






摘要
Transformer 已成为许多SOTA的人工智能模型的首选架构,在各种人工智能应用中展示了卓越的性能。然而,Transformer 对内存的要求限制了它们处理长序列的能力,从而给在复杂环境中利用视频、动作和其他长序列和模态带来了挑战。我们提出了一种新的方法,即带有Block-wise Transformers的Ring Attention(Ring Attention),它利用自注意力和前馈的块式计算来跨多个设备分发长序列,同时将key-value块的通信与块式注意力的计算完全重叠。我们的方法能够对序列进行训练和推理,其长度比之前的内存高效 Transformer 所实现的序列长达设备的数倍,而无需进行近似或产生额外的通信和计算开销。关于语言建模和强化学习任务的广泛实验证明了我们的方法在允许数百万个token上下文大小和提高性能方面的有效性。(Code: https://github.com/lhao499/llm_large_context)
1.介绍
Transformer 已成为许多最先进的人工智能系统的支柱,这些系统在解决各种人工智能问题上表现出了令人印象深刻的性能。Transformer 通过使用自注意力和位置前馈机制的架构设计实现了这一成功。然而,扩大 Transformers 的上下文长度是一个挑战,因为 Transformers 固有的架构设计,即自注意力,其内存成本与输入序列长度呈二次方关系,这使得扩展到更长的输入序列具有挑战性。大型上下文 Transformer 对于解决各种人工智能挑战至关重要,从处理书籍和高分辨率图像到分析长视频和复杂的代码库。它们擅长从互连网络和超链接内容中提取信息,对于处理复杂的科学实验数据至关重要。上下文显着扩展的语言模型用例不断涌现:上下文长度为 16K 的 GPT-3.5、上下文长度为 32k 的 GPT-4、上下文长度为 65k 的 MosaicML 的 MPT 以及上下文长度为 100k 的 Anthropic 的 Claude。
在其重要性的推动下,人们对降低内存成本的研究兴趣日益高涨。一项研究利用了这样的观察结果:自注意力中的 softmax 矩阵可以在不具体化完整矩阵的情况下进行计算,这导致了自注意力和前馈的块式计算的发展,而无需进行近似。尽管内存减少了,但存储每层的输出仍然存在重大挑战。这种必要性源于自注意力的固有性质,涉及所有元素之间的相互作用(n对n相互作用)。后续层的自注意力依赖于访问前一层的所有输出。如果不这样做,就会成倍增加计算成本,因为必须为每个序列元素重新计算每个输出,这对于较长的序列来说是不切实际的。
这些组件有助于有效捕获输入token之间的远程依赖关系,并通过高度并行计算实现可扩展性。从内存需求来看,即使处理batch size为 1 的情况,对于隐藏大小为 1024 的普通模型来说,处理 1 亿个token也需要超过 1000GB 的内存。这远远大于当代 GPU 和 TPU 的容量,这些设备通常具有不到 100GB 的高带宽内存 (HBM)。
