







Original address, http://www.mysqltutorial.org/mysql-collation/
Introduction to MySQL collation
A MySQL collation is a set of rules used to compare characters in a particular character set. Each character set in MySQL can have more than one collation, and has, at least, one default collation. Two character sets cannot have the same collation.
MySQL provides you with the SHOW CHARACTER SET statement that allows you to get the default collations of character sets as follows:
| 1 | SHOW CHARACTER SET; |
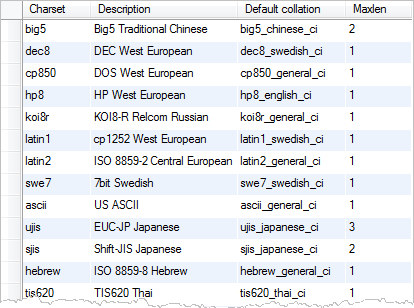
The values of the default collation column specify the default collations for the character sets.
By convention, a collation for a character set begins with the character set name and ends with _ci (case insensitive) _cs (case sensitive) or _bin (binary).
To get all collations for a given character set, you use the SHOW COLLATION statement as follows:
| 1 | SHOW COLLATION LIKE 'character_set_name%'; |
For example, to get all collations for the latin1 character set, you use the following statement:
| 1 | SHOW COLLATION LIKE 'latin1%'; |
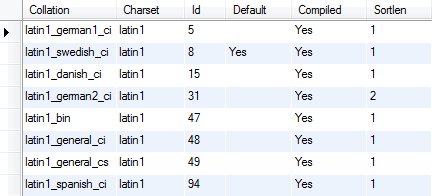
MySQL Collations for latin1 Character Set
As mentioned above, each character set has at a default collation e.g., latin1_swedish_ci is the default collation for the latin1 character set.
Setting character sets and collations
MySQL allows you to specify character sets and collations at four levels: server, database, table, and column.
Setting character sets and collations at Server Level
Notice MySQL uses latin1 as the default character set, therefore, its default collation is latin1_swedish_ci. You can change these settings at server startup.
If you specify only a character set at server startup, MySQL will use the default collation of the character set. If you specify both a character set and a collation explicitly, MySQL will use the character set and collation for all databases created in the database server.
The following statement sets the utf8 character set and utf8_unicode_cs collation for the server via command line:
| 1 | >mysqld --character-set-server=utf8 --collation-server=utf8_unicode_ci |
Setting character sets and collations at the database level
When you create a database, if you do not specify its character set and collation, MySQL will use the default character set and collation of the server for the database.
You can override the default settings at the database level by using CREATE DATABASE or ALTER DATABASE statement as follows:
| 1 2 3 | CREATE DATABASE database_name CHARACTER SET character_set_name; COLLATE collation_name |
| 1 2 3 | ALTER DATABASE database_name CHARACTER SET character_set_name COLLATE collation_name; |
MySQL uses the character set and collation at the database level for all tables created within the database.
Setting character sets and collations at the table level
A database may contain tables with character sets and collations that are different from the default database’s character set and collation.
You can specify the default character set and collation for a table when you create the table by using the CREATE TABLE statement or when you alter the table’s structure by using the ALTER TABLE statement.
| 1 2 3 4 5 | CREATE TABLE table_name( ... ) CHARACTER SET character_set_name COLLATE collation_name |
| 1 2 3 4 5 | ALTER TABLE table_name( ... ) CHARACTER SET character_set_name COLLATE collation_name |
Setting character set and collation at column level
A column of type CHAR , VARCHAR or TEXT can have its own character set and collation that is different from the default character set and collation of the table.
You can specify a character set and a collation for the column in the column’s definition of either CREATE TABLE or ALTER TABLE statement as follows:
| 1 2 3 | column_name [CHAR | VARCHAR | TEXT] (length) CHARACTER SET character_set_name COLLATE collation_name |
These are the rules for setting the character set and collation:
- If you specify both a character set and a collation explicitly, the character set and collation are used.
- If you specify a character set and omit the collation, the default collation of the character set is used.
- If you specify a collation without a character set, the character set associated with the collation is used.
- If you omit both character set and collation, the default character set and collation are used.
Let’s take a look at some examples of setting the character sets and collations.
Examples of setting character sets and collations
First, we create a new database with utf8 as the character set and utf8_unicode_ci as the default collation:
| 1 2 3 | CREATE DATABASE mydbdemo CHARACTER SET utf8 COLLATE utf8_unicode_ci; |
Because we specify the character set and collation for the mydbdemo database explicitly, the mydbdemo does not take the default character set and collation at the server level.
Second, we create a new table named t1 in the mydbdemo database:
| 1 2 3 4 | USE mydbdemo; CREATE TABLE t1( c1 char(25) ); |
We did not specify the character set and collation for the t1 table; MySQL will check the database level to determine the character set and collation for the t1 table. In this case, the t1 table has utf8 as the default character set and utf8_unicode_ci as the default collation.
Third, for the t1 table, we change its character set to latin1 and its collation to latin1_german1_ci:
| 1 2 3 | ALTER TABLE t1 CHARACTER SET latin1 COLLATE latin1_german1_ci; |
The c1 column in the t1 table has latin1 as the character set and latin1_german1_ci as the collation.
Fourth, let’s change the character set of the c1 column to latin1 :
| 1 2 3 | ALTER TABLE t2 MODIFY c1 VARCHAR(25) CHARACTER SET latin1; |
Now, the c1 column has the latin1 character set, but what about its collation? Is it inheriting the latin1_german1_ci collation from the table’s collation? No, because the default collation of the latin1character set is latin1_swedish_ci , the c1 column has the latin1_swedish_ci collation.
In this tutorial, you have learned about MySQL collation and how to specify character sets and collations for MySQL server, databases, tables and columns.
Reference
- http://dev.mysql.com/doc/refman/5.7/en/charset.html – MySQL character set support
- http://collation-charts.org/mysql60/ – MySQL collation charts















 1130
1130

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









