







引入
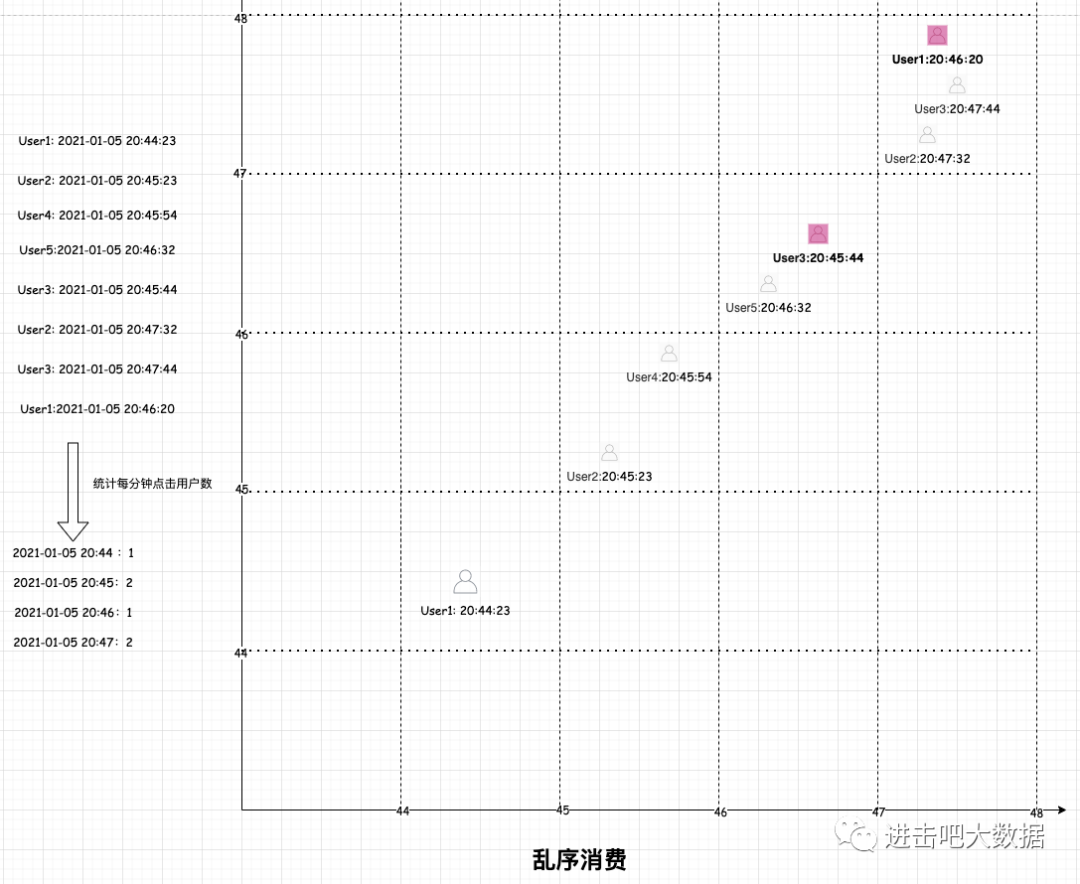
通过对上篇Flink从入门到放弃之入门篇(四)-剖析窗口生命周期的讲解,我们对flink窗口的整个生命周期有了一个大致的了解,并掌握了窗口的作用。这里给出一个常见的生产案例,如统计每分钟的点击用户数,技术实现上一般是flink对接kafka(假设这里我们保证全局有序的),窗口长度为1分钟。如下图示例:

图中的结果可以说是精准的,不过这里有一个前提条件就是消费kafka时消息是全局有序的。但是一般实际环境下很难保证全局有序,那么就会出现下图的情况:可能由于网络延迟或者系统故障等一些因素导致20:45的消息在20:46分才开始消费,部分20:46的消息在20:47分开始消费,那么最后的统计结果如下图所示,可见此时统计的结果是不正确的。
因此对于乱序消费的情况,我们应该如何处理呢?很明显,flink提供了一种称之为水印(Watermark)的机制来解决。接下来分以下几个方面来介绍:
-
Watermark如何定义的?其本质是什么?
