






深度剖析最新研究,揭示当前最先进的AI无法理解并解决数学问题。

使用DALL-E 3生成
我们目前正处于一个AI泡沫中。
围绕当前AI能力的炒作很多。
有人说它会使得像软件工程和医学这样高度专业的工作变得过时。
其他人警告说,未来几年内将出现AI末日。
这些说法离事实相差甚远。
是的,AI可能有一天会取代我们的工作,但当前的AI架构无法做到这一点,并且已经被过度炒作。
基于Transformer架构的大型语言模型(LLMs)是出色的下一个词预测器和语言生成器,但有大量证据表明它们无法可靠地解决数学问题。
它们可以可靠地伪造这样做,但缺乏真正的逻辑推理能力。
这里有一个故事,我们讨论了当前AI在数学任务中的表现、原因,并揭穿了大型科技公司卖给我们的谎言。
琳达问题变成鲍勃问题时,LLMs就崩溃了
你听说过经典的琳达问题吗?
这是一个来自认知心理学的例子,展示了合取谬误。
简单来说,这种谬误发生在人们错误地判断两个事件一起发生(或合取)的可能性比任何一个事件单独发生的可能性更大,而从数学上讲并非如此。
问题是这样的:
琳达31岁,单身,直言不讳,非常聪明。
她主修哲学。
作为一名学生,她深切关注歧视和社会正义问题,并参加了反核示威。
哪个更有可能?
A. 琳达是一名银行出纳员。
B. 琳达是一名银行出纳员,并且活跃在女权运动中
答案是什么?
陈述A必须比陈述B更有可能,因为从数学上讲,合取的概率P(A和B)总是小于或等于任何一个单独事件的概率P(A)或P(B)。
看看GPT-4在回答这个问题时发生了什么。
GPT-4的逻辑推理能力很大程度上是脆弱的,并且基于其初始标记(来自一个名为“偷看标记偏见:大型语言模型还不是真正的推理者”的ArXiv研究论文的图片)
当以单次提示的方式提出时,GPT-4正确识别了合取谬误并正确回答问题。
但将琳达的名字改为鲍勃时,它就困惑了,其逻辑推理崩溃了。
(我在GPT-4o上测试了相同的问题,是的,它回答错误。)
这篇ArXiv论文的研究人员生成了多个调整过的问题,并在这些问题中改变了名字/上下文,同时保持了底层逻辑不变,然后他们使用McNemar测试评估模型在原始和扰动任务上的表现。(来源)
他们一致地(具有统计学意义)发现LLMs有巨大的标记偏见。
这意味着LLMs在解决问题时主要依赖输入文本中的特定模式或标记,而不是真正理解它们。
再看另一个例子。
“二十五匹马”问题是这样的:
有25匹马。
这些马只能五匹一组比赛,你不能测量它们实际的速度;
你只能测量它们在比赛中的相对排名。
挑战是找出找到前三匹马所需的最少比赛次数。
将这个问题改为**“三十六只兔子”问题**再次困惑了GPT-4和Claude 3 Opus,它们错误地解决了这个问题。
(来源)
苹果用GSM-Symbolic打破僵局
GSM8K(Grade School Math 8K)基准测试通常用来评估LLMs的数学推理能力。
这个数据集包含了8.5千个高质量的、语言多样的小学数学文字问题。
这里的问题对人类来说相对简单,只需要知道四种基本的算术运算(+ − × ÷)就能得出最终答案。
这些问题需要多步骤推理,但一个聪明的中学生仍然应该能够解决这个数据集中的每个问题。
看一个例子:
{
‘question’: ‘Natalia sold clips to 48 of her friends in April, and then she sold half as many clips in May.
How many clips did Natalia sell altogether in April and May?’,
‘answer’: ‘Natalia sold 48/2 = <<48/2=24>>24 clips in May.
\nNatalia sold 48+24 = <<48+24=72>>
72 clips altogether in April and May.
