







深度学习-李宏毅课程
Course Introduction
Rule Of ML
Regression
Basic Concept
Gradient Descent
Optimization for Deep Learning
Classification
Logistic Regression
Brief Introduction of Deep Learning
Backpropagation
Tips for Training DNN
Why Deep Learning
Convolutional Nerual Network
Graph Neural Network
Recurrent Neural Network
Semi-supervised Learning
un-supervised Learning
Explainable ML
Attack ML Models
Network Compression
Conditional Generation by RNN
Recursive
Transformer
New Architecture
Unsupervised Learning
Auto Encoder
Introduction of ELMO,BERT,GPT
Anomaly Detection
Generative Adversarial Network
Meta Learning
Life Long
Deep Reinforcement Learning
Introduce
1. 机器学习--自动找函数
- Speech Recognition
- Image Recognition
- Playing Go
- Dialogue System
2. 课程作业

Address:http://speech.ee.ntu.edu.tw/~tlkagk/courses_ML20.html
3. 交作业的一些细节
Regression
1. example of application
Estimating the combat power (cp) of a pokemon after evolution
1) find a model
2) goodness of Function
collect the data
Loss Function
Best Funtion
Gradient Descent :


容易陷入局部最优

Linear model: result bad

Polynomial Model:二次、三次 可能会造成 过拟合
引入 -> factors pokemon 物种
根据不同的物种选择合适的model
权重 -> 正则化 Regularization
reason:
 对于输入来说,权重影响的最小,即更加平滑
对于输入来说,权重影响的最小,即更加平滑
bias无须正则化 -> 它不影响平滑程度
Basic Concept
1. Bias and Variance of Estimator



解释:普通模型的方差比复杂模型的方差要小-->简单模型受数据的影响较小,例如 f(x)=c,则所有输出都为c,其variance就为0

解释:模型简单就越集中在一块,如果一块预测不准则都预测不准,所以导致bias大,复杂模型就反之
这就引入欠拟合和过拟合
2. Cross Validation

N-fold Cross Validation
Gradient Descent
skills:
1. Adaptive Learning Rate
随着迭代的次数应该越来越小

引入 -> Adagrad



一阶微分、二阶微分
Stochastic Gradient Descent
Feature Scaling

Question:

answer:incorrect

当多参数的时候,上图当前位置的前方(参数一)的低,右方(参数二)低,那下一次行动就会朝着右前方行动,但是其loss会变大
如何站在一点上,眼观一周找出最大的gradient -> Taylor Series




condition: learning rate 无穷小,下面才成立

21/3/21
Optimization for Deep Learning
1. 优化方法
- SGD 1847
- SGD with momentum 1986
- Adagrad 2011
- RMSProp 2013
- Adam 2015
2. On-line vs off-line
3. 具体
SGD

SGD with Momentum(SGDM)


Adagrad

RMSProp

Adam

4. Application
Adam vs SGDM

引入:SWATS: Begin with adam ,end with sgdm 2017
5. Adam
warm up : 需要在训练最初使用较小的学习率来启动,并很快切换到大学习率而后进行常见的 decay

6. kinds of optimizer



Classification
1.

2. Two Boxes 引入 贝叶斯公式









特征全部用上,其预测效果也不好
Modifying Model

steps

2. Posterior Probability 后验概率





Logistic Regression
1.



交叉熵





2. Cross Entropy vs Square Error

3. Discriminative vs Generative



example:



conclusion

Multi-class Classification


引入one-hot 编码
Limitation of Logistic Regression
下图:无法找到一条线将其分割开

如果必须要使用Logistic Regression 使用核函数 特征的高维映射
Cascading logistic regression models --> 神经网络


21/3/22
Brief Introduction of Deep Learning
1. develop

2. steps

3. How many layers? How many neurons for each layer
Trial nad Error + Intution
21/3/23
Backpropagation
Tips for Training DNN
1.