-
Watermark生成方式策略
-
Watermark内部接口是如何实现的?
-
如何计算得出Watermark,何时会再次触发计算?
-
Watermark API使用以及源码改造
-
多流下Watermark的一些问题
-
实际场景下的问题引出
1.WaterMark定义
Watermark是Apache Flink提出的一种用来解决乱序、延迟数据等情况的解决方案,通常和窗口结合使用。例如在一个窗口内,对于延迟数据,我们不能一直无限期等待所有延迟数据到来后才触发窗口计算,因此提出了Watermark机制,由用户来决定等待延迟数据多久后触发计算。本质上来说Watermark就是单调递增的时间戳,来控制等待延迟数据的最大时长。对于watermark,可以在flink应用程序中两个地方使用:
-
直接在数据源上使用;该方式相对会比较好,因为数据源可以利用 watermark 生成逻辑中有关分片/分区(shards/partitions/splits)的信息。使用这种方式,数据源通常可以更精准地跟踪 watermark,整体 watermark 生成将更精确
-
在操作算子上使用;当无法在数据源上使用时,则可以在算子操作上进行使用
2.WaterMark生成方式
基于上面的概念定义,我们知道watermark要和窗口结合使用。为了使用EventTime语义,flink需要知道事件时间戳对应的字段,那么也就是说数据流中的每个元素都需要有一个可以分配的事件时间戳。通过上篇窗口的讲解,使用TimestampAssigner API从元素中的某个字段来提取时间戳,而且时间戳的分配和watermark的生成齐头并进的,这样就可以告诉flink应用程序处理的进度。可以通过指定WatermarkGenerator来配置watermark的生成方式,Flink内置提供了两种Watermark生成方式:
-
周期性生成(Periodic Watermark)
周期性(即达到一定的时间间隔或指定的记录数)后会触发watermark的生成
-
标记生成(Punctuated Watermark)
通过数据流中某些特殊标记事件来触发watermark的生成。这种方式下窗口的触发与时间无关,而是决定于何时收到标记事件;在某些TPS很高场景下,会生成大量的watermark,会对下游算子造成压力,因此只有当实时性要求非常高的时候才会使用该种方式
3.接口定义
看到这里,相信大家对watermark的作用有了一定的了解,那么我们可能会好奇底层是如何生成watermark的。这里会从watermark的定义,到watermark的生成以及时间的分配和watermark使用策略循序渐进的进行介绍。主要涉及到以下几个类:
-
Watermark:watermark定义类
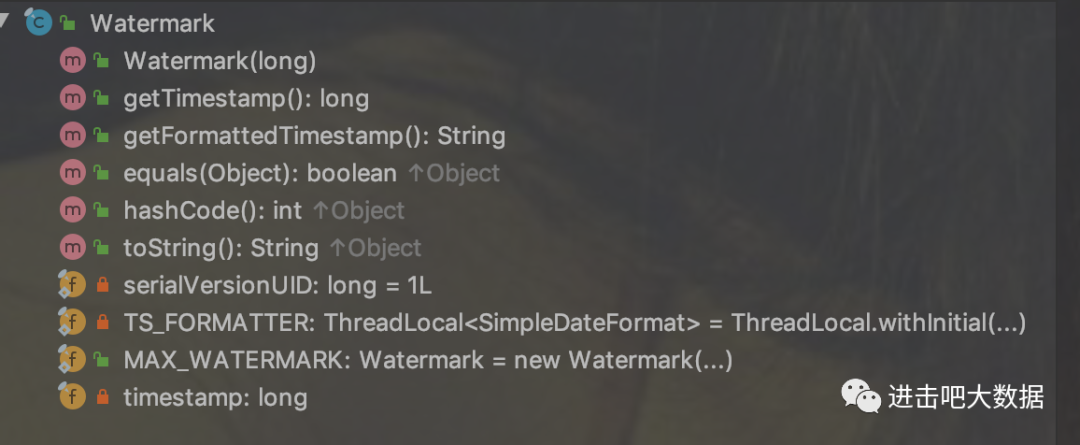
从该类中的方法和属性就可以看出watermark其底层本质就是一个时间戳
-
WatermarkGenerator:watermark生成接口,该接口定义了两个方法
/** *每来一个元素事件就会调用一次该方法 *eventTimestamp:从事件中提取出的时间戳 * 允许水印生成器检查并记住事件时间戳,或者根据事件本身发出水印 */ void onEvent(T event, long eventTimestamp, WatermarkOutput output); /** *定期调用,可能会发出或不会发出新的水印 */ void onPeriodicEmit(WatermarkOutput output); -
BoundedOutOfOrdernessWatermarks:WatermarkGenerator接口的实现类,实际生产中比较常用
