







1.Flink介绍
1.1 Flink简介
Apache Flink是一个面向分布式数据流处理和批量数据 处理的开源计算平台,可以对有限数据流和无限数据流进行有状态计算,即提供支持流处理和批处理两种类型的功能
1.2 Flink特点
-
批流统一
-
支持高吞吐、低延迟‘高性能的流处理
-
支持有状态计算的Exactly-Once语义
-
支持高度灵活的窗口操作,如基于事件时间,基于会话时间,基于处理时间等。
-
支持Backpressure功能的持续流模型
-
支持基于轻量级Snapshot实现的容错
-
支持迭代计算
-
支持程序自动优化:即避免特定情况下的shuffle、排序等操作,中间结果有必要缓存
1.3 Flink和其他框架的比较


在Spark生态体系中,其主要是为离线计算设计的,底层引擎都是Spark Core,而Spark Streaming只不过是一种特殊的批处理而已。
1.4 Flink组件栈
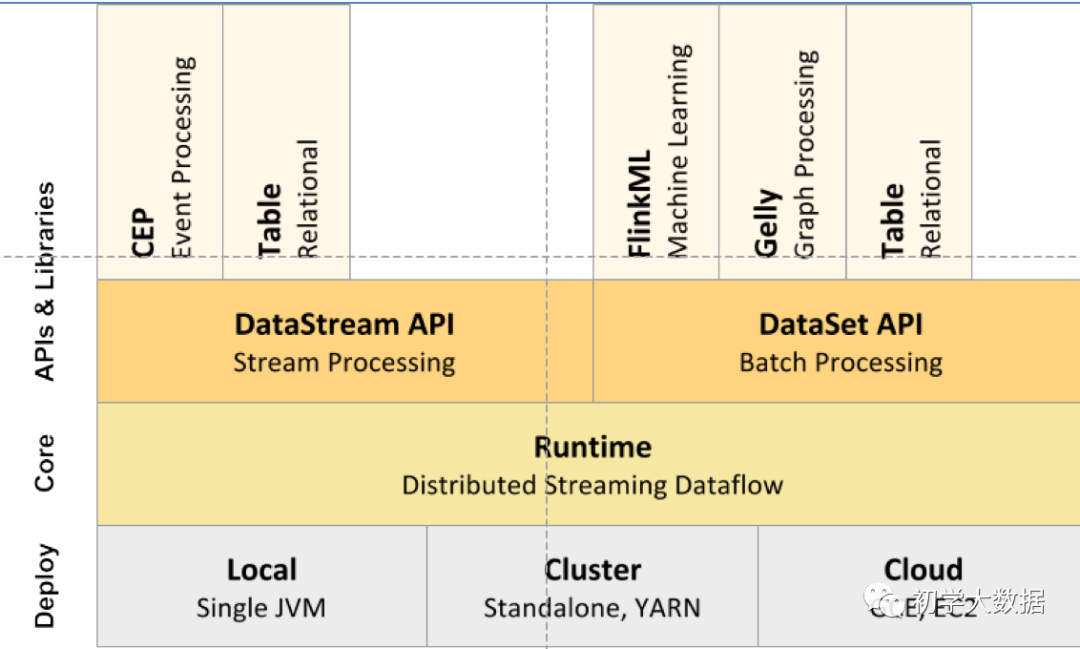
| 分层 | 功能 |
|---|---|
| Runtime层 | 支持Flink计算的全部核心实现,比如说:支持分布式Stream处理、JobGraph到ExecutionGraph的映射、调度等等,为上层API提供基础服务 |
| API层 | 主要实现了面向无界Stream的流处理和面向Batch的批处理API,其中面向流处理对应的DataStream API,面向批处理对应的DataSet API |
| Libaries层 | 面向流处理支持:CEP(复杂事件处理)、基于SQL-like的操作(基于Table的关系操作);面向批处理的支持:FlinkML(机器学习库)、Gelly(图处理) |
| Deploy层 | 主要涉及了Flink的部署模式,Flink支持多种部署模式:本地、集群(Standalone/YARN)、云(GCE/EC2) |
1.5 Flink架构体系

