







在元数据管理一文中,我们曾将数据比喻为一本本的书,将书的作者、出版时间等信息比喻为元数据。试想一下,假如你是一名新任的图书管理员,如何快速掌握图书馆的馆藏情况呢?假如你是一名读者,如何快速找到你需要的图书呢?想必你需要一份内容完整、结构清晰的图书清单。同样地,数据的管理者和使用者也需要类似的清单来快速了解、精准查找、正确使用组织机构的数据资产。这就是本文要介绍的数据目录(Data Catalog)。

含义
数据目录(Data Catalog)是一种数据资产清单,这些数据资产包括(但不限于)结构化数据、非结构化数据(例如文档、网页、邮件、社交媒体内容、图片影音等)、报告和查询结果、数据可视化与总览信息、机器学习模型、数据库之间的联系等。数据目录通过元数据和数据管理工具详细记录数据的来源、用途、使用方式等,便于使用者快速获取想要的数据。所以,也可以将数据目录视为元数据的集合。
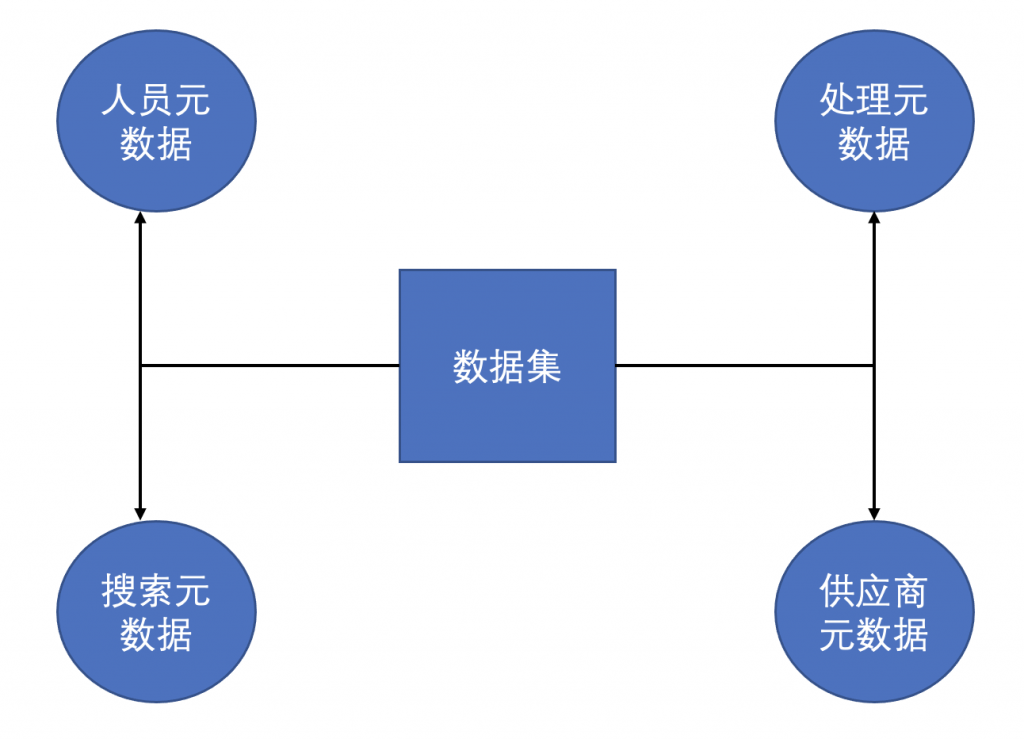
数据目录主要记录五类元数据主题:
数据集:数据集是机构人员可以访问的文件和表格,数据集可能位于数据湖、数据仓库、主数据库、或任何其他共享的数据资源。
人员元数据:描述和数据相关的人员角色,包括数据的使用者、监管者、管理员等。
搜索元数据:这是为数据元素添加的标签和关键词,便于搜索数据。
处理元数据:描述数据生命周期管理过程中的各项数据处理任务,例如更新数据、转换数据等。
供应商元数据:记录数据的来源、订阅源、许可限制等信息。
以上五类元数据中,数据集和处理元数据为数据血缘关系的主要组成内容,数据集间的转换关系由处理元数据来描述,表示数据集是如何通过更新、转换,从一个数据集到另一个数据集。进一步,数据集中的字段间也存在数据血缘关系,字段间进行数据更新和转换一般会用到 SQL 表达式。
使用
数据可能存储在数据库、云端、数据湖、文件或其他地方,通过数据目录可以将这些以不同形式存储在不同地方的数据整合到一起,便于搜索、预览数据,了解数据的上下文,分析数据血缘关系。数据目录提供的典型能力包括:采集并持续丰富元数据,搜索数据、自动发现相关数据、管理数据的使用,促进数据合规等。
与数据目录相关的人员主要可以分为三种角色。
数据工程师:需要借助一些工具采集数据,描述数据,将数据添加到数据目录中,查找并清理脏数据等。