为了应对这一挑战,我们做出了一个关键的观察:通过以块方式执行自注意力和前馈网络计算,我们可以跨多个设备分配序列维度,从而允许并发计算和通信。这种见解源于这样一个事实:当我们逐块计算注意力时,结果对于这些块计算的顺序是不变的。我们的方法在主机之间分配计算块注意力的外循环,每个设备管理其各自的输入块。对于内部循环,每个设备计算特定于其指定输入块的块式注意力和前馈操作。主机设备形成一个概念环,其中在内循环期间,每个设备将用于块式计算的key-value块的副本发送到环中的下一个设备,同时从前一个设备接收键值块。只要块计算比块传输花费更长的时间,与标准transformer相比,重叠这些过程就不会增加开销。先前的工作中也研究了使用环形拓扑来计算自注意力,但它会产生类似于序列并行的非重叠通信开销,这使得它对于大上下文大小不可行。我们的工作利用块式并行transformer来大幅降低内存成本,在训练和推理过程中实现跨数千万个token的上下文大小的零开销缩放,并允许使用任意大的上下文大小。由于我们的方法通过transformer的分块计算来重叠环中主机之间的key-value块的通信,因此我们将其命名为带有分块并行 Transformers 环注意力(Ring Attention)。
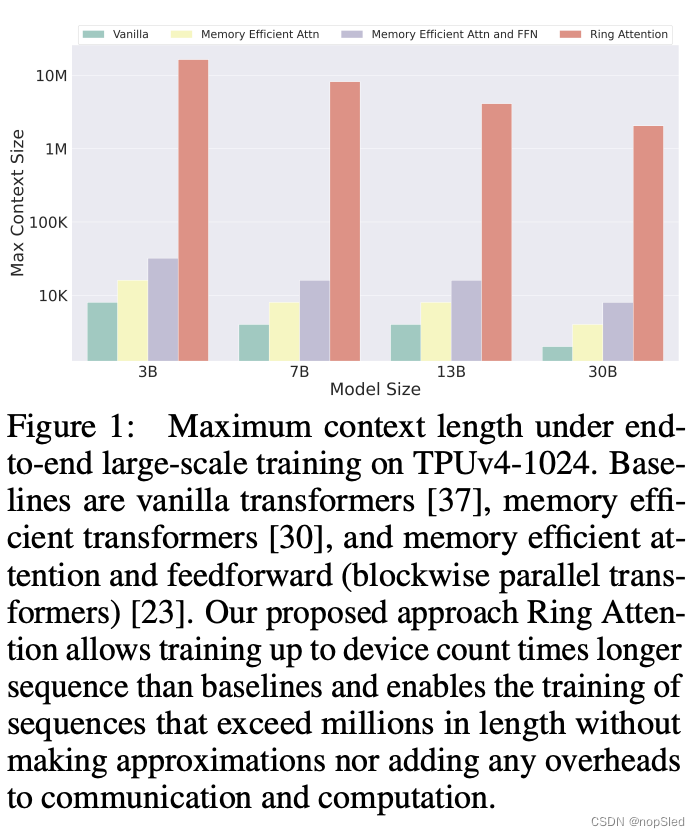
我们评估我们的方法在语言建模基准上的有效性。我们的实验表明,Ring Attention 可以降低 Transformer 的内存需求,使我们能够训练比之前内存高效SOTA长 500 倍以上的序列,并且能够在不进行近似的情况下训练长度超过 1 亿的序列。重要的是,Ring Attention 消除了单个设备施加的内存限制,使序列的训练和推理能力与设备数量成正比,从而基本上实现了近乎无限的上下文大小。
我们的贡献是双重的:(a)提出一种内存高效的transformer架构,允许上下文长度随着设备数量线性扩展,同时保持性能,消除单个设备带来的内存瓶颈,以及(b)证明我们方法的有效性通过大量的实验。
2.Large Context Memory Constraint
给定输入序列
Q
,
K
,
V
∈
R
s
×
d
Q, K, V ∈ \mathbb R^{s×d}
Q,K,V∈Rs×d,其中
s
s
s 是序列长度,
d
d
d 是头维度。我们将输出矩阵计算为:
A
t
t
e
n
t
i
o
n
(
Q
,
K
,
V
)
=
s
o
f
t
m
a
x
(
Q
K
T
d
)
V
,
Attention(Q,K,V)=softmax(\frac{QK^T}{\sqrt{d}})V,
Attention(Q,K,V)=softmax(dQKT)V,
其中 softmax 按行应用。每个自注意力子层都配有一个前馈网络,该网络分别且相同地应用于每个位置。这由两个线性变换组成,中间有一个 ReLU 激活。
F
F
N
(
x
)
=
m
a
x
(
0
,
x
W
1
+
b
1
)
W
2
+
b
2
.
FFN(x)=max(0,xW_1+b_1)W_2+b_2.
FFN(x)=max(0,xW1+b1)W2+b2.