2. Do not always blame Overfitting

3. tips
3.1 Vanishing Gradient Problem
使用sigmoid function Δw变大,结果影响较小,则层层衰减,导致梯度消失 -> 改变 activate function ReLU

-> Leaky ReLU -> Maxout
Learnable activation function -- Maxout


3.2
3.2.1 L2和L1
L2:密集
L1:稀疏

WHY Deep Learning

1. Modularization 模块化 -> 有效
2. Anlogy 逻辑电路 类别 深度学习

example : 剪窗花

3. End-to-End learning


4. Complex Task
- very similar input,different output
- very different input,similar output



CNN
1. Why CNN for Image



2. The Whole CNN
2.1 Convolution
权值共享
2.2 what does CNN learn
2.2.1 convolution neural network

2.2.2 fully connected layer
特征组合

应用:Deep Dream




21/3/24
Graph Neural Network -> GNN
1. rb-tree -> graph
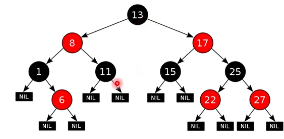

2. the function GNN


example: 推断凶手

简单的推断:

利用图信息:

如今的graph存在的问题:

这样就不能直接使用CNN,要进行变换
3. OutLine
Semi-Supervised Learning -- 半监督学习

3.1 Tasks,Dataset,and Benchmark

3.1.1 Spatial-based Convolution

1) MN4G(Neural Networks for Graph)


2) DCNN(Diffusion-Convolution Neural Network)



3) DGC(Diffusion Graph Convolution)

4) MoNet(Mixture Model Networks)


5) GAT(Graph Attention Networks) 自己学习weight

6)

3.1.2 Graph Signal Processing and Spectral-based GNN











4. ChebNet


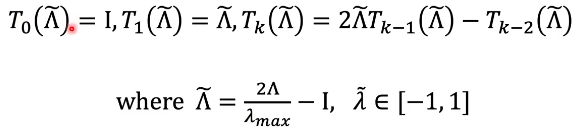
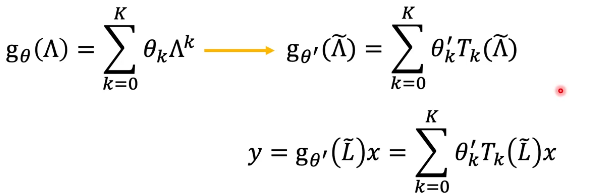



5. GCN

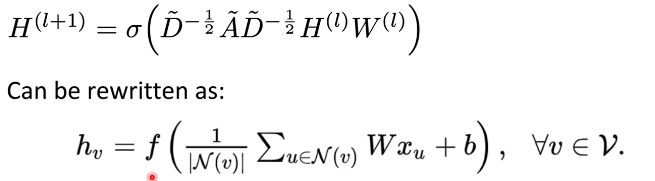
RNN
1. example





2. RNN
2.1 Base


2.2 Elman Network & Jordan Network

2.3 Bidirectional RNN

2.4 LSTM


example:






3. RNN Loss
解决方式:threshold if gradient > threshold else gradient


LSTM 解决Loss

2.5 GRU Gated Recurrent Unit
2.6 Many To One
情感分析
question:

引入CTC 语言辨识


machine translation


syntactic parsing:语法解析

sequence-to-sequence


4. Attention Model



21/3/25
Semi-supervised Learning

outline:
- Semi-supervised Learning for Generative Model
- Low-density Separationo Assumption
- Smoothness Assumption
- Better Representation
1. Semi-supervised Learning for Generative Model


2. Low-density Separation Assumption 非黑即白


交叉信息熵:

3. Smoothness Assumption


机器学习中的:cluster and then label
4. Graph-based Approach


How to use : 定量


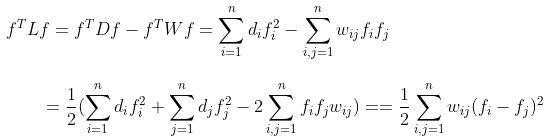

5. Better Representation
un-supervised Learning
1. world embedding belongs to unsupervised
auto-encoder doesn't work



2. Count based

3. Prediction-based



Training:


4. world Embedding
Explainable ML
1.



