







网络程序设计学习心得
项目跟进情况
A1:神经网络实现手写字符识别系统
这个项目虽然没有检查,但我还是认真地阅读了源代码,对神经网络图像识别有了大概的了解。通俗地说,这个程序就是把一幅图像按照像素点变换为一个向量,之后进行拟合。
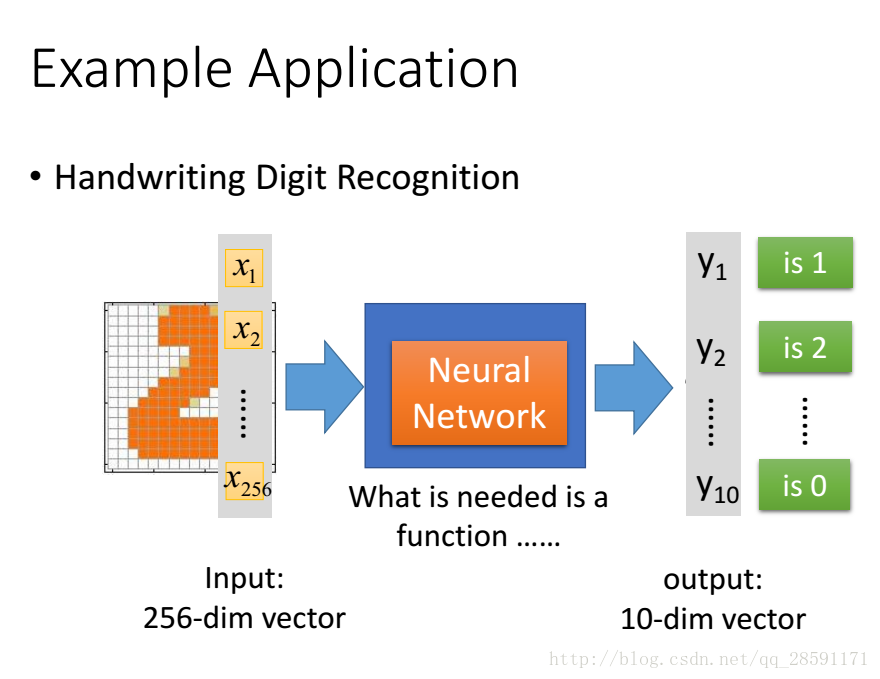
我尝试过对它进行了一些小的改进,比如用ReLU函数替换sigmoid函数,即把ocr.py改为:
# -*- coding: UTF-8 -*-
import csv
import numpy as np
from numpy import matrix
from math import pow
from collections import namedtuple
import math
import random
import os
import json
class OCRNeuralNetwork:
LEARNING_RATE = 0.1
WIDTH_IN_PIXELS = 20
# 保存神经网络的文件路径
NN_FILE_PATH = 'nn.json'
def __init__(self, num_hidden_nodes, data_matrix, data_labels, training_indices, use_file=True):
# relu函数
self.relu = np.vectorize(self._relu_scalar)
# relu求导函数
self.relu_prime = np.vectorize(self._relu_prime_scalar)
# 决定了要不要导入nn.json
self._use_file = use_file
# 数据集
self.data_matrix = data_matrix
self.data_labels = data_labels
if (not os.path.isfile(OCRNeuralNetwork.NN_FILE_PATH) or not use_file):
# 初始化神经网络
self.theta1 = self._rand_initialize_weights(400, num_hidden_nodes)
self.theta2 = self._rand_initialize_weights(num_hidden_nodes, 10)
self.input_layer_bias = self._rand_initialize_weights(1, num_hidden_nodes)
self.hidden_layer_bias = self._rand_initialize_weights(1, 10)
# 训练并保存
TrainData = namedtuple('TrainData', ['y0', 'label'])
self.train([TrainData(self.data_matrix[i], int(self.data_labels[i])) for i in training_indices])
self.save()
else:
# 如果nn.json存在则加载
self._load()
def _rand_initialize_weights(self, size_in, size_out):
return [((x * 0.12) - 0.06) for x in np.random.rand(size_out, size_in)]
def _relu_scalar(self, z):
if(z>0):
return z
return 0
def _relu_prime_scalar(self, z):
if(z>0):
return 1
return 0
def train(self, training_data_array):
for data in training_data_array:
# 前向传播得到结果向量
y1 = np.dot(np.mat(self.theta1), np.mat(data.y0).T)
sum1 = y1 + np.mat(self.input_layer_bias)
y1 = self.relu(sum1)
y2 = np.dot(np.array(self.theta2), y1)
y2 = np.add(y2, self.hidden_layer_bias)
y2 = self.relu(y2)
# 后向传播得到误差向量
actual_vals = [0] * 10
actual_vals[data.label] = 1
output_errors = np.mat(actual_vals).T - np.mat(y2)
hidden_errors = np.multiply(np.dot(np.mat(self.theta2).T, output_errors), self.relu_prime(sum1))
# 更新权重矩阵与偏置向量
self.theta1 += self.LEARNING_RATE * np.dot(np.mat(hidden_errors), np.mat(data.y0))
