






 本文深入解析了聚类分析中关键的概念——肘部法则与轮廓系数。肘部法则通过成本函数帮助确定最优聚类数量,而轮廓系数则评估聚类效果,结合内聚度和分离度衡量聚类质量。
本文深入解析了聚类分析中关键的概念——肘部法则与轮廓系数。肘部法则通过成本函数帮助确定最优聚类数量,而轮廓系数则评估聚类效果,结合内聚度和分离度衡量聚类质量。
一、肘部法则–聚类数量选择
肘部法则的计算原理是成本函数,成本函数是类别畸变程度之和,每个类的畸变程度等于每个变量点到其类别中心的位置距离平方和(类内部的成员彼此越紧凑则类的畸变程度越小,越分散越大)。在选择类别数量上,肘部法则会把不同值的成本函数值画出来。随着值的增大,每个类包含的样本数会减少,于是样本离其重心会更近平均畸变程度会减小。随着值继续增大,平均畸变程度的改善效果会不断减低。值增大过程中,畸变程度的改善效果下降幅度最大的位置对应的值就是肘部。
二、轮廓系数–聚类效果评估
轮廓系数是聚类效果好坏的一种评价方式,它结合内聚度和分离度两种因素。
根据样本i的簇内不相似度ai和簇间不相似度bi ,定义样本i的轮廓系数si, si接近1,则说明样本i聚类合理;si接近-1,则说明样本i更应该分类到另外的簇;若si 近似为0,则说明样本i在两个簇的边界上。所有样本的 si 的均值称为聚类结果的轮廓系数,是该聚类是否合理、有效的度量。
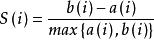

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