2. some model interpretable and powerful at the same time
example: Decision Tree -> Forest
3. Local Explanation
3.1 Basic Idea



example:

实验:随便堆砌几个卷积网络层



然而。。。 实际什么都没有学到
3.2 Activation Maximization
加入R

3. Global Explanation 控制它产生想要的图像

4. Using A Model Explain Another
4.1 Linear Model




4.2 Decision Tree


5. Attribution
6. Probing
7. Generative CNN

21/3/30
Attack ML Models
1. Attack
example:

attack ways:
Training
- Non-targeted Attack
- Targeted Attrack


21/3/31
2. how to attack


example:




3. what happened

4. reference

5. attack approaches
5.1 FGSM


5.2 white box vs black box

exmaple:


5.3 Universal Adversarial Attack 普遍对抗性攻击
5.4 Adversarial Reprogramming

5.5 Attack in the real world
人脸辨识系统:


交通标志:

6. Defense
6.1

example:




6.2

7. Attack on Image

7.1 one pixel attack



how do we find the exact pixel and value
不追求最好,追求攻击成功就行:

引入: Differential Evolution



example:

first step


second step


third step

fourth step
start from the second step


21/4/7
Network Compression
1. Network to Mobile
2. Network Pruning -> 网络剪枝
2.1

2.2 Why Pruning

example:


2.3 issue


3. Konowledge distillation 知识蒸馏

paper:

3.1

4. Parameter Quantization 量化参数

5. low rank approximation

引入 Depthwise Separable Convolution






6. dynamic computation

21/4/13
Conditional Generation By RNN
1. Generation
generating a structured object component-by-component
example:
1) sentences are composed of characters/words

2) Images are composed of pixels


2. Attention

3. Tips for Generation

21/4/14
4. Pointer Network
为解决的问题之一:给一组数据点,选择其中的点连成线,并且这个圈能够将剩余的点包围起来
Recursive

example:
1)



2)


3)






Transformer -- 变形金刚
1. Seq2seq model with "self-attention"


self-attention: paper--arxiv.org/abs/1706.03762 attention is all you need
2.






3.




4.




5.


6.



21/4/15
New Architecture
1. FCN CNN RNN
2.
Follow up SOTA structure
SOTA全称是state of the art,是指在特定任务中目前表现最好的方法或模型。
Benchmark和baseline都是指最基础的比较对象

3. transformer 改进
3.1 仅交换层次结构:fnn 与 self-attention交换顺序
--> Sandwich transform




3.2

3.3

4. BERT Bidirectional Encoder Representation from Transformers,

4.1 ALBERT



5. REFORMER
6. Style GAN
Unsupervised Learning
1.

1.1

1.2

2.

3.


21/4/20
3.1 PCA






SVD





example:
PCA-pokmon

推荐系统:

Unsupervised Learning -- Neighbor Embedding
1.

2.




3.

4. t-SNE
散度公式
Auto-encoder
1.

2.



3. Auto-encoder Text Retrieval

4. Similar Image Search
21/4/27
5.





Putting Words into Computers: Introduction of ELMO,BERT,GPT
1. 1-of-N Encoding vs World Embedding


每个单词在不同语境下由不同的意思 -->引入 ELMO(Embeddings from Language Model)

2. ELMO(Embeddings from Language Model)


3. BERT(Bidirectonal Encoder Representations from Transformers)

训练方式:






GPT(Generative Pre-Training)

https://talktotransformer.com GPT
Self-Supervised Learning
1.


2.

Anomaly Detection
1.

2.
fraud detection
attack detection
3.



21/4/28
任务机制

4. 最大似然估计

GMM(Gaussian Mixture Model)





5.

21/5/7
Generative Adversarial Network
1. the gan zoo github
2.
- basic idea of gan
- gan as structured learning
- gan generator learn by itself
- can discriminator generate
- a little bit theory
3.
3.1



3.2 step
1)

2)

3)

4. Structured Learning Approach
5.


6.

21/5/9
7. Text-to-Image



8. Image-to-Image
Unsupervised Conditional Generation
1.

2.

3. theroy behind the gan














3.2 fGan


21/5/10
Meta Learning
1. Meta learning = learn to learn



2.
2.1 step one: Define a set of learning algorithm
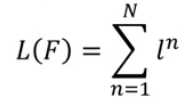



2.2 find the best function F*


3. example:Omniglot


4.

4.1 MAML




4.1 EXAMPLE


5. Math


5. Reptile

6.

21/5/11
Life Long
1. define:


example





--> Catastrophic Forgetting(灾难性遗忘)

solve:





2.

3.

4.

Deep Reinforcement Learning
1.

example

2.

2.1

3.








4.



MuZero















 1329
1329











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