public BoundedOutOfOrdernessWatermarks(Duration maxOutOfOrderness) { this.outOfOrdernessMillis = maxOutOfOrderness.toMillis(); // start so that our lowest watermark would be Long.MIN_VALUE. this.maxTimestamp = Long.MIN_VALUE + outOfOrdernessMillis + 1; } @Override public void onEvent(T event, long eventTimestamp, WatermarkOutput output) { maxTimestamp = Math.max(maxTimestamp, eventTimestamp); } @Override public void onPeriodicEmit(WatermarkOutput output) { output.emitWatermark(new Watermark(maxTimestamp - outOfOrdernessMillis - 1)); }从该类的实现可以看出水印的计算公式是:maxTimestamp - outOfOrdernessMillis - 1
-
maxTimestamp:该参数值指的是窗口内最大的事件时间戳
-
outOfOrdernessMillis:由用户指定的允许延迟时长。例如指定outOfOrdernessMillis=1000(1s),也就是说允许数据最多延迟1s的时间。
-
-
TimestampAssigner:从字面意思可以看出是时间分配器,即给每个事件分配一个时间,既可以是从事件中解析出事件时间或者是系统时间
long extractTimestamp(T element, long recordTimestamp); -
WatermarkStrategy:Flink为用户提供了一个工具类,可以同时设置TimestampAssigner和WatermarkGenerator。WatermarkGenerator类提供了很多常用的watermark策略,当然用户也可以自定义策略。
public interface WatermarkStrategy<T> extends TimestampAssignerSupplier<T>, WatermarkGeneratorSupplier<T>{ /** * 根据策略实例化一个可分配时间戳的 {@link TimestampAssigner}。 */ @Override TimestampAssigner<T> createTimestampAssigner(TimestampAssignerSupplier.Context context); /** * 根据策略实例化一个 watermark 生成器。 */ @Override WatermarkGenerator<T> createWatermarkGenerator(WatermarkGeneratorSupplier.Context context); }当然,通常是不需要实现该接口的,可以调用内部静态方法来获取一个策略;或者可以使用该工具类将自定义的TimestampAssigner和WatermarkGenerator进行绑定。
4.如何计算得出Watermark
在接口定义部分中的讲解中,已经得知WatermarkGenerator接口的实现类中在创建Watermark实例时,传入了一个构造器参数,而该参数值就是maxTimestamp - outOfOrdernessMillis - 1;由此就可知Watermark的值,那么仍然以文章开头的例子来讲解watermark是如何计算的。