\n#### 72’,
}
所有最先进的LLMs(包括Claude、GPT-4o、o1和Gemini)在GSM8K上表现异常出色,但苹果研究人员质疑了这些指标。
为了测试他们的假设,他们使用模板调整了这个基准测试,并基于这些生成了问题的变化。
他们的修改包括改变名字/数值,并在GSM8K的原始问题中添加或删除从句。
他们称他们的新基准测试为——GSM Symbolic。

用于在GSM8K中创建不同问题变体的模板(图片来自名为“GSM-Symbolic: Understanding the Limitations of Mathematical Reasoning in Large Language Models”的ArXiv研究论文)
他们使用这个修改后的基准测试对LLM进行评估,揭示了一些引人注目的发现。
大多数LLMs在GSM-Symbolic上的平均表现低于GSM8K(下图中的虚线所示)。
此外,LLMs对使用GSM-Symbolic模板生成的问题的响应准确性存在显著差异。
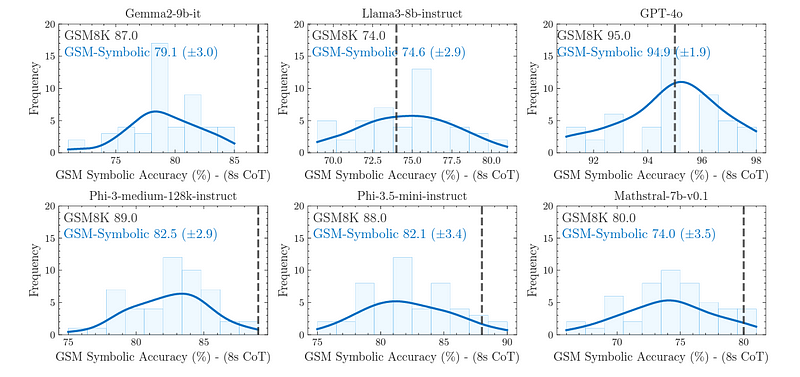
不同LLMs在GSM-Symbolic上8次推理(CoT)准确性的分布,与GSM8K相比(来源)
对于像Mistral-7b-it和Gemma-2b-it这样的模型,与GPT-4o相比,性能下降很大。
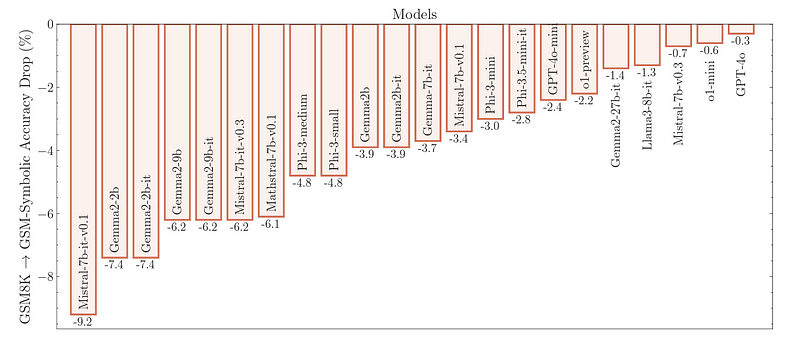
与GSM8K相比,GSM-Symbolic上的准确性下降(来源)
另一个有趣的发现是,LLMs在解决数学问题时,基于它们的训练数据进行模式匹配。
如下所示的图表中,当原始问题中的名称、数字或两者都改变时,LLMs的表现显著下降。
如果LLMs真的理解数学,这不应该发生。
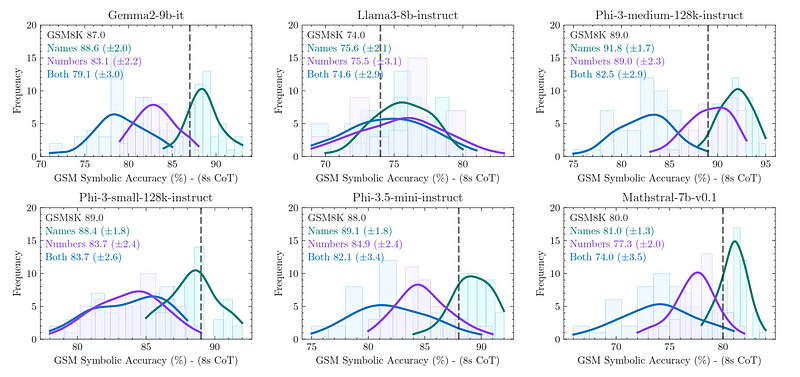
不同LLMs对名称、数字或两者都改变的准确性敏感性(来源)