Blockwise Parallel Transformers。先前的SOTA技术已经导致内存利用率的大幅降低,这是通过创新技术实现的,这些创新技术通过以逐块的方式计算注意力来实现计算。这些进步将注意力的内存开销降低到每层
2
b
s
h
2bsh
2bsh 字节,其中
b
b
b 表示批量大小,
s
s
s 表示序列长度,
h
h
h 表示模型的隐藏大小。为了进一步减少内存使用,blockwise parallel transformer(BPT)引入了一种策略,其中与每个自注意力子层相关的前馈网络以块式方式计算。这种方法有效地将前馈网络的最大激活大小从
8
b
s
h
8bsh
8bsh 限制到
2
b
s
h
2bsh
2bsh。有关内存效率的更详细分析,请参阅其中提供的讨论。总之,最先进的 Transformer 层的激活内存成本为
2
b
s
h
2bsh
2bsh。
Large Output of Each Layer。虽然 BPT 显着减少了 Transformer 中的内存需求,但它仍然对扩展上下文长度提出了重大挑战,因为它需要存储每层的输出。由于自注意力的固有性质,这种存储至关重要,它涉及所有元素之间的交互(n 到 n 交互)。如果没有这些存储的输出,后续层的自注意力在计算上就变得不切实际,需要对每个序列元素进行重新计算。简而言之,即使对于隐藏大小为 1024 的普通模型,处理批量大小为 1 的 1 亿个token也需要超过 1000GB 的内存。相比之下,现代 GPU 和 TPU 通常提供不到 100GB 的高带宽内存( HBM),并且 HBM 大幅扩张的前景受到物理限制和高制造成本的阻碍。
3.Ring Attention with Blockwise Parallel Transformers
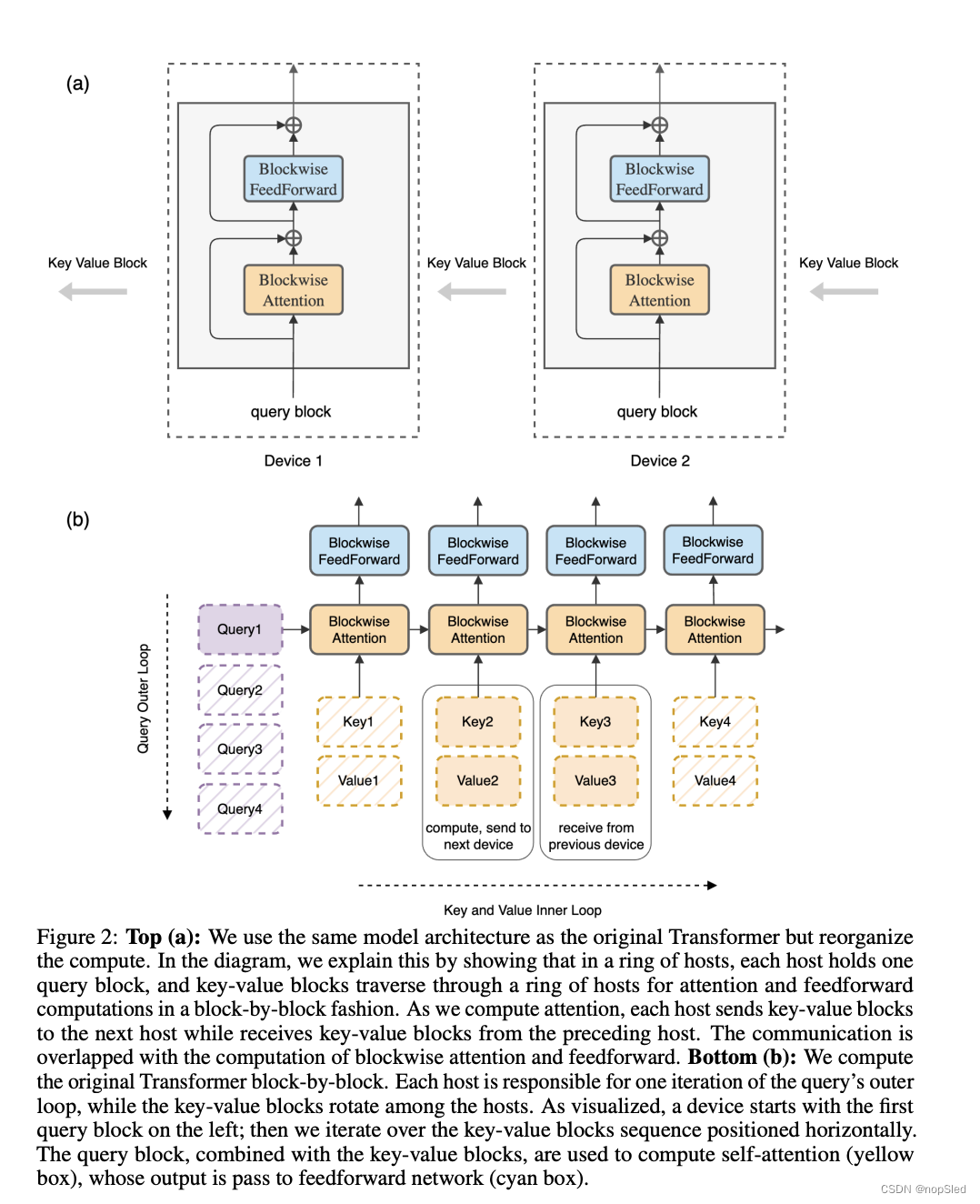
我们的主要目标是通过在多个主机之间有效地分配长序列而不增加开销来消除单个设备导致的内存限制。为了实现这一目标,我们提出了对blockwise parallel transformers(BPT)框架的增强。当将输入序列分布到不同的主机时,每个主机负责运行与其指定块相对应的块式注意力外循环的一个元素,以及特定于该块的前馈网络。这些操作不需要与其他主机进行通信。