






布隆过滤器 Bloom Filter
前序
公司架构大佬封装了一套布隆过滤器的集群,并提供给各个业务进入,用来判断数据是否在缓存中,以此提高数据在缓存中的命中率,避免数据库穿透的危险。 因此在对接次技术的时候,对此做了一些调研,并记录下来
什么是布隆过滤器
布隆过滤器(Bloom Filter)本质是一种数据结构,比较巧妙的概率型数据结构。特点是高效的插入和查询,可以快速的定位到数据是否存在。
设计想法
Bloom Filter 是一个有m长度的bety数组和K个哈希函数组成的数据结构,数组是初始为0,所有的哈希函数可以将数据尽可能的分散均匀。而这些数组对应的存储则是byte字节 也就是一个字节,因此可以大大缩小在内存中占用过的空间。
当一个数据插入时,经过K个哈希哈函数的哈希计算,每个哈希函数都能得到一个哈希计算结果,然后作为数组中的下标,并将该数据经过的K个哈希函数计算的哈希结果对应的下标置为1.
当查询一个数据是否存在时,同样将该数据进行K次哈希函数进行哈希得到的哈希结果,然后判断是否所有的哈希结果的值为1 如果有存在为0的,则表示该数据一定不存在。如果该数据的所有的哈希结果的值对应的下标的值都是1 则表示有很大的可能性存在该数据,因为有可能其他的数据经过哈希函数后的哈希结果和需要查询的数据的哈希对应的地址相同。
优缺点
布隆过滤器的优点则是具有以下特点:
1.占用数据内存小,数据的值都是通过byte字节展示的。 因此在相比较hash函数来说,避免了hash key或者value占用的大量的内存。且hashMap仅仅经过一次Hash计算,在数据的hash碰撞上是采链条的形式处理,这就在比较的时候只能是线性查找。 因此在大量的数据查询结构中,布隆过滤器要占很多的优势,不仅计算快,而且对于内存的使用上也是可以减少很多。
2. 数据查询和插入比较快,由于底层是数组的格式,且数组的值都是1 byte,数据的插入和修改在确定数组的下标,就可以快速的插入和修改的,而且查询也是同样通过数组的形式 更加的快速。
3. 可以经过多次hash计算,并指定不同的hash计算方式,可一定程度上减少Hash碰撞。
但是同样存在的缺点。
4. 数据查询的结果是可能存在,而不是必定存在。
5. 只能插入和查询元素,不能删除元素。 可以想象,在插入的时候可能存在不同的值哈希到同一个下标地址,因此在删除的时候,可能存在对其他数据的影响。
6. 当集合快满时,即接近预估最大容量时,误报的概率会变大。
布隆过滤器的其他使用场景
那么针对以上的布隆过滤器的有缺点,我们可以设想一下的布隆过滤器的使用场景。
- 用于避免缓存穿透,缓存崩塌的场景,如果一个用户通过一个不存在数据库的主键查询业务,但是通过在redis中无法查询到该数据,这时候传统的处理方式就是查询数据库,然后防到redis缓存中。 当然查不到的时候可以用空对象的来避免一个key的重复缓存穿透,但是如果大量不存在的key呢? 这个时候就可用布隆过滤器在查询缓存之前,确认是否存在,如果存在,就查询数据库,注意这里的存在不是必然存在,但是也大大减少了缓存穿透的影响。
- 在爬虫系统中,我们需要对 URL 进行去重,已经爬过的网页就可以不用爬了。但是 URL 太多了,几千万几个亿,如果用一个集合装下这些 URL 地址那是非常浪费空间的。这时候就可以考虑使用布隆过滤器。它可以大幅降低去重存储消耗,只不过也会使得爬虫系统错过少量的页面。
- WEB拦截器 相同请求拦截防止被攻击。用户第一次请求,将请求参数放入BloomFilter中,当第二次请求时,先判断请求参数是否被BloomFilter命中。可以提高缓存命中率
- 恶意地址检测 chrome 浏览器检查是否是恶意地址。 首先针对本地BloomFilter检查任何URL,并且仅当BloomFilter返回肯定结果时才对所执行的URL进行全面检查(并且用户警告,如果它也返回肯定结果)。
因此布隆过滤器在对查准度要求没有那么苛刻,而对时间、空间效率要求较高的场合非常合适
布隆过滤器的容错率计算
布隆过滤器存在这一定的误判型,根据k个哈希结果,m个数组长度,数组中的n个元素的容错率的计算方式。
- 当在向m长度的数组长度中,插入一个元素,其K个哈希函数会将该数组下标的值标志为1. 因此在插入完该数据后,该数组下标依然是0的概率是:
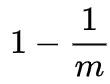
- 现有k个哈希函数,并插入n个元素,自然就可以得到该比特仍然为0的概率是:
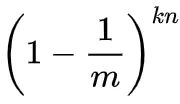
- 反过来,它被置为1的概率就是:
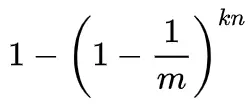
- 就是说,如果在插入n个元素后,我们用一个不在集合中的元素来检测,那么所有哈希函数对应的比特都为1的概率为:
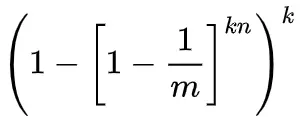
- 当n比较大时,根据重要极限公式,可以近似得出布隆过滤器的容错率是多少:
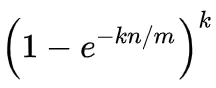
因此可以得到: - 位数组长度m越大,容错率越小
- 插入的n的个数越多,容错率就越大。
但是其实已经有目前已经造好的轮子来计算容错率的大小了,但是各位看官依然要分清楚 M N K 这些数字的含义哦。
布隆过滤器容错率计算
2020.6.7 更新========================
今天来实战通过Redis来实现Bloom的使用。
redis在4.0版本以后支持使用bloom的使用。 底层是使用Redis SetBit的方法
我们先准备好环境:
Mac安装redis的简单环境。
安装brew
安装redis
我们先看在 在官网中redis bit 的说明文档
When key does not exist, a new string value is created. The string is grown to make sure it can hold a bit at offset. The offset argument is required to be greater than or equal to 0, and smaller than 2[^32] (this limits bitmaps to 512MB). When the string at key is grown, added bits are set to 0.
redis在创建一个新的key的时候,需要保证该key对应的偏移量在 0 ~ 2的32次方的bit位(在内存中就是512MB),如果这个key得位移下标超过这个返回,则都返回0
先来看看 set bit 是怎么操作数据的
setbit bitMap的key 偏移量 1/0
以上只是操作单个下标的值,如果需要设置多个下标的值 则需要如下操作
bitfield bit的key名称 set u1 下标偏移 1/0 注意哈 我在3的下标设置为 2 下边在get的时候就没有获取到


