







HDFS——不怕故障的海量存储
HDFS(Hadoop Distributed File System,Hadoop分布式文件系统),作为Hadoop的核心技术之一,是分布式计算中数据存储管理的基础。他所具有的高容易、高可靠性、高可扩展性,高获得性、高吞吐率等特征为海量数据提供了不怕故障的存储。
1、HDFS体系结构
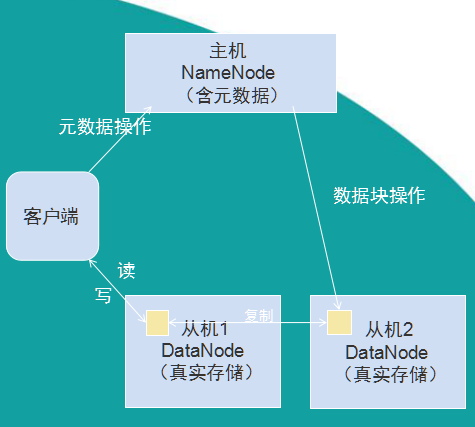
HDFS是一个主/从(Master/Slave)体系结构,它既像传统的文件系统一样,可以通过目录路径对文件执行增删查改操作。更由于分布式存储的性质,让HDFS集群拥有一个NameNode和一些DataNode。NameNode管理文件系统的元数据,DataNode存储实际的数据。客户通过同NameNode和DataNodes的交互访问文件系统。客户联系NameNode以获取文件的元数据,再与DataNode进行I/O操作的交互。
2、简单的操作
创建文件
package com.yc.hadoop;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class CreateFile {
public static void main(String[] args) throws IOException {
try {
Configuration conf=new Configuration(); //寻找配置
URI uri=new URI("hdfs://192.168.1.108:9000"); //hdfs主机uri
FileSystem hdfs=FileSystem.get(uri, conf); //创建文件管理系统
//创建文件
byte[] buff="hello word".getBytes();
Path dfs=new Path("/a"); //所创建的文件名
FSDataOutputStream out=hdfs.create(dfs);
out.write(buff);
//上传文件(复制文件)
Path p1=new Path("C:\\Users\\wrm\\Desktop"); //文件在客户端上的路径
Path p2=new Path("/input/"); //上传到的目的路径
hdfs.copyFromLocalFile(p1, p2);
//删除文件
Path dfs1=new Path("/input/");
boolean isDelete= hdfs.delete(dfs, true); //true表示循环删除该目录下的所有文件
System.out.println(isDelete);
} catch (IllegalArgumentException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (URISyntaxException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
基本的HDFS操作便可以实现了。当然更多的方法可以查看API















 162
162

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









