





摘要
我们提出了Algorithm Distillation (AD),这是一种通过因果序列模型对其训练历史进行建模,从而将强化学习(RL)算法蒸馏到神经网络中。Algorithm Distillation将强化学习作为跨episode的序列预测问题进行学习。学习历史的数据集由一个源RL算法生成,然后通过给定先前学习历史作为上下文,一个因果transformer通过自回归预测动作来进行训练。与post-learning或expert sequences的序列决策预测架构不同,AD能够在不更新其网络参数的情况下完全在上下文中改进其策略。我们证明,AD可以在各种具有稀疏奖赏,组合任务结构和基于像素观测的环境中进行强化学习,并发现AD能比生成源数据的方法学习到具有更高数据效率的RL算法。
1.介绍
Transformers已成为用于序列建模的强大神经网络结构。预训练的transformers的一个令人惊讶的属性是它们通过提示或上下文学习来适应下游任务的能力。在大型离线数据集上进行预训练之后,已证明大型transformers可以推广到文本补全,语言理解和图像生成等下游任务中。
最近的工作表明,transformers还可以通过将离线强化学习(RL)作为序列预测问题从离线数据中学习策略。而Chen et al. (2021) 表明,transformers可以通过模仿学习从离线RL数据学习单任务策略,随后的工作表明,transformers还可以在同领域和跨领域中提取多任务策略。这些工作提出了一种有希望的范式来提取通用的多任务策略,即首先收集大规模且多样化的环境交互数据集,然后通过序列建模从数据中提取策略。我们将通过模仿学习从离线RL数据中学习策略的这类方法称为Offline Policy Distillation, 或者simply Policy Distillation (PD)。
尽管上述方法简单且可扩展,但PD的主要缺点是,所学习到的策略并不能继续从与环境的交互中逐步改善。例如,Multi-Game Decision Transformer学习到了返回条件的策略,该策略能玩许多Atari游戏,而Gato通过上下文来推断任务,从而解决跨不同环境的任务,但两种方法都无法通过试错来改善其策略。MGDT通过对模型的权重进行微调,将transformer适应到新的任务,而Gato则需要具有专家提供的提示以适应新任务。简而言之,策略蒸馏方法学习到的政策没有使用到强化学习算法。
我们认为Policy Distillation没有通过试错得到改善的原因是,它是在没有显示学习过程的数据上训练的。当前的方法要么是从包含非学习的数据学习策略(例如,通过蒸馏固定的专家策略),要么通过包含学习但上下文太短导致无法显式策略提升的数据上学习策略(例如,RL ganet的经验回放集合)。
我们的主要观察结果是,在RL算法训练中学习序列性质在原则上可以将强化学习过程作为因果序列预测问题进行建模。具体而言,如果transformers的上下文足够长且能够包含学习更新过程中产生的策略提升(状态,动作,奖赏),那么它不仅能够表示一个固定的策略,还能表示一个策略提示运算操作。通过将该方式作为in-context RL算法,就可以通过模仿学习将任何RL算法蒸馏到足够强大的序列模型。
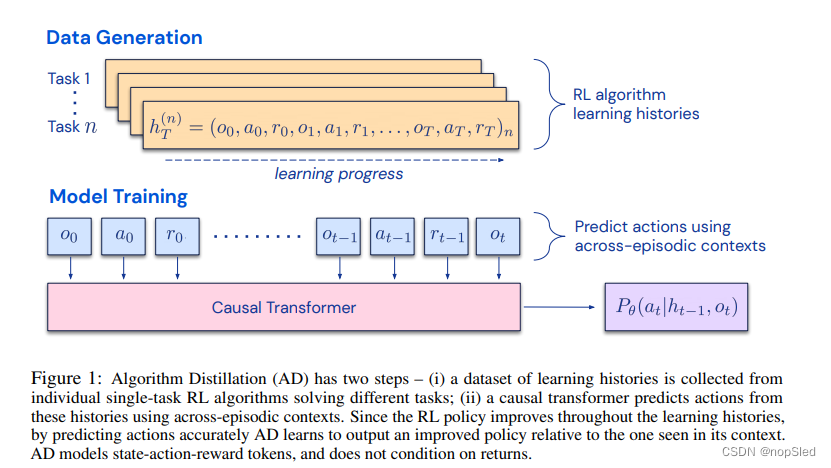
我们提出了Algorithm Distillation (AD),该方法通过在RL算法的学习历史上优化一个因果序列预测损失来学习上下文策略提升运算符。AD有两个组件。首先,通过保存在多个单任务上学习RL算法的训练历史来生成一个大型的多任务数据集。接下来,transformers以先前的学习历史作为上下文对预测的动作进行建模。 由于该策略是在整个源RL算法的训练改善过程,因此AD被迫学习改进操作,以便准确地对训练历史上任何给定点的动作进行建模。更重要的是,transformers上下文的大小必须足够大(即across-episodic)才能捕获训练数据的改进过程。完整方法如图1所示。
我们表明,通过使用具有足够长上下文的因果transformer来模仿基于梯度的RL算法,AD可以完全基于上下文来强化学习新的任务。我们在许多部分可观测的要求进行探索的环境中评估AD,包括来自DMLab的基于像素的Watermaze。我们表明,AD能够进行上下文探索,时间信用分配和泛化。我们还表明,与生成用于transformer训练的源数据的算法相比,AD学习了一种更高数据效率的算法。据我们所知,AD是第一个通过使用具有模仿损失的离线数据的序列建模来证明上下文强化学习的方法。
2.背景
Partially Observable Markov Decision Processes。一个马尔可夫决策过程(MDP)由状态
s
∈
S
s∈\mathcal S
s∈S,动作
a
∈