研究人员通过从GSM-Symbolic生成三个不同难度级别的更多数据集,将这一评估推向深入。
如下:
- GSM-Symbolic-Minus-1 (
GSM-M1):通过从原始问题中删除一个从句 - GSM-Symbolic-Plus-1 (
GSM-P1):通过向原始问题添加一个从句 - GSM-Symbolic-Plus-2 (
GSM-P2):通过向原始问题添加两个从句

通过添加或删除问题中的从句来改变GSM-Symbolic的难度(来源)
所有LLMs的准确性下降,并且随着问题中从句数量的增加,方差增加。
令人惊讶的是,这对于OpenAI的o-1 mini,一个特别训练用于更好推理的模型,也是如此。
增加从句对不同LLMs准确性的影响(来源)
研究人员并未止步于此。他们进一步使用一个名为GSM-NoOp的进一步修改的数据集来推动这些LLMs。
GSM-NoOp是通过添加看似相关但实际上与推理和结论无关的陈述来创建问题的。

An example from GSM-NoOp (“No-Op” means that the added clauses carry no operational significance) (Source)
大多数模型未能忽略这些陈述,并盲目地将它们转化为额外的操作,犯了愚蠢的错误。
OpenAI最先进的推理模型o1-preview,在GSM-NoOp上经历了17.5%的性能下降,Phi-3-mini的下降了65%!
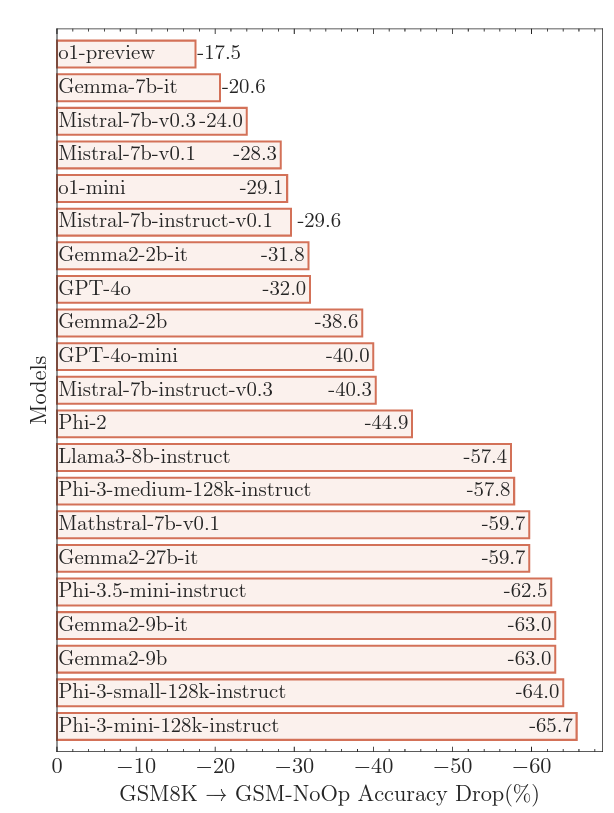
不同LLMs在GSM-NoOp上的准确性下降(来源)
下图显示了所有模型的完整结果。
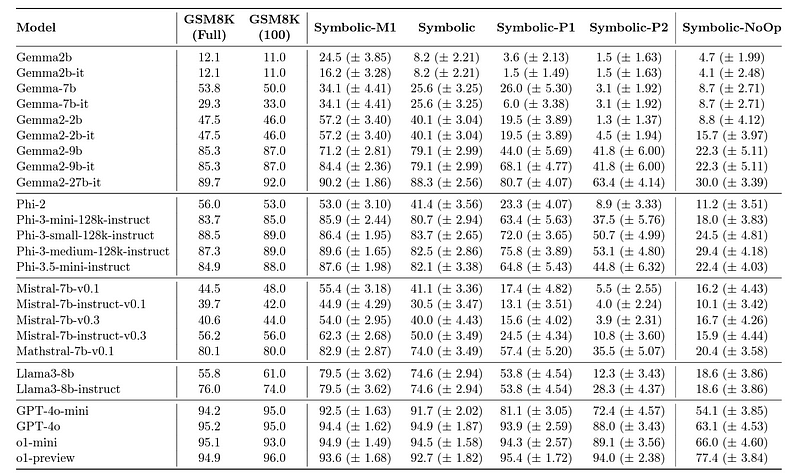
所有LLMs在GSM8K(完整测试集和测试集的100个问题的子集)和不同GSM-Symbolic变体上的8次准确性(来源)
但OpenAI肯定安全,对吧?
