






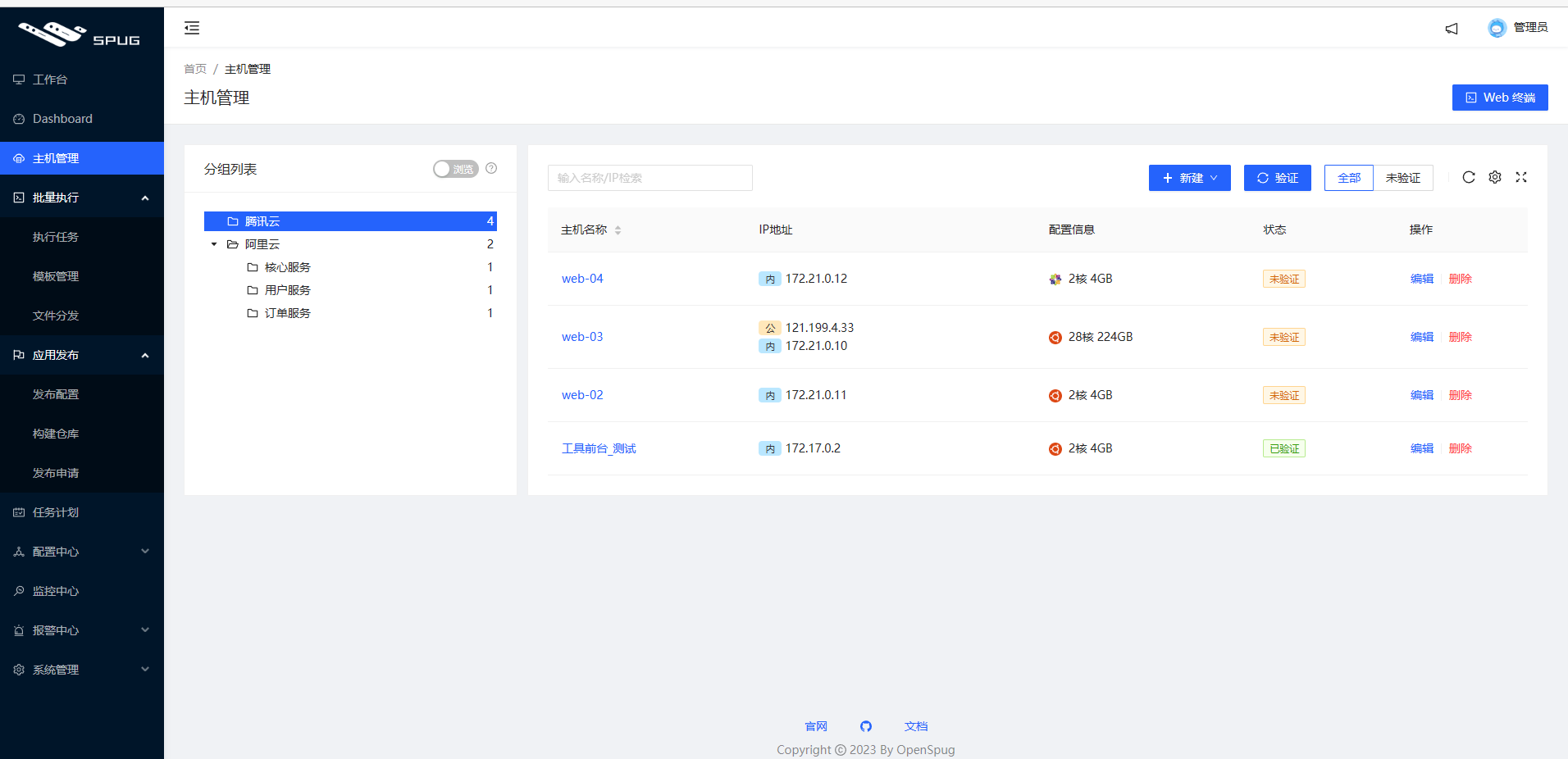
一、Spug自动化运维平台
Spug是面向中小型企业设计的轻量级无Agent的自动化运维平台,整合了主机管理、主机批量执行、主机在线终端、应用发布部署、在线任务计划、配置中心、监控、报警等一系列功能。美观的后台界面,支持批量执行在线终端文件管理、任务计划发布部署等,支持docker一键安装,前后端代码开源,是一个学习使用不错的选择。
二、KeymouseGo 鼠标键Go
该软件通过Python语言编写,记录用户的鼠标键盘操作,通过触发按钮自动执行之前记录的操作,可设定执行的次数,可以理解为精简绿色版的按键精灵。在进行某些操作简单、单调重复的工作时,使用本软件就可以很省力了。自己只要做一遍,然后接下来就让电脑来做。