然而,在内循环中出现了一个挑战,它涉及到需要从其他主机获取块的key-value块以进行交互。由于每台主机仅拥有一个key-value块,因此从其他主机获取块的简单方法会导致两个重大问题。首先,当系统等待接收必要的key-value块时,它会引入计算延迟。其次,key-value块的积累导致内存使用量增加,这违背了降低内存成本的目的。
Ring-Based Blockwise Attention。为了解决上述挑战,我们利用内循环key-value块操作的排列不变性。这个属性源于这样一个事实:query块和一组key-value块之间的自注意力可以以任何顺序计算,只要正确组合每个块的统计数据以进行重新缩放即可。我们通过将所有主机概念化为以形成环形结构来利用此属性:host-1、host-2、…、host-N。当我们计算块式注意力和前馈时,每个主机通过同时将用于注意力计算的key-value块发送到下一个主机,同时从前一个主机接收key-value块,从而有效地重叠块传输与块计算,从而有效地进行协调。具体来说,对于任何
h
o
s
t
−
i
host-i
host−i,在计算其query块和key-value块之间的注意力时,它同时将key-value块发送到下一个
h
o
s
t
−
(
i
+
1
)
host-(i+1)
host−(i+1),同时接收来自前一个主机
h
o
s
t
−
(
i
−
1
)
host-(i−1)
host−(i−1)的key-value块。如果计算时间超过传输key-value块所需的时间,则不会产生额外的通信成本。这种重叠机制适用于我们方法的前向和后向传递,因为可以使用相同的操作和技术。之前的工作还提出利用环形拓扑来计算自注意力,旨在降低通信成本。我们的工作有所不同,它利用blockwise parallel transformers来大幅降低内存成本。正如我们在下一节中所示,这可以在训练和推理期间实现上下文大小的零开销缩放,并允许任意大的上下文大小。
Arithmetic Intensity Between Hosts。为了确定能够与计算时间重叠的传输所需的最小块大小,假设每个主机具有
F
F
F FLOPs,并且主机之间的带宽表示为
B
B