OpenAI最先进的推理模型o1-mini和o1-preview,在问题变得更困难时,抵制了准确性的下降。
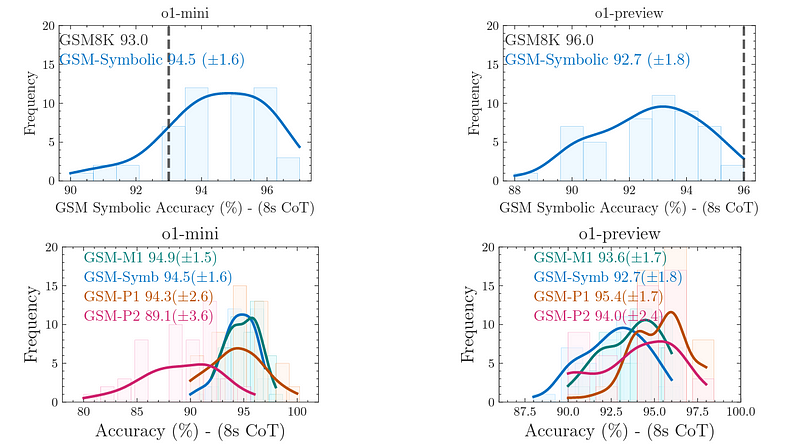
不同变体的GSM Symbolic上o1-mini和o1-preview的准确性(来源)
然而,两者在GSM-NoOp上都经历了显著的准确性下降。
这从o1-preview对下面这个简单数学问题的回应中可以看出,问题中添加了一个无关的从句。
(然而,值得一提的是,当我测试OpenAI目前最先进的推理模型o1时,它完美地解决了这个问题。)

o1-preview对GSM-Symbolic-NoOp中的一个问题的回应(来源)
LLMs是如何真正解决数学问题的?
苹果的研究显示了当前最先进的LLMs推理能力的脆弱性。
另一项来自2023年的有趣研究显示,当推理任务由计算图表示时,正确的预测比错误的预测更频繁地与LLM训练数据中的完整计算子图相关联。
这意味着LLMs仅仅是在记忆它们的训练数据集吗?