| 概念 | 功能 |
|---|---|
| JobManager | 也称为Master,主要用来调度task,协调checkpoit,失败时恢复等。Flink在运行时至少要有一个master运行,当配置HA模式时,有一个是leader,而其他的都是standby |
| TaskManager | 也称为Worker,用来执行一个DataFlow的task,数据缓冲和Data Streams的数据交换.Flink在运行时至少要有一个TaskManager.TaskManager通过RPC通信连接到JobManager,告知自身可用性从而获得任务分配 |
| Task | 一个阶段多个功能相同subTask的稽核,类似于Spark的TaskSet |
| subTask | Flink最小的执行单元,是一个java类的实例,有自身的属性和方法 |
| Slot | 计算资源隔离单元,一个Slot中可以运行多个subTask,但这些subTask必须来自同一个job的不同Task的subTask |
| State | Flink任务在运行过程中计算的中间结果 |
| CheckPoint | 将中间计算结果持久化的指定存储系统的一种定期执行的机制 |
| StateBackend | 用来存储中间计算结果的存储系统,Flink支持三种StateBackend,分别是Memory,FsBackend,RocksDB |
| Operator Chain | 没有shuffle的多个算子合并在一个subTask中就形成了Operator Chain,类似于Spark中的pipeline |
1.6 Flink和Spark对比
| Spark Streaming | Flink |
|---|---|
| DStream | DataStream |
| Trasnformation | Trasnformation |
| Action | Sink |
| Task | SubTask |
| Pipeline | Oprator chains |
| DAG | DataFlow Graph |
| Master + Driver | JobManager |
| Worker + Executor | TaskManager |
2.Flink部署
2.1 Flink原生安装
# 1.下载flink安装包,下载地址:https://flink.apache.org/downloads.html
# 2.上传flink安装包到Linux服务器上
# 3.解压flink安装包
tar -xvf flink-1.11.1-bin-scala_2.12.tgz -C /bigdata/
# 4.修改conf目录下的flink-conf.yaml配置文件
# 5.指定jobmanager的地址
jobmanager.rpc.address: localhost
# 6.指定taskmanager的可用槽位的数量
taskmanager.numberOfTaskSlots: 2
# 7.修改conf目录下的workers配置文件,指定taskmanager的所在节点
localhost
# 8.执行启动脚本
bin/start-cluster.sh
# 9.执行jps查看进程
jps
# 10.访问JobManager的web管理界面,端口8081
2.2 Ambari集成Flink
-
下载Flink二进制包
wget http://www.us.apache.org/dist/flink/flink-1.7.2/flink-1.7.2-bin-hadoop27-scala_2.11.tgz -
解压缩
tar -zxvf flink-1.7.2-bin-hadoop27-scala_2.11.tgz mv flink-1.7.2-bin-hadoop27-scala_2.11 /opt/flink chown -R hdfs:hdfs /opt/flink -
环境变量配置
vi /etc/profile export FLINK_HOME=/opt/flink export PATH=$FLINK_HOME/bin:$PATH :wq source /etc/profile -
下载安装Ambari-Flink软件包
git clone https://github.com/abajwa-hw/ambari-flink-service.git mv ambari-flink-server /var/lib/ambari-server/resources/stacks/HDP/$VERSION/services/FLINK -
重启ambari-server
ambari-server restart -
安装flink

img

img
-
修改yarn参数
<property> <name>yarn.client.failover-proxy-provider</name> <value> org.apache.hadoop.yarn.client.RequestHedgingRMFailoverProxyProvider </value> </property> -
重启yarn
-
测试

flink run --jobmanager yarn-cluster \
-yn 1 \
-ytm 768 \
-yjm 768 \
/opt/flink/examples/batch/WordCount.jar \
--input hdfs://hdp1:8020/user/hdfs/demo/input/word \
--output hdfs://hdp3:8020/user/hdfs/demo/output/wc/
-
flink sql client
sql-client.sh embedded
-
错误解决
java.lang.NoClassDefFoundError: com/sun/jersey/core/util/FeaturesAndProperties 解决方案:在flink的lib包里面添加如下的两个jar包
3.Flink编程模型
3.1 Flink基础编程模型
-
Flink程序的基础构建模块是流(Streams)与转换(transformations)
-
每个数据流起始于一个或多个source,并终止于一个或多个sink
-
Source主要负责数据的读取
-
Transformation主要负责对数据的转换操作
-
Sink负责最终计算好的结果数据输出


