







一,浏览器与客户端交互的方式
1 在服务端正常启用的前提下,打开客户端主机的浏览器,输入服务器的地址和端口
2 观察浏览器向服务器发出请求后,服务器收到的请求包格式
3分析格式,并从格式中获取关键信息
服务端程序
# from ZMQ@cuc
import socket
server=socket.socket()
server.bind(('127.0.0.1',8080))
server.listen(5)
while True:
conn,addr=server.accept()
data=conn.recv(1024)
print(data)
conn.send(b'HTTP/1.1 200 ok\r\n\r\nhello web')#conn.send(b'HTTP/1.1 \r\n\r\nhello web')也可以
conn.close()
在上面的服务端代码中我们通过输出接收到的数据信息来查看浏览器与客户端之间传送数据时采用的格式
当在浏览器中输入:
http://127.0.0.1:8080/he
时,对应的输出为


 因此服务器要实现能够与浏览器进行数据交互,必须采用浏览器可识别的数据格式。
因此服务器要实现能够与浏览器进行数据交互,必须采用浏览器可识别的数据格式。
在这个命令中,\r\n\r\n 是一个特殊的字符序列它在 HTTP 协议中用于分隔头部(headers)和响应体(response body)。
具体来说,这个命令 conn.send(b'HTTP/1.1 200 ok\r\n\r\nhello web') 发送了一个简单的 HTTP 响应给客户端:
HTTP/1.1:表示 HTTP 协议的版本号,这里使用的是 HTTP 1.1 版本。200:表示 HTTP 响应的状态码。在这个例子中,状态码为 200,表示请求成功。(基于B/S是一种特殊的C/S,所以服务器发送的信息都是在客户端发起请求的前提下,做出对应的响应信息,本信息用来说明成功收到客户端的请求下作出的响应)ok:是一个简短的文本描述,用于对状态码进行说明。\r\n\r\n:是 HTTP 头部与响应体之间的分隔符。两个连续的回车换行符表示头部结束,没有其他头部字段了,紧接着就是响应体的内容。hello web:是响应体的内容,这里是一个简单的示例,表示向客户端发送字符串 “hello web”。
通过发送这个 HTTP 响应,服务器向客户端传递了状态码和响应内容,以便客户端能够理解并处理服务器的响应。在这个例子中,状态码为 200 表示成功,而响应体中的 “hello web” 则是服务器返回给客户端的文本消息。
二 实现根据不同的输入请求进行不同的内容响应
根据内容一格式的分析,我们可以发现在客户端用浏览器提交请求时,命令中明确表示需要的文件路径, 也即是在浏览器所输入的URL中路径(浏览器收到服务器后所显示的主页内容)
 因此,客服端如果要根据用户在浏览器中输入的请求中不同路径实现不同的响应内容,则需要:
因此,客服端如果要根据用户在浏览器中输入的请求中不同路径实现不同的响应内容,则需要:
从收到的请求数据中提取出客户的路径字段
根据路径字段进行请求内容的响应设置
路径字段的提取
在前面代码的基础上,对收到的data使用split函数进行切割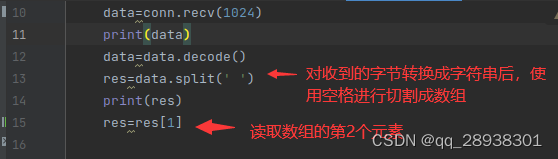 在Python中,
在Python中,split()函数是一个字符串方法,用于将字符串拆分为子字符串,并返回一个包含拆分后子字符串的列表。
split()函数可以接受一个可选的分隔符参数,用于指定在哪些位置进行拆分。如果没有指定分隔符,则默认使用空格字符作为分隔符。下面是split()函数的基本语法:
str.split(separator, maxsplit)
其中,separator是可选的分隔符参数,用于指定拆分字符串的位置,默认为None,表示使用空格字符作为分隔符。maxsplit也是可选的参数,用于指定最大拆分次数。如果指定了maxsplit,则最多只会拆分出maxsplit + 1个子字符串。如果省略maxsplit参数,则会拆分所有可能的子字符串。
下面是一个简单的示例,展示如何使用split()函数拆分字符串:
text = "Hello, world!"
result = text.split(",") # 使用逗号作为分隔符
print(result) # 输出: ['Hello', ' world!']
