
l
−
1
W^{l-1}_d
Wdl−1是可训练的权重,
c
i
l
−
1
c^{l-1}_i
cil−1是内部单元状态。
z
i
l
−
1
z^{l-1}_i
zil−1是控制从先前存储器状态保留信息的更新门。
Hierarchical Self Attention。在利用问题信息以强调重要的关键字之后,再通过一个分层注意力模块处理
m
i
L
,
j
m^{L,j}_i
miL,j(上一个MCAM层的输出),以将单词之间的长期依赖编码到隐藏表示。我们分层注意力中的第一级为单独地对每个语句内的单词编码,得到每个语句的固定维度的表示。具体地,单词级注意力模块简化了Transformer中的多头注意力模块(MAM),不过query,key和value采用了相同的输入:
h
i
w
,
j
=
M
A
M
(
m
i
L
,
j
,
m
∗
L
,
j
)
.
(8)
h^{w,j}_i=MAM(m^{L,j}_i,m^{L,j}_*).\tag{8}
hiw,j=MAM(miL,j,m∗L,j).(8)
然后在每个语句中使用平均池化操作以获得固定长度的语句级表示:
h
u
′
,
j
=
m
e
a
n
p
o
o
l
(
{
h
1
w
,
j
,
.
.
.
,
h
N
j
w
,
j
}
)
.
(9)
h^{u',j}=meanpool\bigg (\{h^{w,j}_1,...,h^{w,j}_{N_j}\}\bigg ).\tag{9}
hu′,j=meanpool({h1w,j,...,hNjw,j}).(9)
类似于单词级的注意力,我们将语句级MAM应用于平均池化后表示,以融合不同语句之间的信息:
h
u
,
j
=
M
A
M
(
h
u
′
,
j
,
h
u
′
,
∗
)
.
(10)
h^{u,j}=MAM(h^{u',j},h^{u',*}).\tag{10}
hu,j=MAM(hu′,j,hu′,∗).(10)
从语句表示中,我们还可以获取整个对话历史的表示,这些历史表示将在响应解码器部分中使用:
h
d
=
m
e
a
n
p
o
o
l
(
{
h
u
,
1
,
.
.
.
,
h
u
,
N
u
}
)
.
(11)
h^d=meanpool\bigg (\{h^{u,1},...,h^{u,N^u}\}\bigg ).\tag{11}
hd=meanpool({hu,1,...,hu,Nu}).(11)
4.3 Answer Selector
从问题和对话上下文中融合信息后,我们需要从上下文中选择单词作为问题的答案。由于我们有若干语句表示,并且通过特定权重加权或平均它们是不合适的。因此,我们将所有语句和问题表示拼接一起,并将多层perceptron应用于它们以生成单词提取概率:
h
q
=
m
e
a
n
p
o
o
l
(
{
h
1
q
,
.
.
.
,
h
N
q
q
}
)
,
A
^
=
W
f
t
a
n
h
(
W
e
[
h
u
,
1
;
.
.
.
;
h
u
,
N
u
;
h
q
]
+
b
e
)
+
b
f
,
\begin{array}{cc} h^q=meanpool\bigg (\{h^q_1,...,h^q_{N^q}\}\bigg ),\\ \hat A=W_ftanh\bigg (W_e[h^{u,1};...;h^{u,N^u};h^q]+b^e\bigg )+b^f, \end{array}
hq=meanpool({h1q,...,hNqq}),A^=Wftanh(We[hu,1;...;hu,Nu;hq]+be)+bf,
其中
[
;
]
[;]
[;]表示拼接操作。
4.4 Response Generator
为了生成连贯的且包含信息的响应,我们提出了一种基于RNN的解码器,该解码器包含了语句表示的输出,如图1所示。
我们首先在输入文档向量表示
h
d
h^d
hd上应用线性变换,并使用该层的输出作为解码器LSTM的初始状态,如公式12所示。为了不增加初始状态
s
0
s_0
s0中压缩文档信息的负担, 我们使用注意力机制动态地将语句表示总结到上下文向量
f
t
−
1
f_{t-1}
ft−1中,我们将在本节稍后描述这些细节。然后,我们将上下文向量
f
t
−
1
f_{t-1}
ft−1拼接到上一步输出的嵌入
e
(
y
t
−
1
)
e(y_{t-1})
e(yt−1)上,并将其送入解码器LSTM中,如公式13所示:
s
0
=
W
g
h
d
+
b
g
,
(12)
s_0=W_gh^d+b_g,\tag{12}
s0=Wghd+bg,(12)
s
t
=
L
S
T
M
(
s
t
−
1
,
[
f
t
−
1
;
e
(
y
t
−
1
)
]
)
.
(13)
s_t=LSTM(s_{t-1},[f_{t-1};e(y_{t-1})]).\tag{13}
st=LSTM(st−1,[ft−1;e(yt−1)]).(13)
上下文向量
f
t
−
1
f_{t-1}
ft−1是将对话上下文信息存储在第
t
t
t步中的矢量。具体地说,我们使用解码器状态
s
t
−
1
s_{t-1}
st−1和每个语句状态
h
u
,
i
h^{u,i}
hu,i计算注意力分布
γ
t
γ_t
γt,如公式15所示。然后我们使用注意力分布
γ
t
γ_t
γt加权文档状态作为上下文向量
f
t
−
1
f_{t-1}
ft−1。
γ
t
−
1
,
i
′
=
W
n
T
t
a
n
h
(
W
s
s
t
−
1
+
W
h
h
u
,
i
)
,
(14)
\gamma'_{t-1,i}=W^T_ntanh(W_ss_{t-1}+W_hh^{u,i}),\tag{14}
γt−1,i′=WnTtanh(Wsst−1+Whhu,i),(14)
γ
t
−
1
,
i
=
e
x
p
(
γ
t
−
1
,
i
′
)
/
∑
j
=
1
N
u
e
x
p
(
γ
t
−
1
,
j
′
)
,
(15)
\gamma_{t-1,i}=exp\bigg (\gamma'_{t-1,i}\bigg )/\sum^{N_u}_{j=1}exp\bigg (\gamma'_{t-1,j}\bigg ),\tag{15}
γt−1,i=exp(γt−1,i′)/j=1∑Nuexp(γt−1,j′),(15)
f
t
−
1
=
∑
i
=
1
N
u
γ
t
−
1
,
i
h
u
,
i
.
(16)
f_{t-1}=\sum^{N_u}_{i=1}\gamma_{t-1,i}h^{u,i}.\tag{16}
ft−1=i=1∑Nuγt−1,ihu,i.(16)
最后,应用输出投影层以获取词表中最终的生成分布
P
t
v
P^v_t
Ptv,如等式17所示。我们拼接了语句上下文向量
f
t
f_t
ft和解码器LSTM的输出
s
t
s_t
st作为输出投影层的输入:
P
t
v
=
s
o
f
t
m
a
x
(
W
v
[
s
t
;
f
t
]
+
b
v
)
,
(17)
P^v_t=softmax(W_v[s_t;f_t]+b_v),\tag{17}
Ptv=softmax(Wv[st;ft]+bv),(17)
我们使用负对数似然作为损失函数:
L
g
=
−
s
u
m
t
=
1
N
y
l
o
g
P
t
v
(
y
t
)
.
(18)
\mathcal L_g=-sum^{N^y}_{t=1}log~P^v_t(y_t).\tag{18}
Lg=−sumt=1Nylog Ptv(yt).(18)

















 5033
5033

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