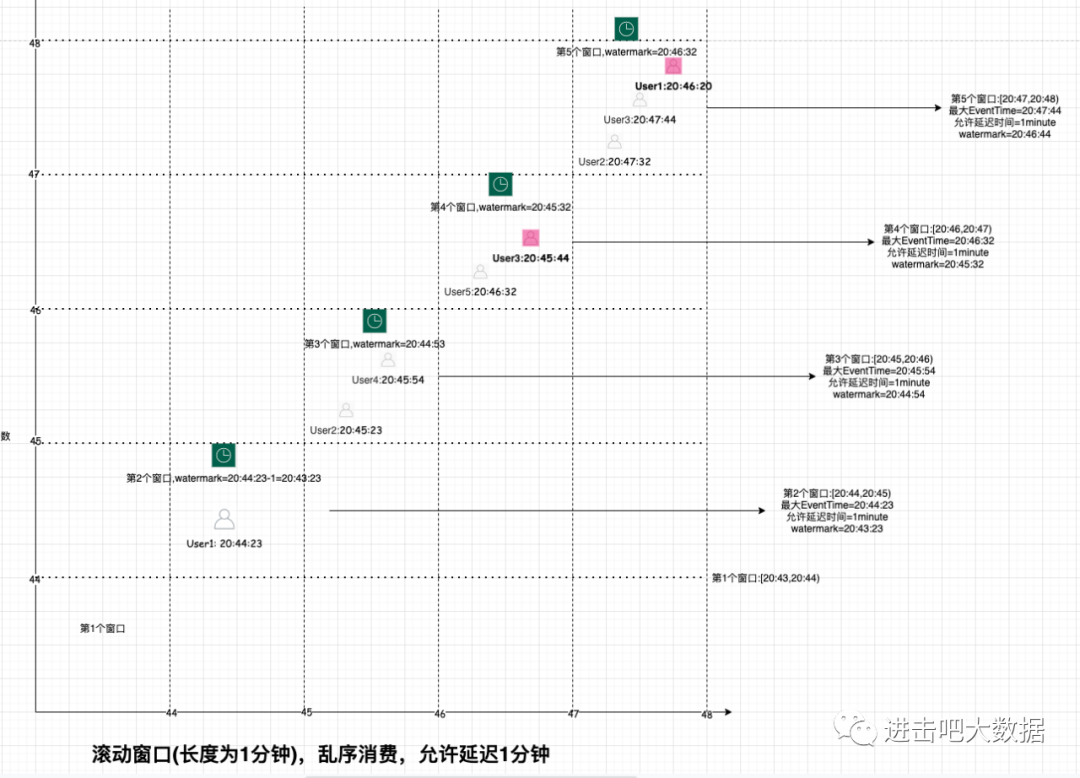
我们这里设置outOfOrdernessMills的值为1分钟,也就是说我们允许数据延迟1分钟,否则的话则丢弃或者进行其他的处理。在上篇文章中介绍到了窗口的触发机制(以滚动窗口+事件时间触发机制来说明):当流元素的最大事件时间大于当前窗口的结束时间,就会触发窗口计算。如开头所讲,如果出现数据延迟,那么就会造成延迟的数据无法被计算的情况;既然有了水印机制可以解决这一问题,当有数据延迟时,窗口又是如何被触发的呢?这里我们结合上图来梳理一下:
| 用户ID | 点击时间 | 到达窗口 | 实际落入窗口 | 当前窗口结束时间 | 水印时间 | 触发计算 | 计算结果 |
|---|---|---|---|---|---|---|---|
| User1 | 20:44:23 | 第2个窗口 | 第2个窗口 | [20:44,20:45) | 20:43:23 | 否 | 否 |
| User2 | 20:45:23 | 第3个窗口 | 第3个窗口 | [20:45,20:46) | 20:44:23 | 否 | 否 |
| User4 | 20:45:54 | 第3个窗口 | 第3个窗口 | [20:45,20:46) | 20:44:54 | 否 | 否 |
| User5 | 20:46:32 | 第4个窗口 | 第4个窗口 | [20:46,20:47) | 20:45:32 | 触发第二个窗口 | 窗口2:[User1] |
| User3 | 20:45:44 | 第4个窗口 | 第3个窗口 | [20:46,20:47) | 20:45:32 | 否 | 窗口2:[User1] |
| User2 | 20:47:32 | 第5个窗口 | 第5个窗口 | [20:47,20:48) | 20:46:32 | 触发第三个窗口 | 窗口2:[User1] 窗口3:[User2,User4,User3] |
| User3 | 20:47:44 | 第5个窗口 | 第5个窗口 | [20:47,20:48) | 20:46:44 | 否 | 窗口2:[User1] 窗口3:[User2,User4,User3] |
| User1 | 20:46:20 | 第5个窗口 | 第4个窗口 | [20:47,20:48) | 20:46:44 | 否 | 窗口2:[User1] 窗口3:[User2,User4,User3] |
| User5 | 20:44:54 | 第5个窗口 | 第2个窗口 | [20:44,20:45) | 直接丢弃 | 直接丢弃 |
从该执行表格中可以发现以下规律:
-
水印生成时间是单调递增的
-
当水印时间大于窗口结束时间则会触发窗口计算
-
如果延迟数据大于指定延迟时间后,则不会被计算到窗口内
5.Watermark使用
简单API(结合源码改造)
这里主要给出watermark的简单api使用demo,以及内置的两种watermark生成策略和自定义生成策略。
关于watermark简单的API使用,结合文章中给出的样例,笔者结合源码进行了部分重构。这里给出主要的代码(TumblingWatermarkMain.java)
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
env.setParallelism(1);
DataStreamSource<String> socketTextStream = env.socketTextStream("localhost", 8888);