现实情况有点微妙。
最近的研究告诉我们LLMs使用“启发式方法包”或简单的规则/模式来解决数学问题,而不是依赖离散算法或仅仅记忆训练数据。
让我们了解这是如何工作的。
在基于Transformer的LLMs中,执行给定任务计算的多层感知器(MLP)层或注意力头的子集被称为电路。
当研究Llama3–8B时,在其中到后层发现了许多基于算术的电路。
还发现大多数MLP参与算术运算,而不是注意力头。
只有少数注意力头(主要在早期层)执行计算,大多数头在序列位置之间传递关于操作数和运算符的信息。
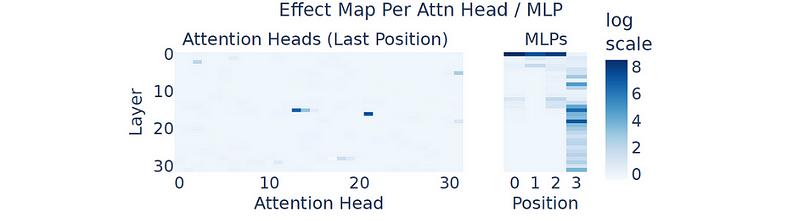
注意力头和MLP对算术计算的影响(名为“Arithmetic Without Algorithms: Language Models Solve Math With a Bag of Heuristics”的Arxiv研究论文)
早期MLP层处理操作数和运算符嵌入,而中到后层则专注于产生结果。
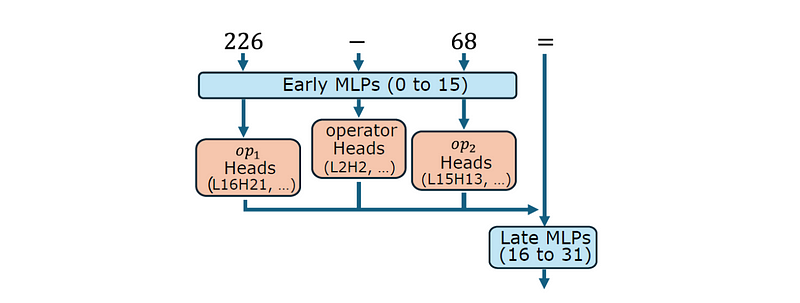
早期MLP与操作数和运算符嵌入合作,而中层和后层MLP影响最终结果(来源)
每层大约需要1.5%的神经元来正确计算算术提示。
这些神经元学习稀疏的、人类可识别的规则或启发式方法,而它们的组合使模型能够产生准确的输出。
其中一些启发式方法如下:
- **范围启发式:**当操作数或结果落在特定的数值范围内时使用。
- **模运算启发式:**当操作数或结果具有特定属性时使用,例如,是偶数或能被5整除。
- **模式识别启发式:**用于检测操作数或结果中的模式,例如,两个操作数都是奇数或其中一个比另一个大得多。
- **相同操作数启发式:**当两个操作数相等时使用。
- **直接结果启发式:**在结果直接从训练数据中记忆的情况下使用,例如,知道
226 – 68 = 158而不需要进一步工作。 - **间接启发式:**与直接结果启发式不同,这种启发式用于个体操作数具有特定特征,有助于轻松得出结果的情况,例如,操作数在
[100, 200]范围内。
这些启发式方法在训练初期出现,并随着时间的推移而发展,在后期检查点变得更加精细。
热图显示了神经元在解决它们之间的加法问题时对不同组合的操作数值的反应强度(来源)
我们离数学天才AI还有多远?
像MATH和GSM8K这样的流行基准测试在评估LLMs的数学能力方面存在缺陷。
首先,这些基准测试评估LLMs在高中和大学早期水平的能力。
其次,它们在许多研究论文和项目中的流行使用导致了数据污染。
因此,研究人员创建了一个新的基准测试,名为FrontierMath,以测试LLMs解决高级数学问题的能力。
FrontierMath包含了数百个来自不同领域的极其具有挑战性的数学问题,这些问题由专家数学家精心制作。
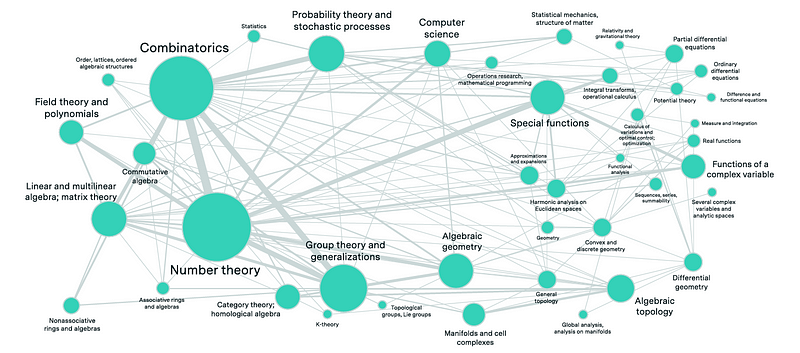
FrontierMath中的数学问题结合了不同的数学领域(节点大小告诉每个领域在问题中出现的频率,而互联显示了这些领域如何在单个问题中结合)(名为“FrontierMath: A Benchmark for Evaluating Advanced Mathematical Reasoning in AI”的ArXiv研究论文)
这些问题如此之难,以至于解决一个典型问题需要相关数学分支的研究者花费数小时的努力。
对于更难的问题,他们需要数天的时间!