A
a∈\mathcal A
a∈A,奖赏
r
∈
R
r∈\mathcal R
r∈R,衰减因子
γ
γ
γ和一个状态转移概率函数
p
(
s
t
+
1
∣
s
t
,
a
t
)
p(s_{t+1}|s_t,a_t)
p(st+1∣st,at),其中
t
t
t是一个表示时间步长的整数,且
(
S
,
A
)
(\mathcal S,\mathcal A)
(S,A)是状态和动作空间。在由MDP描述的环境中,对于每个时间步长
t
t
t,agent观察到状态
s
t
s_t
st,并从策略中选择一个动作
a
t
〜
π
(
⋅
∣
s
t
)
a_t〜π(·|s_t)
at〜π(⋅∣st),然后观察到从环境中动态采样的下一个状态
s
t
+
1
〜
p
(
⋅
∣
s
t
,
a
t
)
s_{t+1}〜p(·| s_t,a_t)
st+1〜p(⋅∣st,at)。在这项工作中,我们在部分可观测的马尔可夫决策过程(POMDP)中运行,其中agent收到的不是
s
∈
S
s\in \mathcal S
s∈S,而是只有环境真实状态部分信息的观测结果
o
∈
O
o\in\mathcal O
o∈O。
由于缺少agent通过存储的奖赏来推断的有关环境目标的信息,或者观测值是像素,因此状态信息是不完全的。
Online and Offline Reinforcement Learning。强化学习算法旨在最大化期望累积衰减奖赏,该算法被定义为奖赏的累积总和
∑
t
γ
t
r
t
\sum_t\gamma^tr_t
∑tγtrt。RL算法主要分为两类:(1)on-policy算法,其中agent直接最大化总奖赏的蒙特卡洛估计;(2)off-policy算法,其中agent学习并最大化一个价值函数,该函数负责估计总的未来奖赏。大多数RL算法通过与环境直接相互作用并反复试错来最大化奖赏。但是,off-policy RL最近成为RL的一个替代方案,其中agent旨在从由另一个agent收集的离线数据中提取具有最大化策略的奖赏。离线数据集由
(
s
,
a
,
r
)
(s,a,r)
(s,a,r)元组组成,这些元组通常用于训练一个off-policy agent。
Self-Attention and Transformers。self-attention操作首先将输入数据
X
X
X映射到三个独立的称为query
Q
Q
Q,key
K
K
K和value
V
V
V的
d
d
d维矩阵上。然后,这些向量通过注意力函数进行传递:
A
t
t
e
n
t
i
o
n
(
Q
,
K
,
V
)
=
s
o
f
t
m
a
x
(
Q
K
T
/
D
)
V
.
(1)
Attention(Q,K,V)=softmax(QK^T/\sqrt{D})V.\tag{1}
Attention(Q,K,V)=softmax(QKT/D)V.(1)
Q
K
T
QK^T
QKT项计算输入数据
X
X
X两个映射矩阵之间的点积。然后将点积归一化并使用缩放项
V
V
V将其投影回
d
d
d维矢量。Transformers利用自注意力作为网络结构的核心来处理序列数据,例如文本序列。Transformers通常通过一个预测字符的自监督目标进行预训练。常见的预测任务包括预测随机屏蔽的令牌或应用因果MASK并预测下一个字符。
Offline Policy Distillation。我们将把离线强化学习看作是序列预测任务的方法统一称为Offline Policy Distillation或Policy Distillation(PD)。与从离线数据中学习价值函数的方法不同,PD通过使用一个序列模型预测离线数据中的动作来抽取策略(即, behavior cloning),然后返回一个条件,或者过滤次优数据。最初PD被提出用来学习单任务策略,后来被扩展到从多样化离线数据中学习多任务策略。
In-Context Learning。in-context learning是指学习从上下文中推理任务的能力。例如,类似GPT-3或者Gopher等大规模语言模型,通过指定特定于任务的语言提示,能够被直接用于解决类似文本补全,代码生成以及文本摘要的任务。 这种从提示中推理任务的能力通常被称为上下文学习。我们使用在先前序列建模工作中使用的术语 in-weights learning 和 in-context learning 来区分具有参数更新的基于梯度的学习以及梯度无关的学习。
3.METHOD
在整个交互过程中,一个学习完毕的强化学习(RL)agent将表现出复杂的行为,例如探索,时间信用分配和计划。我们的关点是,无论agent所处的环境如何,agent的行为,内部结构以及实现都可以看作是其建模过去经验的函数,我们将其称为history。正式地,我们写为:
H
∋
h
t
:
=
(
o
0
,
a
0
,
r
0
,
.