socketTextStream.assignTimestampsAndWatermarks(new BoundedOutOfOrdernessTimestampExtractor<String>(duration) {
@Override
public long extractTimestamp(String element) {
long time = System.currentTimeMillis();
try {
time = simpleDateFormat.parse(element.split(SEPATOR)[1]).getTime();
} catch (ParseException e) {
e.printStackTrace();
}
return time;
}
}).map(new MapFunction<String, Tuple2<String, String>>() {
@Override
public Tuple2<String, String> map(String value) throws Exception {
System.out.println();
System.out.println("第一步:输入事件元素--->" + value);
SimpleDateFormat targetFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm");
String user = value.split(SEPATOR)[0];
String dateTime = value.split(SEPATOR)[1];
return Tuple2.of(targetFormat.format(simpleDateFormat.parse(dateTime)), user);
}
}).keyBy(t -> t.f0)
.window(TumblingEventTimeWindows.of(Time.minutes(1L)))
.trigger(EventTimeTriggerOverload.create())
.aggregate(new DistinctAggreFunction()).print("计算结果值为--->");
env.execute();
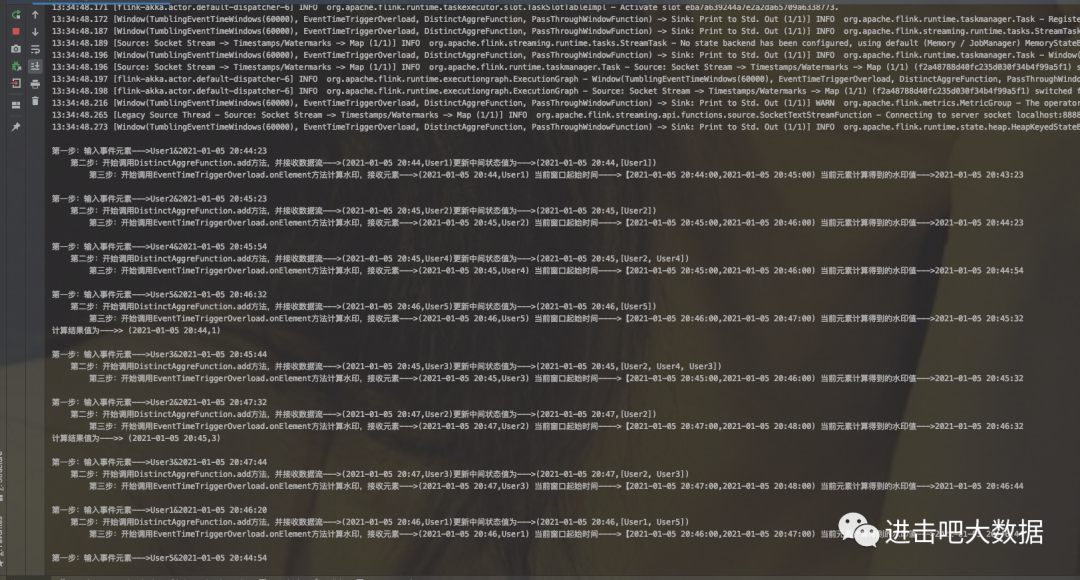
最终结果:
其中截图中的水印值结果是笔者在自定义触发器中结合watermark生成机制来改造实现的。主要是为了方便读者理解水印的机制
自定义生成策略
刚才简单的API案例中已经涉及到Period生成策略,标记策略比较简单,笔者这里不再给出。接下来使用自定义生成策略(同样以上述例子来实现)。具体代码地址:TumblingWatermarkMain.java
//这里给出核心代码
WatermarkStrategy<String> ws = ((ctx) -> new CustomWatermarkGenerator());
socketTextStream.assignTimestampsAndWatermarks(ws.withTimestampAssigner(new CustomTimestampAssignerWithSource()))
.map((MapFunction<String, Tuple2<Long, String>>) value -> getLongStringTuple2(value, simpleDateFormat, SEPATOR)
).returns(TupleTypeInfo.getBasicTupleTypeInfo(Long.class, String.class))
.keyBy(t -> {