B。值得注意的是,我们的方法仅涉及环形配置中与当前主机的前一个和下一个主机的交互,因此我们的分析适用于 GPU 全部拓扑和 TPU 环面拓扑。让我们考虑变量:块大小表示为
c
c
c,隐藏大小表示为
d
d
d。当计算分块自注意力时,我们需要
2
d
c
2
2dc^2
2dc2 FLOPs 来使用query和key计算注意力分数,并需要额外的
2
d
c
2
2dc^2
2dc2 FLOPs 来将这些注意力分数乘以值,总共计算需求达到
4
d
c
2
4dc^2
4dc2 FLOPs。我们排除了qeury、key和value的投影以及分块前馈操作,因为它们只会增加计算复杂性,而不会增加主机之间的任何通信成本。这种简化导致更严格的条件,并且不会损害我们方法的有效性。在通信方面,key和valye块总共需要
2
c
d
2cd
2cd 字节。因此,组合通信需求为
4
c
d
4cd
4cd 字节。为了实现通信和计算之间的重叠,必须满足以下条件:
4
d
c
2
/
F
≥
4
c
d
/
B
4dc^2/F ≥ 4cd/B
4dc2/F≥4cd/B。这意味着块大小(表示为 c)应大于或等于
F
/
B
F/B
F/B。实际上,这意味着块大小需要大于 FLOP 与带宽的比率。
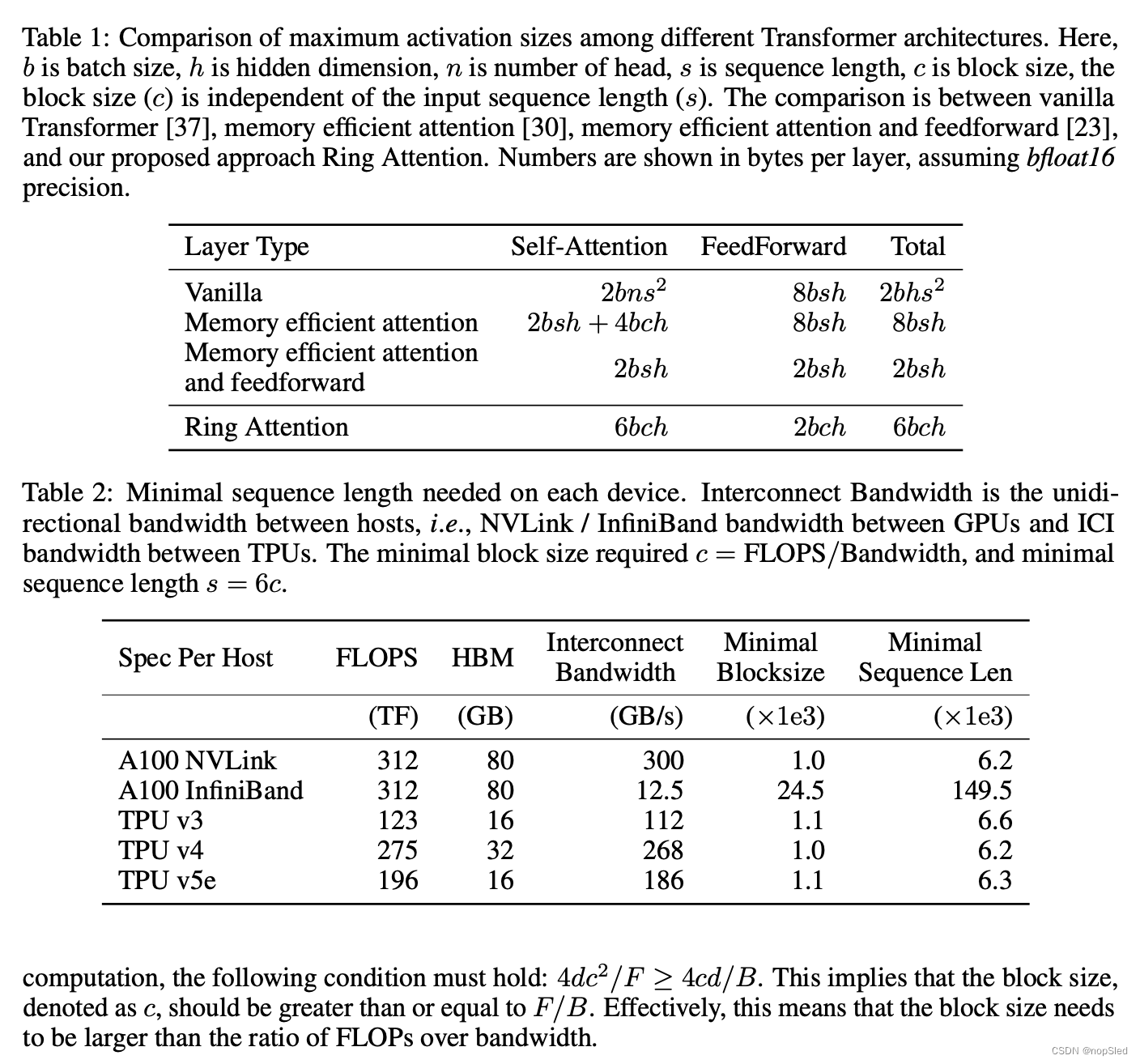
Memory Requirement。一台主机需要存储多个块,包括一个块大小用于存储当前query块,两个块大小用于当前key和value块,以及两个块大小用于接收key和value块。此外,存储分块注意力和前馈的输出需要一种块大小,因为输出保留query块的形状。因此,总共需要 6 个块,即
6
b
c
h
6bch
6bch 字节的内存。值得注意的是,分块前馈网络的最大激活大小为
2
b
c
h
2bch
2bch。因此,总的最大激活大小仍为
6
b
c
h
6bch
6bch 字节。表 1 详细比较了我们的方法和其他方法之间的内存成本。值得注意的是,我们的方法展示了相对于块大小
c
c
c 的线性内存缩放的优势,并且与输入序列长度
s
s
s 无关。
我们的分析表明,模型需要具有
s
=
6
c
s = 6c
