







转换算子
一个流的转换操作将会应用在一个或者多个流上面,这些转换操作将流转换成一个或者多个输出流,将这些转换算子组合在一起来构建一个数据流图。大部分的数据流转换操作都是基于用户自定义函数udf。udf函数打包了一些业务逻辑并定义了输入流的元素如何转换成输出流的元素。像MapFunction这样的函数,将会被定义为类,这个类实现了Flink针对特定的转换操作暴露出来的接口。DataStream API针对大多数数据转换操作提供了转换算子,这里将转换算子分为四类:
-
基本转换算子:将会作用在数据流中的每一条单独的数据上
-
KeyedStream转换算子:在数据有key的情况下,对数据应用转换算子。
-
多流转换算子:合并多条流为一条流或者将一条流分割为多条流
-
分布式转换算子:将重新组织流里面的事件。
下面将分别讲解这四种算子类型。
基本转换算子
基本转换算子会针对流中的每一个单独的事件做处理,也就是说每一个输入数据会产生一个输出数据。单值转换,数据分割,数据过滤,都是基本转换操作的典型例子.
map
类型转换:DataStream → DataStream
作用:map算子将每一个输入的事件传送到用户自定义的一个mapper,这个mapper只返回一个输出事件
实现原理:底层调用的是transform方法,真正实现逻辑封装在StreamMap类中,该类底层实现了OneInputStreamOperator接口,在processElement方法中实现具体的功能
public <R> SingleOutputStreamOperator<R> map(MapFunction<T, R> mapper, TypeInformation<R> outputType) {
return transform("Map", outputType, new StreamMap<>(clean(mapper)));
}
操作案例:将字符串转为大写
方式一:直接调用原生的map算子
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> socketTextStream = env.socketTextStream("localhost", 8888);
//方式一:调用原生自带的map算子
SingleOutputStreamOperator<String> wordSource = socketTextStream.map(word -> word.toUpperCase());
wordSource.print();
env.execute();
方式二:调用底层的transform算子重定义实现
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> socketTextStream = env.socketTextStream("localhost", 8888);
//方式二:
SingleOutputStreamOperator<String> wordSource = socketTextStream.transform("MyMap", TypeInformation.of(String.class), new StreamMap<>(String::toUpperCase));
wordSource.print();
env.execute();
方式三:继承实现类自定义实现
/**
* 类似于StreamMap操作
*/
static class MyStreamMap extends AbstractStreamOperator<String> implements OneInputStreamOperator<String, String> {
@Override
public void processElement(StreamRecord<String> element) throws Exception {
String elementValue = element.getValue();
output.collect(element.replace(elementValue.toUpperCase()));
}
}
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> socketTextStream = env.socketTextStream("localhost", 8888);
SingleOutputStreamOperator<String> wordSource = socketTextStream.transform("MyStreamMap", TypeInformation.of(String.class), new MyStreamMap());
wordSource.print();
env.execute();
方式四:实现RichMapFunction类
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> socketTextStream = env.socketTextStream("localhost", 8888);
SingleOutputStreamOperator<String> wordSource = socketTextStream.map(new RichMapFunction<String, String>() {
/**
* 在构造对象之后,执行map方法之前执行一次
* 通常用于初始化工作,例如连接创建等
* @param parameters
* @throws Exception
*/
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
}
/**
* 在关闭subtask之前执行一次,例如做一些释放资源的工作
* @throws Exception
*/
@Override
public void close() throws Exception {
super.close();
}
@Override
public String map(String s) throws Exception {
int indexOfThisSubtask = getRuntimeContext().getIndexOfThisSubtask();
return indexOfThisSubtask + ":" + s.toUpperCase();
}
});
wordSource.print();
