







 本文探讨了大规模分布式机器学习的挑战,并详细介绍了采用第三代参数服务器的开源实现,该服务器支持高效的异步通信、灵活的一致性模型、弹性可扩展性、错误容忍和持久性以及易用性。其架构包括(Key,Value) Vectors、Range Push and Pull、User-Defined Functions等,旨在解决机器学习中的网络带宽需求、顺序性和错误容忍问题。"
132822589,19694698,Python实现人脸识别技术,"['计算机视觉', 'Python', '人工智能']
本文探讨了大规模分布式机器学习的挑战,并详细介绍了采用第三代参数服务器的开源实现,该服务器支持高效的异步通信、灵活的一致性模型、弹性可扩展性、错误容忍和持久性以及易用性。其架构包括(Key,Value) Vectors、Range Push and Pull、User-Defined Functions等,旨在解决机器学习中的网络带宽需求、顺序性和错误容忍问题。"
132822589,19694698,Python实现人脸识别技术,"['计算机视觉', 'Python', '人工智能']
采用参数服务器的大规模分布式机器学习
1. 简介
大规模分布式机器学习三大挑战:
- 访问这些参数(训练数据范围达到1TB到1PB,参数量范围10^9^ ~ 10^12^)需要巨大的网络带宽。
- 很多机器学习算法是有顺序性的。当同步的花费、机器的延迟高时,会导致栅栏效应影响性能。
- 错误容忍是决定性的。学习任务(Learing Tasks)经常在机器可能是不可靠的、工作可能被占用的云环境中执行。
本文描述了第三代参数服务器的开源实现
该参数服务器的五个关键特征:
- 高效的通信(Efficient communication):异步通信模型不阻碍计算,最优化机器学习任务来减少网络负担。
- 灵活的一致性模型(Flexible consistency models):宽松的一致性进一步隐藏同步花销和延迟。允许算法设计者去平衡算法收敛率与系统效率。
- 灵活的可扩展性(Elastic Scalability):在无需重启运行中的框架下便可添加新节点。
- 错误容忍和持久(Fault Tolerance and Durability)
- 易用(Ease of Use)
2. 架构

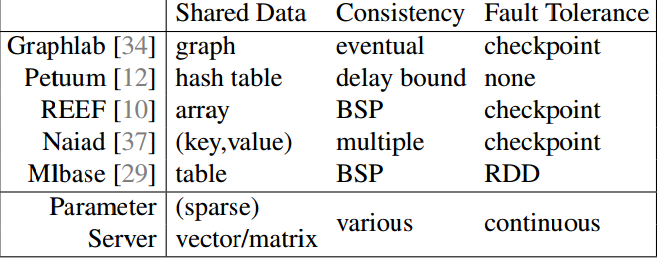
风险最小化问题:学习一个模型能通过future example x 来预测值
loss函数 l(x+y+w) 表示在训练数据中预测错误,正则化函数 Ω(w) 使模型复杂,因此我们希望 F(w) 最小化。
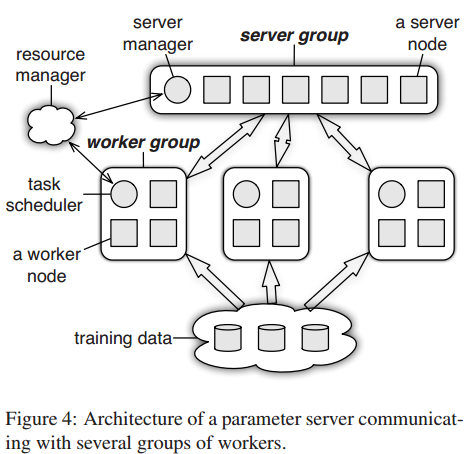
如上图figure4。参数服务器可以同时跑不止一个算法。
每个服务器节点维持全局共享参数的一部分。为保证可靠性,服务器节点之间可以相互通信来复制、迁移参数。用一个服务器管理节点来维持服务器元数据的一致性,例如节点是否存活,参数划分的分配情况。
每个工作组跑一个应用。工作节点在本地存储一部分训练数据来计算本地梯度等值。工作节点只与服务器节点通信来更新和取回共享参数(工作节点相互之间不通信)。每个工作组设置一个 计划表节点用来分配任务给工作节点和监视它们的进程。若增加或移除了工作节点,它将重新安排未完成的任务。
2.1 (Key,Value) Vectors
共享参数以(Key,Value) Vectors的方式传输。
2.2 Range Push and Pull
在节点间数据传输采用Push、Pull操作。
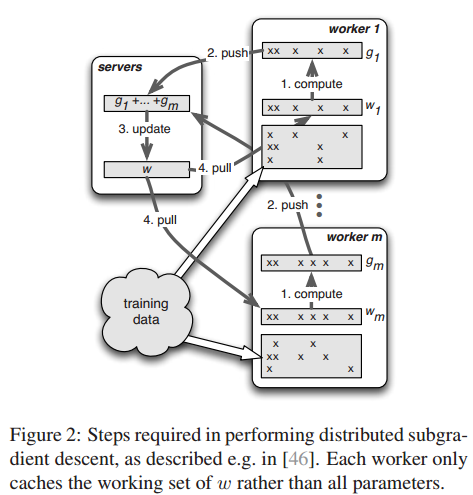
- 在Algorithm 1,每个工作节点Push它全部的本地梯度到参数服务器,然后Pull更新的参数回来。
- 在algorithm 3,每次传输一个范围的keys。

- 参数服务器支持range-based push and pull。 设 R
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 652
652

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