在上面的示例中,我们使用逗号作为分隔符将字符串"Hello, world!"拆分为两个子字符串,即['Hello', ' world!']。
需要注意的是,split()函数返回一个列表,其中包含拆分后的子字符串,列表的操作可以使用下标进行,注意下标从0开始
列表相关操作
在Python中,列表是一种有序、可变、可重复的数据结构,用于存储多个元素。列表可以包含不同类型的元素,例如整数、字符串、布尔值等。列表是一种非常常用和强大的数据结构,提供了许多操作和方法来操作和处理列表数据。
下面是一些常见的列表操作:
在Python中,列表是一种有序、可变、可重复的数据结构,用于存储多个元素。列表可以包含不同类型的元素,例如整数、字符串、布尔值等。列表是一种非常常用和强大的数据结构,提供了许多操作和方法来操作和处理列表数据。
下面是一些常见的列表操作:
-
创建列表:
my_list = [1, 2, 3, 4, 5] # 创建一个包含整数的列表 my_list2 = ["apple", "banana", "orange"] # 创建一个包含字符串的列表 my_list3 = [] # 创建一个空列表 ``` -
访问列表元素:
print(my_list[0]) # 访问列表中的第一个元素,输出: 1 print(my_list[-1]) # 访问列表中的最后一个元素,输出: 5 ``` -
修改列表元素:
my_list[2] = 10 # 修改列表中的第三个元素 ``` -
切片操作:
print(my_list[1:3]) # 获取索引1到2的元素,输出: [2, 3] print(my_list[:3]) # 获取从开头到索引2的元素,输出: [1, 2, 3] print(my_list[2:]) # 获取从索引2到末尾的元素,输出: [3, 4, 5] ``` -
添加元素:
my_list.append(6) # 在列表末尾添加一个元素 my_list.insert(0, 0) # 在指定位置插入一个元素 ``` -
删除元素:
del my_list[2] # 删除指定位置的元素 my_list.remove(3) # 删除第一个匹配的元素 ``` -
列表长度:
length = len(my_list) # 获取列表的长度 ``` -
列表排序:
my_list.sort() # 升序排序 my_list.sort(reverse=True) # 降序排序 ``` -
列表拼接:
new_list = my_list + my_list2 # 拼接两个列表 ``` -
列表循环:
for item in my_list: print(item) # 逐个输出列表中的元素
这些只是列表的一些基本操作,Python还提供了许多其他的方法和函数来处理列表数据。你可以根据具体的需求使用适当的列表操作来操作和处理列表。
三 响应内容设置
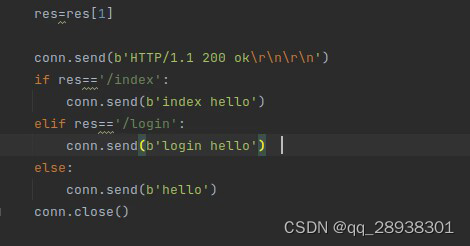
我们使用split()函数获取到了客户输入的URL请求文件路径,服务器使用if语句对收到的请求进行判断。
比如我们需要在服务器上实现:根据客户端发送的请求路径,如果请求路径为/index,则发送index hello;如果请求路径为/login,则发送login hello;否则,发送hello。
conn.send(b'HTTP/1.1 200 ok\r\n\r\n')
if res=='/index':
conn.send(b'index hello')
elif res=='/login':
conn.send(b'login hello')
else:
conn.send(b'hello')
conn.close()
让我们逐行解释这段代码的含义:
-
conn.send(b'HTTP/1.1 200 ok\r\n\r\n')
这行代码发送HTTP响应头给客户端,表示响应成功。\r\n是回车和换行符,用于分隔HTTP头和正文。 -
if res=='/index':
这是一个条件语句,检查请求路径是否为/index。 -
conn.send(b'index hello')
如果请求路径是/index,则发送index hello作为响应给客户端。 -
elif res=='/login':
这是另一个条件语句,检查请求路径是否为/login。 -
conn.send(b'login hello')