3.2 Flink数据流编程模型
Flink提供了不同的抽象级别以开发流式或批处理应用

-
最底层提供了有状态流。它将通过过程函数(Process Function)嵌入到DataStream API中。它允许用户可以自由处理来自一个或多个流数据的事件,并使用一致、容错的状态。除此之外,用户可以注册事件时间和处理事件回调,从而程序可以实现复杂的计算。
-
DataStream/DataSet API 是Flink提供的核心API。DataSet处理有界的数据集,DataStream处理有界或无界的数据流。用户可以通过各种方法(map/flatmap/window/keyBy/sum/max/min/avg/join)等将数据进行转换/计算
-
Table API:是以表为中心的声明式SQL,其中表可能会动态变化(在表达流数据时)。Table API提供了例如select、project、join、group-by、aggregate等操作,使用起来更加简洁。
-
Flink提供了最高层级的抽象是SQL.这一层抽象在语法与表达能力上与Table API类似,但是以SQL查询表达式的形式表现程序。SQL抽象与Table API交互密切,同时SQL查询可以直接在Table API定义的表上执行
4.Flink编程入门
WordCount
“从一个Socket端口中实时的读取数据,然后实时统计相同单词出现的次数,该程序会一直运行,启动程序前先使用nc -l 8888启动一个socket用来发送数据
public class StreamingWordCount {
public static void main(String[] args) throws Exception {
//创建流式计算的ExecutionEnvironment
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//调用Source,指定Socket地址和端口
DataStream<String> lines = env.socketTextStream("localhost", 10088);
DataStream<Tuple2<String, Integer>> words = lines.
flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String line, Collector<Tuple2<String, Integer>> collector)
throws Exception {
String[] words = line.split(" ");
for (String word : words) {
collector.collect(Tuple2.of(word, 1));
}
}
});
//按照key分组并聚合
DataStream<Tuple2<String, Integer>> result = words.keyBy(0).sum(1);
//将结果打印到控制台
result.print();
//执行
env.execute("StreamingWordCount");
}
}
5.Flink提交任务方式
5.1 通过web页面提交

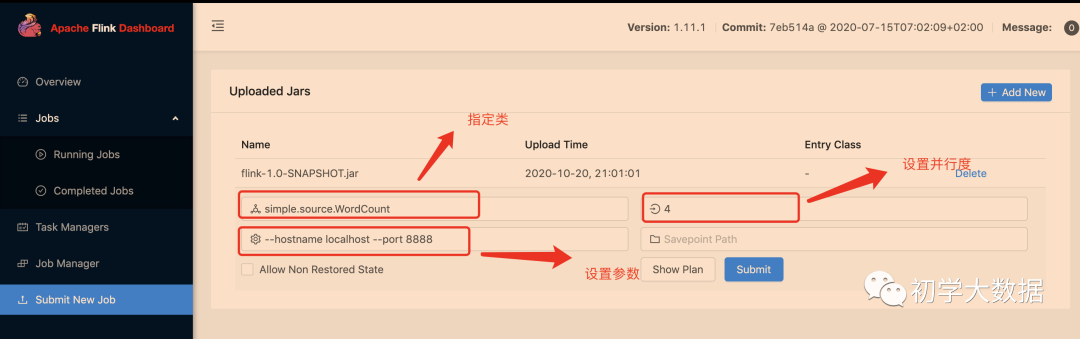
5.2 使用命令行提交
bin/flink run -m localhost:8081 -p 4 -c org.apache.flink.streaming.examples.socket.SocketWindowWordCount jar包 --hostname localhost --port 8888
参数说明:
-m:指定主机名后面的端口为JobManager的REST的端口,而不是RPC的端口,RPC通信端口是6123
-p:指定是并行度
-c:指定main方法的全类名
















 1048
1048











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