s=6c 的序列长度,这是最小块大小的六倍。流行计算服务器的要求如表 2 所示。每个主机所需的最小序列长度(最右一列)在 6K 到 10K 之间变化,每个主机的最小块大小(最右第二列)对于 TPU 约为 1K以及具有高带宽互连的 GPU。对于通过 InfiniBand 连接的 GPU,其带宽较低,要求更加严格。这些要求很容易通过并行性(例如数据和张量并行性以及内存高效的块式注意力和前馈)来满足,我们将在实验第 5 节中展示这些要求。
Algorithm and Implementation。算法1提供了该算法的伪代码。Ring Attention 与内存高效transformers的现有代码兼容:Ring Attention 只需要在每个主机上本地调用任何可用的内存高效计算,并将主机之间的key-value块通信与分块计算重叠。我们使用集体操作 jax.lax.ppermute 在附近主机之间发送和接收key-value块。附录 A 中提供了 Jax 实现。

4.Setting
我们通过对最大序列长度和模型flops利用率进行基准测试来评估使用 Ring Attention 对改进 Transformer 模型的影响。
Model Configuration。我们的研究建立在 LLaMA 架构之上,我们在实验中考虑了 3B、7B、13B 和 30B 模型大小。
Baselines。我们通过将我们的方法与普通 Transformer 进行比较来评估我们的方法,普通 Transformer 通过全量注意力矩阵来计算自注意力并正常计算前馈网络,具有内存高效注意力的 Transformer 及其高效的 CUDA 实现,以及具有内存高效注意力和前馈的 Transformer。
Training Configuration。对于所有方法,我们遵循先前的工作,将完整的梯度checkpoint应用于注意力和前馈。实验在 GPU 和 TPU 上进行。对于 GPU,我们考虑具有 8 个 GPU 的单个 DGX A100 服务器和分布式 32 个 A100 GPU。我们还尝试了 TPU,从老一代的 TPUv3 到新一代的 TPUv4 和 TPUv5e。我们注意到,我们所有的结果都是使用全精度而不是混合精度获得的。

















 483
483

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