如果请求路径是/login,则发送login hello作为响应给客户端。 -
else:
这是一个条件语句的默认分支,当请求路径不是/index或/login时执行。 -
conn.send(b'hello')
在默认情况下,发送hello作为响应给客户端。 -
conn.close()
关闭与客户端的连接。
四 实现页面html的传输与显示
HTML(Hypertext Markup Language)是一种用于创建网页的标记语言。HTML使用标签(tags)来描述网页的结构和内容。下面是一个简单的HTML页面的基本结构和常见的元素:
<!DOCTYPE html>
<html>
<head>
<title>Page Title</title>
</head>
<body>
<h1>Heading 1</h1>
<p>This is a html.</p>
<a href="https://www.example.com">Link</a>
<img src="image.jpg" alt="Image">
</body>
</html>
上述代码展示了一个最简单的HTML页面:
<!DOCTYPE html>:声明文档类型为HTML5。<html>:根元素,表示整个HTML文档的开始。<head>:头部元素,包含与文档相关的元信息和链接引用。<title>:标题元素,定义页面的标题,将显示在浏览器的标题栏或选项卡上。<body>:主体元素,包含页面的可见内容。<h1>:标题元素,表示一级标题。<p>:段落元素,用于包含文本段落。<a>:链接元素,用于创建超链接到其他页面或资源。<img>:图像元素,用于插入图像,通过src属性指定图像的URL,alt属性提供替代文本。
综合应用,在B/S模式下进行页面的请求与响应
根据上面介绍的B/S工作原理,以及html文本格式,实现不同路径中页面的读取与回显
1 创建页面文件
在当前路径下新建一个html
在html文件下按照格式要求写入对应的代码
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>web and html test</title>
</head>
<body>
<p>this is a html</p>
</body>
<h1>hell this is test</h1>
</html>
2 书写服务端代码(web_if.py)
# from ZMQ@cuc
# date 2/24/23
import socket
server=socket.socket()
server.bind(('127.0.0.1',8080))
server.listen(5)
while True:
conn,addr=server.accept()
data=conn.recv(1024)
print(data)
data=data.decode()
res=data.split(' ')
print(res)
res=res[1]
conn.send(b'HTTP/1.1 200 ok\r\n\r\n')
if res=='/index':
conn.send(b'index hello')
elif res=='/login':
with open(r'01.html','rb') as f:
conn.send(f.read())
conn.send(b'login')
else:
conn.send(b'hello')
conn.close()
注意:代码使用 open() 打开了名为 '01.html' 的文件,并“r(只读模式)”对文件进行以二进制模式('rb')进行读取(等同于字节编码可直接传送通过网络传送给接收方)。文件对象被赋值给变量 f。接着,使用 f.read() 读取文件的内容,并通过 conn.send() 发送给客户端。
使用 with 语句可以确保文件在使用完毕后正确关闭,避免资源泄漏。with 语句会在代码块结束后自动关闭文件,即使在处理过程中出现异常也能正常关闭文件
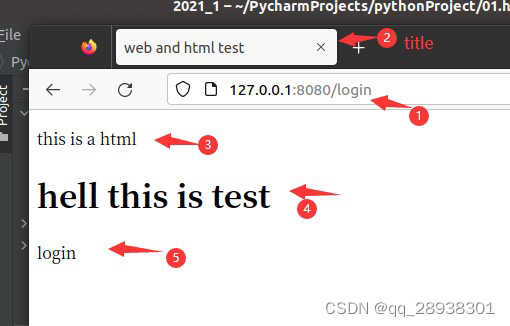
3 测试
运行服务端程序后,打开浏览器输入URL以查看
结果如下















 986
986











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