三、Wagtail 开源内容管理系统
Wagtail 是一个基于 Python的Django框架构建的开源内容管理系统,具有强大的社区和商业支持。它专注于用户体验,并为设计人员和开发人员提供精确的控制。拥有清爽的 UI 和简洁易用的编辑器。独特的 StreamField 技术,可以让内容排版灵活又不失结构,再加上强大的多语言系统,让它在众多开源 CMS 中脱颖而出。

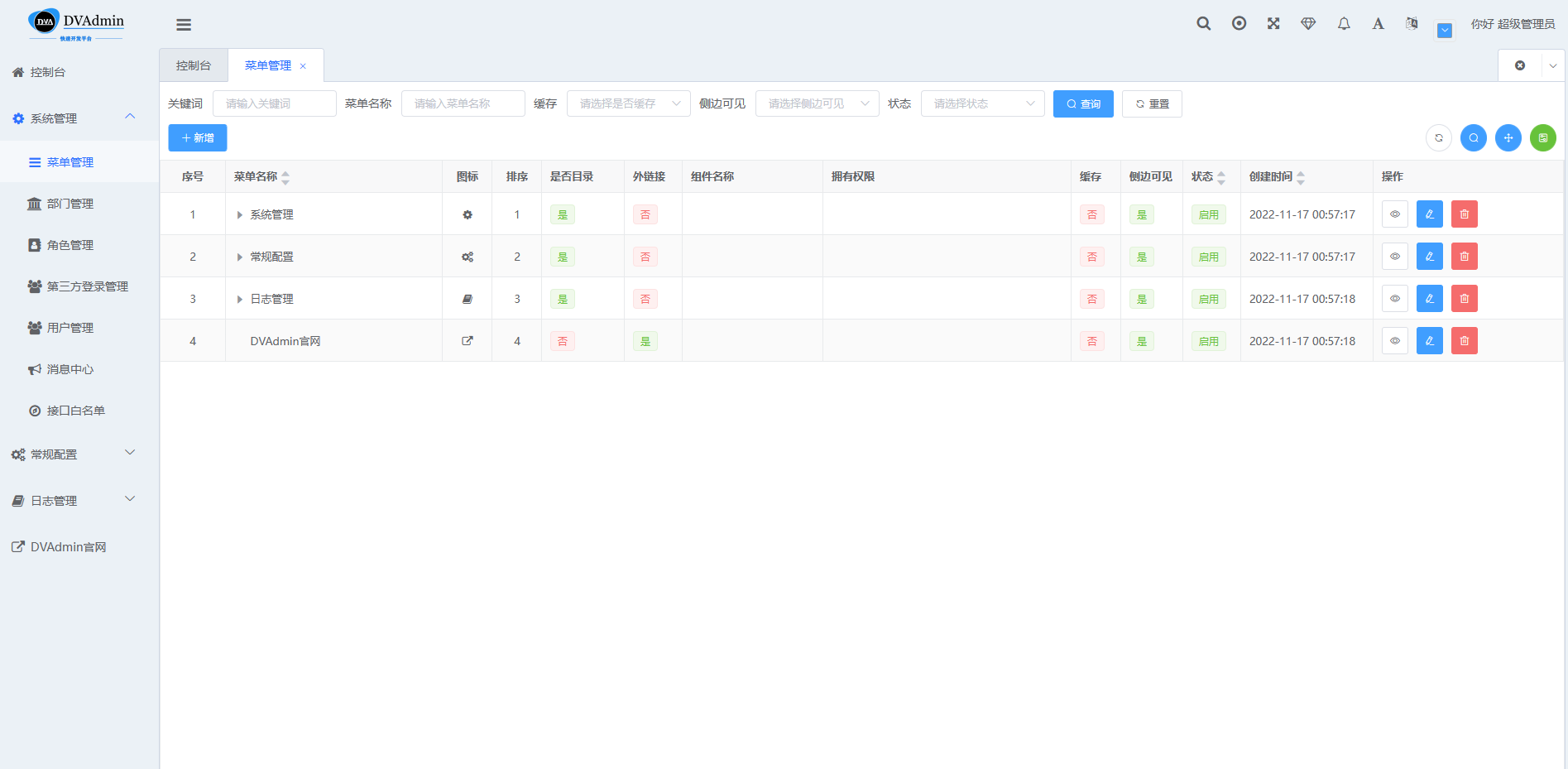
四、Django-Vue-Admin-Pro全栈后台管理系统
django-vue-admin-Pro 是一套全部开源的快速开发平台,Python全站管理系统,丰富的插件市场,可以在线安装插件,多语言支持,完美兼容多租户模式,前后端轻量级封装,数据库自动化增删改查,内置多个基础功能,让web开发得心应手,是Python全开发不二之选。















 494
494











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