废话不多说 ,上代码
package com.example.demo.redisbloom;
import lombok.extern.slf4j.Slf4j;
import org.junit.Test;
import org.springframework.stereotype.Service;
import redis.clients.jedis.Jedis;
import redis.clients.jedis.JedisPool;
import java.util.Arrays;
import java.util.List;
import java.util.stream.Collectors;
@Slf4j
@Service
public class RedisBloom {
private static final String BLOOM_FILTER_KEY ="BLOOM_FILTER_KEY_%s";
private static JedisPool jedisPool;
static {
jedisPool = new JedisPool("localhost",6379);
}
@Test
public void testLongBitMap(){
try(Jedis resource = jedisPool.getResource();) {
String bloomKey = String.format(BLOOM_FILTER_KEY, "test");
resource.setbit(bloomKey,10L,true);
resource.setbit(bloomKey,9L,true);
resource.setbit(bloomKey,8L,true);
Boolean getbit = resource.getbit(bloomKey, 10);
log.error("testLongBitMap getKey {}",bloomKey);
} catch (Exception e) {
log.error("testLongBitMap error ",e);
}
}
/**
* 但是如果是要存的是String的key应该怎么办呢?
* 按照文章说的 我们需要计算对应的key的hash 然后根据hash计算的结果作为下标来计算下标
* 但是如果要减少对应的hash碰撞,我们需要进行多次不同的hash来处理
*
* 这里我们借用 jdk实现的 hash方法
*/
public long hashMethod(String key){
char[] value = key.toCharArray();
int h = 0;
if (h == 0 && value.length > 0) {
char val[] = value;
for (int i = 0; i < value.length; i++) {
h = 30 * h + val[i];
}
}
return h;
}
public long hashMethod2(String key) {
char[] value = key.toCharArray();
int h = 0;
if (h == 0 && value.length > 0) {
char val[] = value;
for (int i = 0; i < value.length; i++) {
h = 25 * h + val[i];
}
}
return h;
}
@Test
public void testStringBitMap(){
List<String> stringList = Arrays.asList("test", "中国人", "星巴克", "体验店", "213231");
List<List<Long>> listList = stringList.stream()
.map(s -> Arrays.asList(hashMethod(s), hashMethod2(s)))
.collect(Collectors.toList());
try(Jedis resource = jedisPool.getResource();) {
String bloomKey = String.format(BLOOM_FILTER_KEY, "test");
for (List<Long> longs : listList) {
for (Long aLong : longs) {
resource.setbit(bloomKey,aLong,true);
}
log.info("testStringBitMap longs{} setsucess",longs);
}
String key1 ="中国人";
String key2 ="今日头条";
List<Long> longs = Arrays.asList(hashMethod(key1), hashMethod2(key1));
log.info("testStringBitMap key1 {},hashResult {}",key1,longs);
List<Long> longs1 = Arrays.asList(hashMethod(key2), hashMethod2(key2));
log.info("testStringBitMap key2 {},hashResult {}",key2,longs1);
boolean b = longs.stream().allMatch(aLong -> resource.getbit(bloomKey, aLong));
log.info("testStringBitMap match key {},result {}",key1,b);
boolean b2 = longs1.stream().allMatch(aLong -> resource.getbit(bloomKey, aLong));
log.info("testStringBitMap match key {},result {}",key2,b2);
}
}
}
看打印的结果Key的hash和结果 :

当然为了更好的减少hash碰撞的问题 可以多次进行hash保证hash的结果碰撞概率减少。
参照文章1: https://www.jianshu.com/p/bef2ec1c361f
参考文章2: https://www.jianshu.com/p/3e9282ca7080















 1977
1977











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