env.execute();
flatmap
类型转换:DataStream → DataStream
作用:和map算子比较类似,不同之处在于针对每一个输入事件flatMap会生成0个、1个或多个输出元素。
实现原理:同map实现原理一样,底层调用的是transform方法,真正实现逻辑封装在StreamMap类中,该类底层实现了OneInputStreamOperator接口,在processElement方法中实现具体的功能
操作案例:将一行记录按照空格分割,并转换为大写
方式一:直接调用原生算子,其他方式同map算子
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> socketTextStream = env.socketTextStream("localhost", 8888);
SingleOutputStreamOperator<String> flatMap = socketTextStream.flatMap(new FlatMapFunction<String, String>() {
@Override
public void flatMap(String s, Collector<String> collector) throws Exception {
Arrays.stream(s.split(" ")).forEach(word -> collector.collect(word.toUpperCase()));
}
});
flatMap.print();
env.execute("FlatMapDemo");
//如输入 a b c
//最后输出
A
B
C
filter
类型转换:DataStream → DataStream
作用:通过在每个输入事件上对一个布尔条件进行求值来过滤掉一些元素,然后将剩下的元素继续发送。一个true的求值结果会把输入事件保留下来并发送到输出,而如果求值结果为false,则输入事件会被抛弃掉
实现原理:底层调用的是transform方法,真正实现逻辑封装在StreamFilter类中,该类底层实现了OneInputStreamOperator接口,在processElement方法中实现具体的功能
操作案例:仅保留以A开头的字符串
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> socketTextStream = env.socketTextStream("localhost", 8888);
socketTextStream.filter(word->word.startsWith("A")).print();
env.execute("FilterDemo");
//如输入
bca
ad
Ab
Ac
//最后得到的结果为
Ab
Ac
KeyedStream转换算子(通常和window配合使用)
KeyBy
类型转换:DataStream → KeyedStream
作用:其实就是按照key进行分组,根据不同的key分配到不同的分区中,所有具有相同key的事件会在同一个slot中进行处理
实现原理:
-
根据key进行hash运算得到hash值,即变量keyHash
-
使用murmurHash公式进行计算,即调用murmurHash(keyHash)
-
对murmurHash和最大并行度进行求余运算得到变量keyGroupId = murmurHash%maxParallelism
-
计算并行度索引Index = (keyGroupId*parallelism)/maxParallelism
public static int assignKeyToParallelOperator(Object key, int maxParallelism, int parallelism) {
Preconditions.checkNotNull(key, "Assigned key must not be null!");
return computeOperatorIndexForKeyGroup(maxParallelism, parallelism, assignToKeyGroup(key, maxParallelism));
}
//1.计算key的hashCode值
public static int assignToKeyGroup(Object key, int maxParallelism) {
Preconditions.checkNotNull(key, "Assigned key must not be null!");
return computeKeyGroupForKeyHash(key.hashCode(), maxParallelism);
}
//2.使用murmurHash进行计算,并和最大并行度进行求余运算
public static int computeKeyGroupForKeyHash(int keyHash, int maxParallelism) {
return MathUtils.murmurHash(keyHash) % maxParallelism;
}
//3.计算获取索引
public static int computeOperatorIndexForKeyGroup(int maxParallelism, int parallelism, int keyGroupId) {
return keyGroupId * parallelism / maxParallelism;
}
操作案例:基于key进行求和统计
方式一:针对Tuple类型,使用下标进行分组
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> socketTextStream = env.socketTextStream("localhost", 8888);
socketTextStream.map(word-> Tuple3.of(word.split(" ")[0],word.split(" ")[1],Double.valueOf(word.split(" ")[2])))
.returns(TupleTypeInfo.getBasicTupleTypeInfo(String.class,String.class,Double.class))