数据管理员:类似于图书管理员,需要通过数据目录整理数据,维护数据质量,更新数据、记录数据使用情况、管理数据访问权限等。
数据消费者:希望通过数据目录直接获取数据,分析数据。就像网上购物一样,用户可以自己搜索、预览、获取想要的数据,无需依赖专业的 IT 人员或数据专家。
有了数据目录,数据使用者可以通过更完整的数据上下文挖掘出更深层次的数据价值,加深对数据的理解。普通用户可以通过数据目录直接获取数据,减轻数据 IT 人员的压力,提升数据的管理和使用效率。基于数据目录提供的信息,分析人员能获得更可靠的数据来源,提升数据分析的效率和分析结果的可靠性。
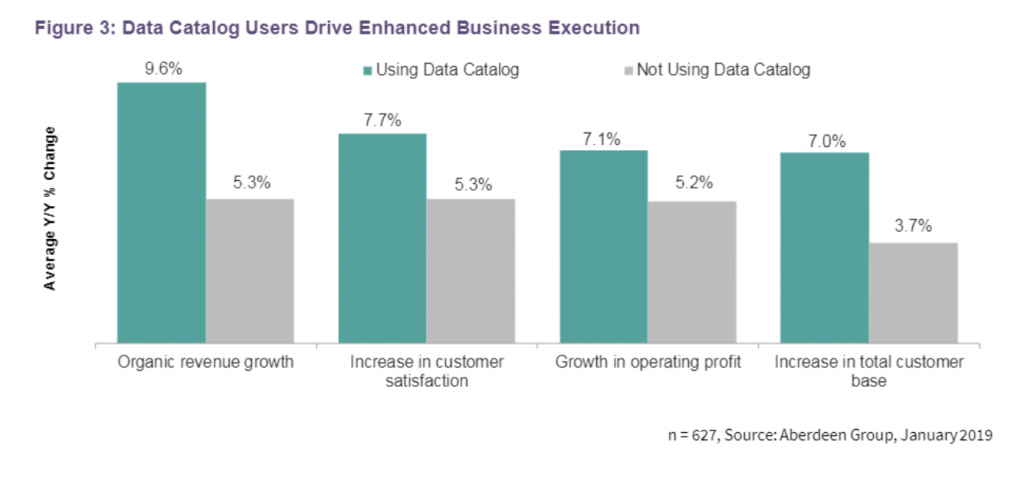
此外,在当今的数字经济时代,拥有大量的数据并且能够高效地利用这些数据,对于企业而言是一大显著的竞争性优势。企业可以借助数据目录更有效地组织、标识数据,界定数据的敏感性和访问权限,改善数据分析环境,此外,还有助于确保数据合规,降低数据风险。数据目录不仅能提升分析能力,还能改善公司业绩。根据全球权威调研机构 Aberdeen Group 的研究,使用数据目录的企业不仅客户数量增加,同时客户满意度也有所提升。
编制
编制数据目录的过程称为数据编目(Data Cataloging)。编制数据目录的过程主要涉及以下几个步骤:
1.捕获数据:
这一阶段需要思考两个问题。一是捕获哪些元数据,例如数据的结构、模式、语义等。二是如何捕获元数据,可能需要借助一定的工具管理数据的生命周期,做好容灾备份。推荐阅读:2022 年数据目录工具推荐
2.指派联系人
建立数据目录后,需要界定访问角色、权限、职责,以便用户在遇到问题时知道应该去哪里寻求帮助。
3.记录所有交互
每一次更改数据或代码或任何相关元素时,都将其记录下来。数据目录的维护工作应该关系到每位员工、关联到每次数据操作。
4.及时更新数据目录
开发人员可能不时修改数据库的结构,数据科学家可能将数据移动到不同环境,数据自身也可能频繁迭代。因此,需要及时更新数据目录,确保数据目录提供的信息是有效的,可靠的。
5.根据需求优化数据目录
数据目录没有统一的模板样式,契合实际需求和具体场景的数据目录才能发挥最大价值。














 179
179











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