.
.
,
o
t
−
1
,
a
t
−
1
,
r
t
−
1
,
o
t
,
a
t
,
r
t
)
=
(
o
≤
t
,
r
≤
t
,
a
≤
t
)
(2)
\mathcal H\ni h_t:=(o_0,a_0,r_0,...,o_{t-1},a_{t-1},r_{t-1},o_t,a_t,r_t)=(o_{\le t},r_{\le t},a_{\le t})\tag{2}
H∋ht:=(o0,a0,r0,...,ot−1,at−1,rt−1,ot,at,rt)=(o≤t,r≤t,a≤t)(2)
并且,我们将以长历史为条件的策略,称为algorithm:
P
:
H
∪
O
→
∇
(
A
)
,
(3)
P:\mathcal H\cup \mathcal O\rightarrow \nabla(\mathcal A),\tag{3}
P:H∪O→∇(A),(3)
其中
∇
(
A
)
\nabla(\mathcal A)
∇(A)表示在动作空间
A
\mathcal A
A上的概率分布空间。等式(3)表明,与policy类似,algorithm能够被扩展到环境中,以生成(观测,动作,奖赏)序列。为了描述简洁,我们将algorithm表示为
P
P
P,环境(即任务)表示为
M
\mathcal M
M,因此,对于任意给定任务
M
\mathcal M
M的学习历史,可以通过algorithm
P
M
P_{\mathcal M}
PM来生成:
(
O
0
,
A
0
,
R
0
,
.
.
.
,
O
T
,
A
T
,
R
T
)
∼
P
M
.
(4)
(O_0,A_0,R_0,...,O_T,A_T,R_T)\sim P_{\mathcal M}.\tag{4}
(O0,A0,R0,...,OT,AT,RT)∼PM.(4)
在这里,我们将随机变量表示为大写拉丁字母,例如
O
O
O,
A
A
A,
R
R
R,并用小写拉丁字母表示值,例如
o
o
o,
a
a
a,
r
r
r。通过将algorithm视为以长历史为条件的策略,我们假设任何能生成一组学习历史的算法都可以通过对动作进行 behavioral cloning 来蒸馏到神经网络中。接下来,我们提出一种方法,该方法将agent的交互建模为一个带有行为克隆的序列模型,以将长历史映射到动作的分布上。
3.1 ALGORITHM DISTILLATION
假设agent的交互过程(即学习历史)是由源算法
P
s
o
u
r
c
e
P^{source}
Psource在许多个单任务
{
M
n
}
n
=
1
N
\{M_n\}^N_{n=1}
{Mn}n=1N上生成的,从而得到数据集
D
\mathcal D
D:
D
:
=
{
(
o
0
(
n
)
,
a
0
(
n
)
,
r
0
(
n
)
,
.
.
.
,
o
T
(
n
)
,
a
T
(
n
)
,
r
T
(
n
)
)
∼
P
M
n
s
o
u
r
c
e
}
n
=
1
N
.
(5)
\mathcal D:=\bigg\{\bigg(o^{(n)}_0,a^{(n)}_0,r^{(n)}_0,...,o^{(n)}_T,a^{(n)}_T,r^{(n)}_T\bigg)\sim P^{source}_{\mathcal M_n}\bigg\}^N_{n=1}.\tag{5}
D:={(o0(n),a0(n),r0(n),...,oT(n),aT(n),rT(n))∼PMnsource}n=1N.(5)
然后,我们将源算法的行为蒸馏成一个序列模型,该序列模型使用负对数似然(NLL)将较长的历史映射到动作概率上,并将此过程称为algorithm distillation(AD)。在这项工作中,我们考虑了具有参数
θ
θ
θ的神经网络模型
P
θ
P_θ
Pθ,我们通过最小化下式损耗函数来训练该模型:
L
(
θ
)
:
=
−
∑
n
=
1
N
∑
t
=
1
T
−
1
l
o
g
P
θ
(
A
=
a
t
(
n
)
∣
h
t
−
1
(
n
)
,
o
t
(
n
)
)
.
(6)
\mathcal L(\theta):=-\sum^N_{n=1}\sum^{T-1}_{t=1}log~P_{\theta}(A=a^{(n)}_t|h^{(n)}_{t-1},o^{(n)}_t).\tag{6}
L(θ):=−n=1∑Nt=1∑T−1log Pθ(A=at(n)∣ht−1(n),ot(n)).(6)
直觉上,使用AD训练的具有固定参数的序列模型应该能够吸收源RL算法
P
s
o
u
r
c
e
P^{source}
Psource,并表现出类似复杂的行为,例如探索和时间信用分配。由于RL策略在源算法的整个学习历史中都改善了,因此准确的动作预测要求序列模型不仅从前一个上下文中推断当前策略,而且还可以推断出改进的策略,因此蒸馏该策略能改进运算。
3.2 PRACTICAL IMPLEMENTATION


















 2159
2159

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