.keyBy(t->t.f0+t.f1 ) //这里不支持 In many cases lambda methods don't provide enough information for automatic type extraction
.sum(2)
.print();
env.execute("KeyByDemo");
方式二:针对Bean,使用字段名称进行分组
注意:该种方式下,Bean中的字段不能私有化,且必须要有无参构造器
WordCount Bean
public class WordCount {
public String word;
public Integer count;
public WordCount() {
}
public WordCount(String word, Integer count) {
this.word = word;
this.count = count;
}
public static WordCount of(String word, Integer count) {
return new WordCount(word, count);
}
public String getWord() {
return word;
}
public void setWord(String word) {
this.word = word;
}
public Integer getCount() {
return count;
}
public void setCount(Integer count) {
this.count = count;
}
@Override
public String toString() {
return "WordCount{" +
"word='" + word + '\'' +
", count=" + count +
'}';
}
}
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> socketTextStream = env.socketTextStream("localhost", 8888);
socketTextStream.map(words->WordCount.of(words,1))
.returns(WordCount.class)
.keyBy(WordCount::getWord)
.sum("count")
.print();
方式三:实现KeySelector类
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> socketTextStream = env.socketTextStream("localhost", 8888);
socketTextStream.map(word -> Tuple3.of(word.split(" ")[0], word.split(" ")[1], Double.valueOf(word.split(" ")[2])))
.returns(TupleTypeInfo.getBasicTupleTypeInfo(String.class, String.class, Double.class))
.keyBy(new KeySelector<Tuple3<String, String, Double>, String>() {
@Override
public String getKey(Tuple3<String, String, Double> value) throws Exception {
return value.f0 + value.f1;
}
})
.sum(2)
.print();
env.execute("KeyByDemo");
fold(已过时)
类型转换:KeyedStream → DataStream
作用:合并当前元素和前一次折叠操作的结果,并产生一个新的值,返回的流中包含每一次折叠的结果,而不是只返回最后一次折叠的结果
实现原理:还是调用transform方法,逻辑封装在StreamGroupedFold类中,该类实现了OneInputStreamOperator和OutputTypeConfigurable接口,其中有一个value的判断逻辑
OUT value = values.value();
//如果前一次折叠的结果不为空,则和当前结果进行合并,并更新,否则取当前结果(即初始化)
if (value != null) {
OUT folded = userFunction.fold(outTypeSerializer.copy(value), element.getValue());
values.update(folded);
output.collect(element.replace(folded));
} else {
OUT first = userFunction.fold(outTypeSerializer.copy(initialValue), element.getValue());
values.update(first);
output.collect(element.replace(first));
}
操作案例:按照key进行sum求和
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> socketTextStream = env.socketTextStream("localhost", 8888);
socketTextStream.flatMap((String words, Collector<Tuple2<String,Integer>> out)-> Arrays.stream(words.split(" ")).forEach(word-> out.collect(Tuple2.of(word,1)) ))
.returns(TupleTypeInfo.getBasicTupleTypeInfo(String.class,Integer.class))
.keyBy(t->t.f0)
.fold(Tuple2.of("", 0), new FoldFunction<Tuple2<String, Integer>, Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> fold(Tuple2<String, Integer> tuple2, Tuple2<String, Integer> o) throws Exception {
//tuple2为中间存储的结果或初始化值
o.f1 = o.f1 + tuple2.f1;
