







Hadoop是一个由Apache基金会所开发的分布式系统基础架构。
Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求,可以以流的形式访问(streaming access)文件系统中的数据。
Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,则MapReduce为海量的数据提供了计算。
总所周知,大数据技术分为云计算与大数据存储,而Hadoop便是进行云计算的工具。
学习一项技术,首先是使用它。我们便来看看Hadoop环境如何搭建。
一、需要下载的软件
1、jdk for linux1.7+
2、hadoop-2.6.4
二、步骤及环境配置
由于jdk的安装与配置十分简单,再次便不再赘述。
1、将hadoop-2.6.4.tar.gz解压缩
$mkdir /software
cd /software
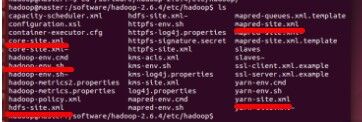
tar -zxvf hadoop-2.6.3.tar.gz 2、进入/software/hadoop-2.6.4/etc/hadoop下可以看到如下几个文件其中需要配置的文件在这张图片的红线上。
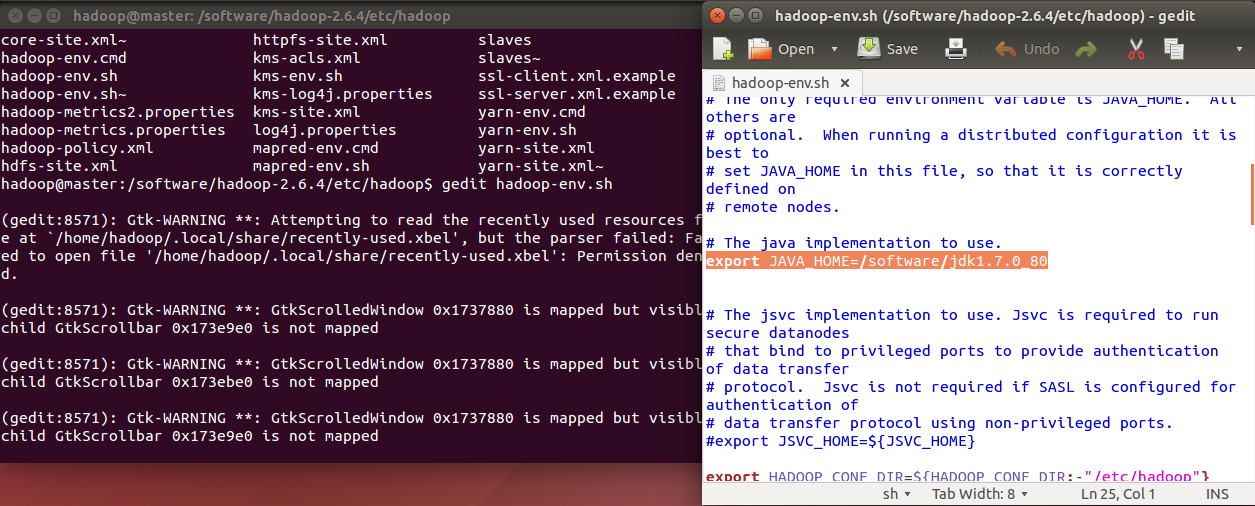
a、hadoop-env.sh文件配置
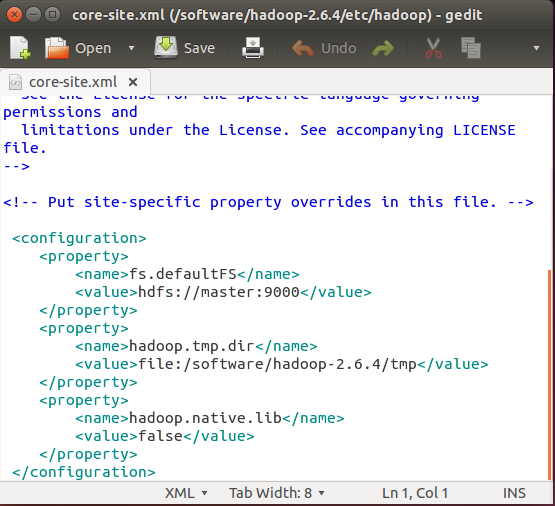
b、core-site.xml文件配置
其中hadoop.tmp.dir的value是你的hadoop安装目录下的/tmp目录
c、hdfs-site.xml文件配置
其中:
dfs.replication是集群中共有多少成员(由于是伪分布式主从都是自己,所以为1)
dfs.namenode.name.dir是命名节点目录其路径在你的hadoop安装目录下的/dfs/name
dfs.datanode.data.dir是命名节点目录其路径在你的hadoop安装目录下的/dfs/data

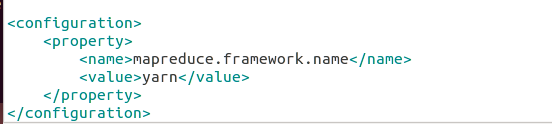
d、mapred-site.xml文件配置
f、yarn-site.xml文件配置

在slaves中配置集群的成员名
在/etc/hosts中配置当前主机的IP即用户名
完成以上配置之后,需将hadoop格式化方能启动:
注:需使用ssh自动生成秘钥方能启动hadoop
cd /software/hadoop2.6.4 #进入hadoop安装目录
bin/hdfs namenode -format #格式化操作期间可能会出现[yes/no]选项,这是因为你原先便有name目录,让你选择是否需要重新创建,选yes即可
三、启动hadoop
sbin/start-dfs.sh如果出现下图情况,请进入/etc/hosts中查看你所配的ip是否正确,从其他机器是否能Ping通。

sbin/start-yarn.sh
jps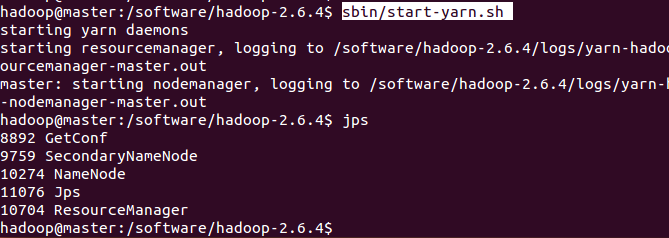
出现以上几个端口即为配置成功,开启成功
四、打印报表
bin/hdfs dfsadmin -report虽然只是云计算的第一步,但是繁琐的配置依旧容易出现问题,也是值得细细研究与体会的。















 1513
1513

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