看看其中的一些。
来自FrontierMath基准测试的三个数学问题的例子(来源)
你有兴趣知道我们最好的LLMs在它们上面的表现如何吗?
没有任何模型能在完整基准测试上实现哪怕是2%的成功率。
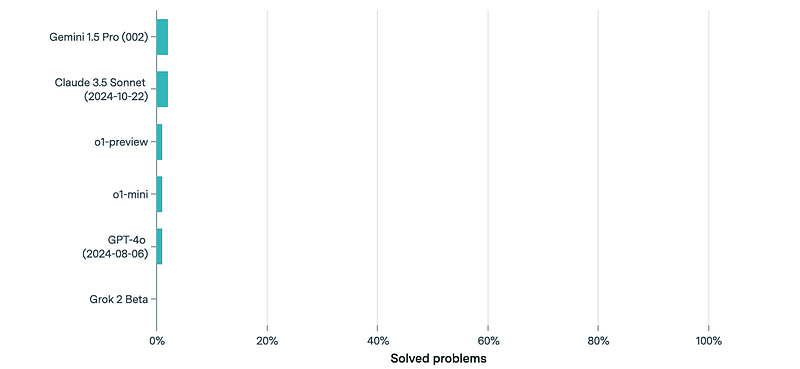
领先的LLMs在FrontierMath上基于单次评估的表现(来源)
对于任何模型至少能解决一次的问题(总共4个问题),并针对每个模型每个问题进行五次运行的重复试验,只有‘o1-preview’能在所有五次运行中正确解决问题。
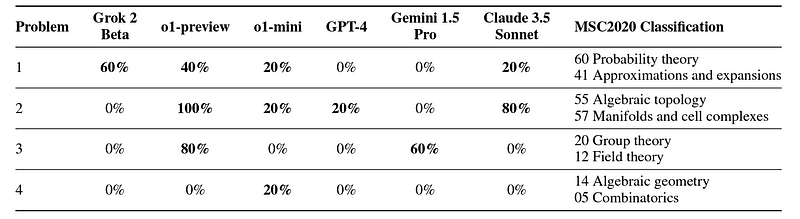
在五次测试运行中四个问题(任何模型至少能解决一次)的成功率(来源)
与其它基准测试相比,它们几乎达到了饱和点,给我们留下了LLMs在数学问题上特别擅长的错误印象。
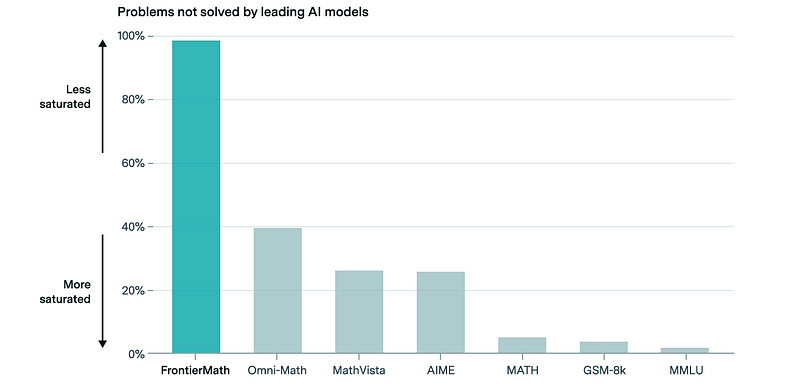
FrontierMath的未解决率超过98%,而GSM8K约为4%,MMLU为2%(来源)
一个LLM真的需要在FrontierMath基准测试上取得突破,才能夸耀其数学能力,而它们离这一点还很远。
我们领先的LLMs无法理解和解决数学问题,任何传播这一观点的人都在危言耸听。
是的,我们可能有一天会实现,但目前,人工通用智能(AGI)是一个遥远的梦想。
你对这个问题有什么看法?在下面的评论中告诉我。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