return o;
}
}).print();
env.execute("FoldDemo");
//如输入
a 10
a 20
a 30
//最后得到
a 60
sum/min/minBy/max/maxBy
类型转换:KeyedStream → DataStream
作用:分组数据流上的滚动聚合操作,即按照key进行求最大值/最小值/求和等操作。这里只给出min和minBy的区别,其他都类似。
其中min和minBy的区别是min返回的是一个最小值,而minBy返回的是其字段中包含最小值的元素,返回的流中包含每一次聚合的结果,而不是只返回最后一次聚合的最终结果。
通俗来讲当有多个字段时,min的作用是对其中指定字段进行分组取最小值,而不关心其他字段,结果中只会取第一次出现的字段;而minBy按照指定字段返回最小值所在的记录,其中有一个布尔值参数,当为false时,则取最小值的最新记录
实现原理:底层调用的还是transform方法,具体的实现逻辑封装在StreamGroupedReduce类中,该类也是实现了OneInputStreamOperator接口
IN value = element.getValue();
IN currentValue = values.value();
//可以看到最底层调用的其实是用户自定义函数
if (currentValue != null) {
IN reduced = userFunction.reduce(currentValue, value);
values.update(reduced);
output.collect(element.replace(reduced));
} else {
values.update(value);
output.collect(element.replace(value));
}
操作案例:一条记录中包含3个字符,用逗号分隔,最后一个字符为整数类型,按照切分后的第一个字段为key取最小值
方式一:调用minBy算子,first参数为false
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> socketTextStream = env.socketTextStream("localhost", 8888);
socketTextStream.map(word -> Tuple3.of(word.split(",")[0], word.split(",")[1], Integer.valueOf(word.split(",")[2])))
.returns(TupleTypeInfo.getBasicTupleTypeInfo(String.class, String.class, Integer.class))
.keyBy(t -> t.f0)
.minBy(2,false)
.print();
env.execute("MinMinByDemo");
//如输入
hadoop,spark,1
hadoop,hadoop,2
hadoop,spark,10 -->根据hadoop为key,取最小值
spark,hadoop,50
spark,test,40
spark,teste,100
spark,hadoop,200 -->根据spark为key,取最小值
//结果输出
4> (hadoop,spark,1)
4> (hadoop,spark,1)
4> (hadoop,spark,1)
1> (spark,hadoop,50)
1> (spark,test,40)
1> (spark,test,40)
1> (spark,test,40)
方式二:调用minBy算子,first参数为true
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> socketTextStream = env.socketTextStream("localhost", 8888);
socketTextStream.map(word -> Tuple3.of(word.split(",")[0], word.split(",")[1], Integer.valueOf(word.split(",")[2])))
.returns(TupleTypeInfo.getBasicTupleTypeInfo(String.class, String.class, Integer.class))
.keyBy(t -> t.f0)
.minBy(2,false)
.print();
//如输入
spark,hadoop,50
spark,test,40
spark,teste,100
spark,hadoop,200
flink,hadoop,400
spark,Hadoop,400
flink,spark,300
flink,java,500
flink,spark,400
flink,es,100
spark,java,300
spark,flink,300
flink,java,50
//最终输入
1> (spark,hadoop,50)
1> (spark,test,40)
1> (spark,test,40)
1> (spark,test,40)
4> (flink,hadoop,400)
1> (spark,test,40)
4> (flink,spark,300)
4> (flink,spark,300)
4> (flink,spark,300)
4> (flink,es,100)
1> (spark,test,40)
1> (spark,test,40)
4> (flink,java,50) --即获取最小值所在的记录
方式三:调用min算子
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> socketTextStream = env.socketTextStream("localhost", 8888);
socketTextStream.map(t -> Tuple2.of(t.split(",")[0], Integer.valueOf(t.split(",")[1])))
.returns(TupleTypeInfo.getBasicTupleTypeInfo(String.class, Integer.class))
.keyBy(t -> t.f0)
.min(1)
.print();
env.execute();
reduce