return targetFormat.format(new Date(t.f0));
})
.window(TumblingEventTimeWindows.of(Time.minutes(1L)))
.trigger(EventTimeTriggerOverload.create())
.aggregate(new DistinctAggreFunctionStrategy()).print("计算结果值为--->");
最后的结果和简单API下的结果一致。

6.多流下的Watermark处理
细心的读者会发现在示例代码中总会有一个并行度的设置env.setParallelism(1),增加该设置主要是为了方便理解watermark的机制。当然在实际场景中,特别是对接kafka的时候,大部分情况下是不会设置并行度为1的,否则会出现大量的延迟。我们仍然以开头的案例来讲解并行度对watermark的影响(注意:在demo代码里使用的是socketStream来模拟KafkaSourceStream。假设kafka topic有2个分区,接下来分别对比一下并行度=1和并行度=2的区别
第一种情况:当并行度=1时,见下图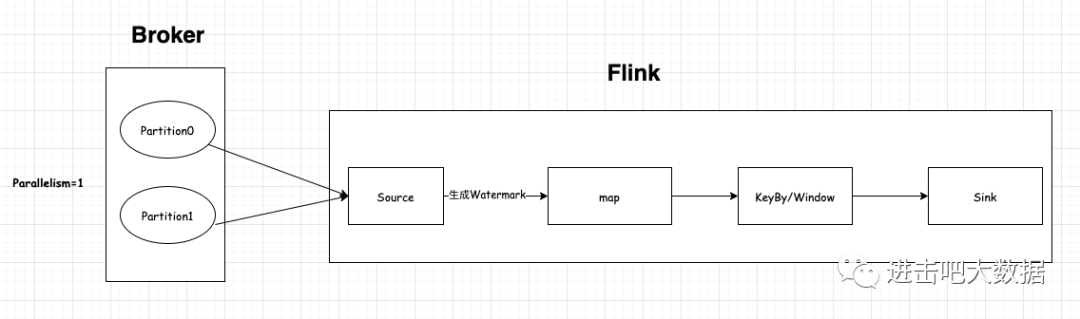
可以发现2个分区的数据全部被一个source消费,那么这个时候也只会生成一个watermark,同时其他的算子也将会以一个并行度来计算。(这种情况也就是我们开头所讲的例子)
第二种情况:当并行度=2时,见下图:
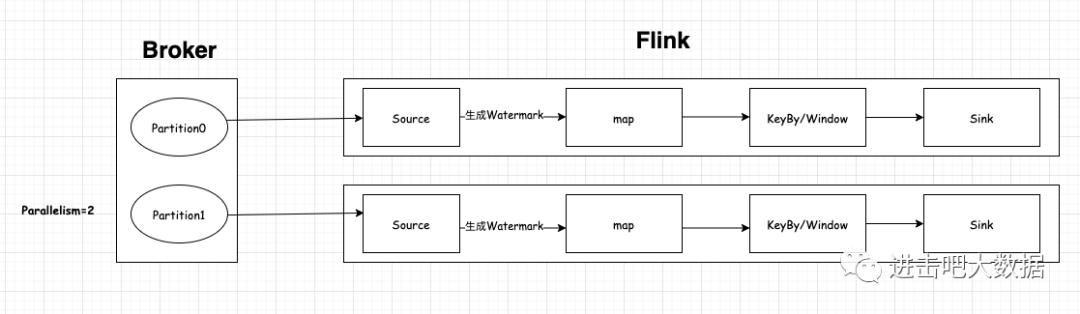
可以发现每个source都分别消费一个partition,而且每个source都会生成一个watermark。这个时候就产生了一个问题:kafka topic的分区只能保证分区有序,但不能保证全局有序,如果说每个source都产生了一个watermark,那么统计出的结果就会有问题,而且也违背了我们发现的规律(即watermark单调递增)。
当然,如何让watermark单调递增的问题很好解决,只要保证全局有序就可以,这样就和单流下的watermark处理机制一样了。对应的在Flink中的抽象实现封装在org.apache.flink.streaming.api.operators.AbstractStreamOperator中。这里以TwoInputStreamOperator为例,即有两个Input Source
public void processWatermark(Watermark mark) throws Exception {
if (timeServiceManager != null) {
timeServiceManager.advanceWatermark(mark);
}
output.emitWatermark(mark);
}
//将source1计算生成的watermark和全局最小的watermark进行比较
public void processWatermark1(Watermark mark) throws Exception {
input1Watermark = mark.getTimestamp();
long newMin = Math.min(input1Watermark, input2Watermark);
if (newMin > combinedWatermark) {
combinedWatermark = newMin;
processWatermark(new Watermark(combinedWatermark));
}
}
//将source2计算生成的watermark和全局最小的watermark进行比较