self.theta2 += self.LEARNING_RATE * np.dot(np.mat(output_errors), np.mat(y1).T)
self.hidden_layer_bias += self.LEARNING_RATE * output_errors
self.input_layer_bias += self.LEARNING_RATE * hidden_errors
def predict(self, test):
y1 = np.dot(np.mat(self.theta1), np.mat(test).T)
y1 = y1 + np.mat(self.input_layer_bias) # Add the bias
y1 = self.relu(y1)
y2 = np.dot(np.array(self.theta2), y1)
y2 = np.add(y2, self.hidden_layer_bias) # Add the bias
y2 = self.relu(y2)
results = y2.T.tolist()[0]
return results.index(max(results))
def save(self):
if not self._use_file:
return
json_neural_network = {
"theta1":[np_mat.tolist()[0] for np_mat in self.theta1],
"theta2":[np_mat.tolist()[0] for np_mat in self.theta2],
"b1":self.input_layer_bias[0].tolist()[0],
"b2":self.hidden_layer_bias[0].tolist()[0]
};
with open(OCRNeuralNetwork.NN_FILE_PATH,'w') as nnFile:
json.dump(json_neural_network, nnFile)
def _load(self):
if not self._use_file:
return
with open(OCRNeuralNetwork.NN_FILE_PATH) as nnFile:
nn = json.load(nnFile)
self.theta1 = [np.array(li) for li in nn['theta1']]
self.theta2 = [np.array(li) for li in nn['theta2']]
self.input_layer_bias = [np.array(nn['b1'][0])]
self.hidden_layer_bias = [np.array(nn['b2'][0])]
但是很遗憾效果没有明显地提升,所以没有pr。
A2:血常规检验报告的图像OCR识别
现在采用的程序的基本思想是调用CV2模块的findContours提取矩形轮廓,筛选对角线大于阈值的轮廓,而我计划采用霍夫变换进行图像检测,但只写了一部分,最后完成的代码为(Python):
# -*- coding:utf-8 -*-
import cv2
import numpy as np
import traceback
def houghtransform(path):
'''使用霍夫变换来检测直线,path为图片存储路径'''
img = cv2.imread(path)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
#print('成功转换为灰度图...')
edges = cv2.Canny(gray, 100, 175, apertureSize=3)
'''边缘检测'''
midpointlist = []
lines = cv2.HoughLines(edges, 1, np.pi / 180, 200)
for rho, theta in lines[0]:
a = np.cos(theta)
b = np.sin(theta)
x0 = a * rho
y0 = b * rho
x1 = float(x0 + 5000 * (-b))
y1 = float(y0 + 5000 * (a))
x2 = float(x0 - 5000 * (-b))
y2 = float(y0 - 5000 * (a))
#cv2.line(img,(x1,y1),(x2,y2),(0,0,255),2)
if(x2-x1==0):
continue
k = (y2 - y1) / (x2 - x1)
if(k>0.5 or k<-0.5):
'''这里本来是要求用户拍照保持三条主要直线水平,否则不予通过。当然现在采用的程序可以对图像进行旋转操作'''
continue
b = y1 - k * x1
midpoint = k * (img.shape[1] / 2) + b
midpointlist.append(midpoint)
return</ 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3635
3635

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