类型转换:KeyedStream → DataStream
作用:合并当前元素和上次聚合的结果,产生一个新值,和fold算子比较类似
实现原理:和fold算子一致
操作案例:简单的单词统计
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> socketTextStream = env.socketTextStream("localhost", 8888);
socketTextStream.flatMap((String words, Collector<Tuple2<String,Integer>> out)-> Arrays.stream(words.split(" ")).forEach(word->out.collect(Tuple2.of(word,1))))
.returns(TupleTypeInfo.getBasicTupleTypeInfo(String.class,Integer.class))
.keyBy(t->t.f0)
.reduce(new ReduceFunction<Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> reduce(Tuple2<String, Integer> stringIntegerTuple2, Tuple2<String, Integer> t1) throws Exception {
stringIntegerTuple2.f1 = stringIntegerTuple2.f1 + t1.f1;
return stringIntegerTuple2;
}
})
.print();
env.execute("ReduceByDemo");
//如输入
a
b
c
d
e
a
f
d
a
d
c
//最终结果为
3> (a,1)
1> (b,1)
2> (c,1)
3> (d,1)
1> (e,1)
3> (a,2)
1> (f,1)
3> (d,2)
3> (a,3)
3> (d,3)
2> (c,2)
多流转换算子
union
类型:多个DataStream→ DataStream
作用:对两个或两个以上的DataStream进行union操作,产生一个包含所有DataStream元素的新DataStream
实现原理:底层会重新创建一个DataStream对象,并把原来老的多个DataStream对象放到一个list表中,进行校验类型是否一致,其中DataStream构造器参数有一个UnionTransformation类,底层继承了Transformation类
List<Transformation<T>> unionedTransforms = new ArrayList<>();
unionedTransforms.add(this.transformation);
for (DataStream<T> newStream : streams) {
if (!getType().equals(newStream.getType())) {
throw new IllegalArgumentException("Cannot union streams of different types: "
+ getType() + " and " + newStream.getType());
}
unionedTransforms.add(newStream.getTransformation());
}
return new DataStream<>(this.environment, new UnionTransformation<>(unionedTransforms));
操作案例:合并元素
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<Integer> source1 = env.fromElements(1, 2, 3, 4, 5);
DataStreamSource<Integer> source2 = env.fromElements(11, 22, 33, 44, 55);
DataStream<Integer> unionSource = source1.union(source2);
unionSource.print();
env.execute();
connect
类型:DataStream,DataStream → ConnectedStreams
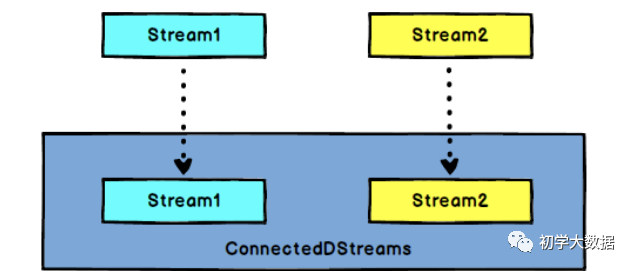
作用:连接两个保持各自类型的数据流,两个流被connect之后,只是被放在了同一个流中,但是内部仍然是保持着各自的数据类型和形式,并且相互独立实现原理:内部重新创建了一个ConnectedStreams对象,且该对象内部重写了大部分常用算子,包含上面总结的算子,但是算子名称和基本算子不太一致,如map算子称为Co-Map,flatMap算子成为Co-Flat Map
操作案例:字符串和int类型DataStream进行关联,并增加不同的前缀
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<Integer> stream1 = env.fromElements(1, 2, 3, 4, 5);
DataStreamSource<String> streamStr = env.fromElements("hello", "str", "good");
ConnectedStreams<Integer, String> connect = stream1.connect(streamStr);
connect.map(new CoMapFunction<Integer, String, String>() {
@Override
public String map1(Integer value) throws Exception {
return "hhhh1"+value;
}
@Override
public String map2(String value) throws Exception {
return "11111"+value;
}
}).print();
env.execute("ConnectDemo");
}
//最后结果为
2> hhhh13
3> 11111hello
4> hhhh11
1> hhhh12
1> 11111good
4> 11111str
4> hhhh15
3> hhhh14