public void processWatermark2(Watermark mark) throws Exception {
input2Watermark = mark.getTimestamp();
long newMin = Math.min(input1Watermark, input2Watermark);
if (newMin > combinedWatermark) {
combinedWatermark = newMin;
processWatermark(new Watermark(combinedWatermark));
}
}
从源码中可以看出,Flink是取多个流中最小的watermark作为全局的watermark。虽然这样能够保证全局有序且单调递增,但也会有一个实际的问题,比如下图特殊的场景:当source0消费partition0得到的watermark为2021-01-15 00:00,source1消费partition1得到的watermark为2021-01-15 01:00,那么最终得到的全局watermark为2021-01-15 00:00,此时数据流正常计算触发。但当业务数据出现异常时或者key分区不均匀时,出现了partition0分区不再接收数据的情况,而partition1一直接收最新的数据(即事件时间都是大于2021-01-15 01:00)。试想:之后计算得到的watermark值会一直为2021-01-15 00:00,那么就无法触发窗口计算,随着时间推移,Flink处理的数据越来越多,而窗口资源一直未被释放,最后可能会导致程序down掉。
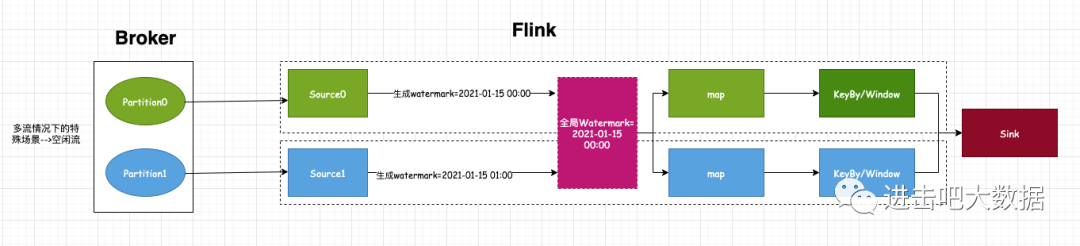
对于这种特殊的场景,也就是所谓的多流处理中的空闲流问题。对于此类问题,Flink提供了一个使用很简单的方案:即用户可以设置一定的超时时间,当全局watermark所在的source流在一定时间内没有数据的话,那么flink则会丢弃该watermark。应用到本文的例子中,也就是说当source0超过一定时间没有消费到数据的话,那么全局watermark对应2021-01-15 00:00这个值就无效了,之后就会按照正常的计算流程进行处理,也就不会影响水印的处理进度。具体使用方式如下:
//在watermark策略上设置空闲超时时间即可
WatermarkStrategy.<Tuple2<Long, String>>forBoundedOutOfOrderness(Duration.ofMinutes(1L))
.withTimestampAssigner(new CustomSerializableTimestampAssignerWithNoSource())
.withIdleness(Duration.ofMinutes(1L))
7.思考?
到这里已经基本上把Flink Watermark的核心知识点介绍完了,那么接下来有两个问题需要读者们一起来思考:
1.对于超出延迟范围的内的数据如何处理?(默认情况下是直接丢弃掉)
2.Watermark容错处理(实际场景中消费kafka的案例比较多,那么当程序挂掉重启之后watermark会恢复吗?如果不能恢复应该如何解决?)
本文涉及到demo代码见:https://github.com/lcp5674/learn-flink-demo/tree/main/flink/src/main/java/simple/window/watermark
















 503
503











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