分布式转换算子
针对于flink的分区,有五种类型:shuffle,轮询,global,广播和自定义;8种分区器(这里只给出6种,剩下的两种比较简单,有兴趣的读者可以自行阅读)
8种分区器

五种分区类型
shuffle
Random
类型转换:DataStream → DataStream
作用:将数据随机的分配到下游算子的并行任务中去。
实现原理:底层创建ShufflePartitioner对象,该对象继承了StreamPartitioner。具体逻辑如下:
//根据并行度个数随机分配
public int selectChannel(SerializationDelegate<StreamRecord<T>> record) {
return random.nextInt(numberOfChannels);
}
操作案例:
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//非并行source
DataStreamSource<String> socketTextStream = env.socketTextStream("localhost", 8888);
//获取读取source时的并行度为1
int sourceParallelism = socketTextStream.getParallelism();
System.out.println("读取socket source并行度:" + sourceParallelism);
SingleOutputStreamOperator<String> mapped = socketTextStream.map(new RichMapFunction<String, String>() {
@Override
public String map(String value) throws Exception {
int index = getRuntimeContext().getIndexOfThisSubtask();
return index + "-->" + value;
}
}).setParallelism(2);
//获取map之后的并行度,这里得到手动设置的2
int mappedParallelism = mapped.getParallelism();
System.out.println("经过map之后的并行度:" + mappedParallelism);
DataStream<String> shuffle = mapped.shuffle();
//获取shuffle之后的并行度,这里的值和系统核数保持一致
int shuffleParallelism = shuffle.getParallelism();
System.out.println("经过shuffle之后的并行度:" + shuffleParallelism);
shuffle.addSink(new RichSinkFunction<String>() {
@Override
public void invoke(String value, Context context) throws Exception {
System.out.println(getRuntimeContext().getIndexOfThisSubtask() + "--->" + value);
}
});
env.execute();
轮询
Round-Robin
类型转换:DataStream → DataStream
作用:使用Round-Robin负载均衡算法将输入流平均分配到随后的并行运行的任务中去
实现原理:即调用rebalance算子,该算子底层由RebalancePartitioner类实现具体的分配逻辑,该类同样继承自StreamPartitioner,具体逻辑如下:
//这里真正实现轮询
@Override
public int selectChannel(SerializationDelegate<StreamRecord<T>> record) {
nextChannelToSendTo = (nextChannelToSendTo + 1) % numberOfChannels;
return nextChannelToSendTo;
}
操作案例:
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> socketTextStream = env.socketTextStream("localhost", 8888);
socketTextStream.map(new RichMapFunction<String, String>() {
@Override
public String map(String value) throws Exception {
int indexOfThisSubtask = getRuntimeContext().getIndexOfThisSubtask();
return indexOfThisSubtask + "-->map后-->" + value;
}
})
.rebalance()
.addSink(new RichSinkFunction<String>() {
@Override
public void invoke(String value, Context context) throws Exception {
int index = getRuntimeContext().getIndexOfThisSubtask();
System.out.println(value + "--->rebalance--->" + index);
}
});
env.execute();
//最后结果
3-->map后-->spark--->rebalance--->1
0-->map后-->hadoop--->rebalance--->2
1-->map后-->flink--->rebalance--->3
2-->map后-->java--->rebalance--->0
3-->map后-->es--->rebalance--->2
0-->map后-->good--->rebalance--->3
1-->map后-->yes--->rebalance--->0
2-->map后-->are--->rebalance--->1
Rescale
类型转换:DataStream → DataStream
作用:使用的也是round-robin算法,但只会将数据发送到接下来的并行运行的任务中的一部分任务中。本质上,当发送者任务数量和接收者任务数量不一样时,rescale分区策略提供了一种轻量级的负载均衡策略。如果接收者任务的数量是发送者任务的数量的倍数时,rescale操作将会效率更高
实现原理:调用rescale算子,底层由RescalePartitioner分区器实现,该分区器继承自StreamPartitioner,具体处理逻辑如下:
@Override
public int selectChannel(SerializationDelegate<StreamRecord<T>> record) {
if (++nextChannelToSendTo >= numberOfChannels) {
nextChannelToSendTo = 0;
}
return nextChannelToSendTo;
}
操作案例:
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> socketTextStream = env.socketTextStream("localhost", 8888);
socketTextStream.map(new RichMapFunction<String, String>() {
@Override
public String map(String value) throws Exception {
int indexOfThisSubtask = getRuntimeContext().getIndexOfThisSubtask();
return indexOfThisSubtask + "-->map后-->" + value;
}
})
.rescale()
.addSink(new RichSinkFunction<String>() {
@Override
public void invoke(String value, Context context) throws Exception {
int index = getRuntimeContext().getIndexOfThisSubtask();
System.out.println(value + "--->rescale--->" + index);
}
});
env.execute();
rebalance()和rescale()的根本区别在于任务之间连接的机制不同。rebalance()将会针对所有发送者任务和所有接收者任务之间建立通信通道,而rescale()仅仅针对每一个任务和下游算子的一部分子并行任务之间建立通信通道。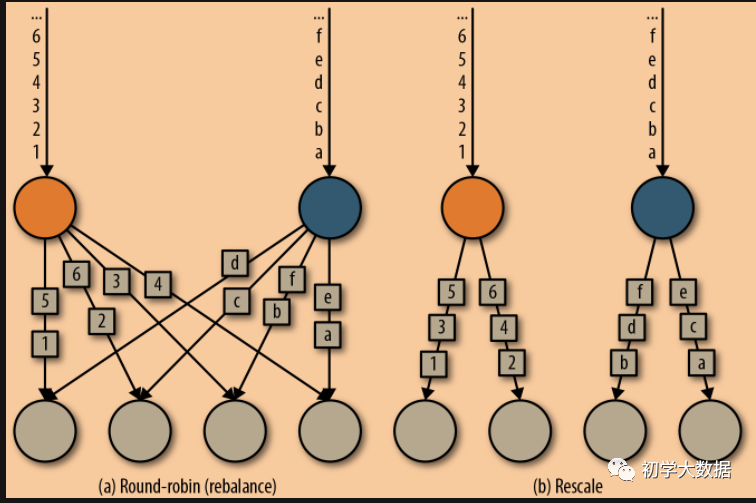 如上图所示,对于round-robin分区方式来说,上游两个分区可以分配的范围是下游的4个所有分区,属于真正的轮询方式,但是会有很大的网络开销。对于Rescale分区方式来说,上下游的分配方式和并行度有关,即上游的每个分区对应下游的两个分区,这种方式减少了网络IO,可以直接从本地的上游算子获取所需的数据。
如上图所示,对于round-robin分区方式来说,上游两个分区可以分配的范围是下游的4个所有分区,属于真正的轮询方式,但是会有很大的网络开销。对于Rescale分区方式来说,上下游的分配方式和并行度有关,即上游的每个分区对应下游的两个分区,这种方式减少了网络IO,可以直接从本地的上游算子获取所需的数据。
广播Broadcast
类型转换:DataStream → DataStream
作用:将输入流的所有数据复制并发送到下游算子的所有并行任务中去
实现原理:调用broadcast算子,底层由BroadcastPartitioner分区器实现,同样继承自StreamPartitioner,具体实现逻辑:
//直接被所有的channel进行处理了,所以不需要在该方法中实现分区逻辑
@Override
public int selectChannel(SerializationDelegate<StreamRecord<T>> record) {
throw new UnsupportedOperationException("Broadcast partitioner does not support select channels.");
}
操作案例:
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> socketTextStream = env.socketTextStream("localhost", 8888);
socketTextStream.map(new RichMapFunction<String, String>() {
@Override
public String map(String value) throws Exception {
int index = getRuntimeContext().getIndexOfThisSubtask();
return index+"-->"+value;
}
})
.setParallelism(2)
.broadcast()
.addSink(new RichSinkFunction<String>() {
@Override
public void invoke(String value, Context context) throws Exception {
System.out.println(value+"-->"+getRuntimeContext().getIndexOfThisSubtask());
}
});
env.execute();
//输入
java
spark
hadoop
//最终结果
1-->java-->1
1-->java-->3
1-->java-->2
1-->java-->0
0-->spark-->0
0-->spark-->2
0-->spark-->1
0-->spark-->3
1-->hadoop-->2
1-->hadoop-->0
1-->hadoop-->3
1-->hadoop-->1
Global
类型转换:DataStream → DataStream
作用:将所有的输入流数据都发送到下游算子的第一个并行任务中去。这个操作需要很谨慎,因为将所有数据发送到同一个task,将会对应用程序造成很大的压力
实现原理:调用global算子,由GlobalPartitioner分区器实现,同样继承自StreamPartitioner类,具体分区逻辑如下:
//即直接分到第一个task中
@Override
public int selectChannel(SerializationDelegate<StreamRecord<T>> record) {
return 0;
}
操作案例:
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> socketTextStream = env.socketTextStream("localhost", 8888);
socketTextStream.map(new RichMapFunction<String, String>() {
@Override
public String map(String value) throws Exception {
int index = getRuntimeContext().getIndexOfThisSubtask();
return index+"-->"+value;
}
})
.global()
.addSink(new RichSinkFunction<String>() {
@Override
public void invoke(String value, Context context) throws Exception {
System.out.println(value+"-->"+getRuntimeContext().getIndexOfThisSubtask());
}
});
env.execute();
//输入
flink
spark
hadoop
java
es
kylin
//最终结果
0-->flink-->0
1-->spark-->0
2-->hadoop-->0
3-->java-->0
0-->es-->0
1-->kylin-->0
自定义Custom
类型转换:DataStream → DataStream
作用:使用自定义分区策略实现分区逻辑以及定义针对流的哪个字段或者key进行分区
实现原理:调用partitionCustom方法,由CustomPartitionerWrapper类进行封装自定义分区逻辑,同样也是继承自StreamPartitioner类,具体实现方式如下:
//这里的partitioner对象是由用户自定义实现的
@Override
public int selectChannel(SerializationDelegate<StreamRecord<T>> record) {
K key;
try {
key = keySelector.getKey(record.getInstance().getValue());
} catch (Exception e) {
throw new RuntimeException("Could not extract key from " + record.getInstance(), e);
}
return partitioner.partition(key, numberOfChannels);
}
操作案例:如果key为spark,则分配到第一个分区,如果key为hadoop,则分配到第二个分区,如果key为flink,则分配到第三个分区,其他则默认分配到分区0
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> socketTextStream = env.socketTextStream("localhost", 8888);
socketTextStream.map(new RichMapFunction<String, Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> map(String value) throws Exception {
int indexOfThisSubtask = getRuntimeContext().getIndexOfThisSubtask();
return Tuple2.of(value, indexOfThisSubtask);
}
}).returns(TupleTypeInfo.getBasicTupleTypeInfo(String.class,Integer.class))
.setParallelism(2)
.partitionCustom(new Partitioner<String>() {
@Override
public int partition(String key, int numPartitions) {
System.out.println("下游并行度为:" + numPartitions);
int res = 0;
if (key.equalsIgnoreCase("spark")) {
res = 1;
} else if ("hadoop".equalsIgnoreCase(key)) {
res = 2;
} else if ("flink".equalsIgnoreCase(key)) {
res = 3;
}
return res;
}
}, t -> t.f0) //按照t.f0为key进行分组
.addSink(new RichSinkFunction<Tuple2<String, Integer>>() {
@Override
public void invoke(Tuple2<String, Integer> value, Context context) throws Exception {
System.out.println(value.f0 + "--->" + getRuntimeContext().getIndexOfThisSubtask());
}
});
env.execute();
//输入
hadoop
flink
java
es
spark
kylin
hbase
//最终结果
下游并行度为:4
hadoop--->2
下游并行度为:4
flink--->3
下游并行度为:4
java--->0
下游并行度为:4
es--->0
下游并行度为:4
spark--->1
下游并行度为:4
kylin--->0
下游并行度为:4
hbase--->0
总结



















 2224
2224











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











