










一、模型图

二、构图方式
滑动窗口,捕捉共现边
三、消息传递

聚合,通过GRU训练。
四,读出
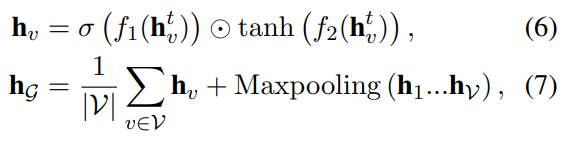
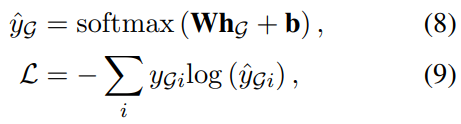
五,资源下载
TextING
The implementation of TextING
Require
Python 3.7.6
torch 1.5.1
torch-geometric 1.6.1
Source
Download corpus.zip
https://download.csdn.net/download/qq_28969139/13061605
zip ./corpus
corpus/20ng.labels.txt
corpus/20ng.texts.txt
...
--------------------------
Download golve.6B.zip
https://download.csdn.net/download/qq_28969139/14033550
zip ./source
source/glove.6B.50d.txt
source/glove.6B.100d.txt
...
Run 'python handle_glove.py'
Preprocess
Run 'python preprocess.py'
Run 'python prebuild.py'
Run
Run 'python train.py'
1目录结构
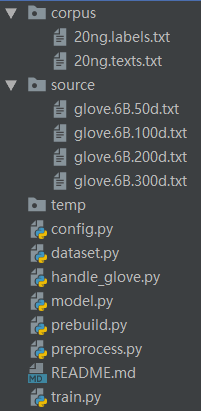
2代码
config.py
# static params
args = {
'20ng':
{'train_size': 11314,
'test_size': 7532,
'valid_size': 1131,
"num_classes": 20
},
'aclImdb':
{'train_size': 25000,
'test_size': 25000,
'valid_size': 2500
},
'ag_news':
{'train_size': 120000,
'test_size': 7600,
'valid_size': 12000
},
'dblp':
{'train_size': 61479,
'test_size': 20000,
'valid_size': 6148
},
'mr':
{'train_size': 7108,
'test_size': 3554,
'valid_size': 711,
"num_classes": 2
},
'ohsumed':
{'train_size': 3357,
'test_size': 4043,
'valid_size': 336,
"num_classes": 23
},
'R8':
{'train_size': 5485,
'test_size': 2189,
'valid_size': 548,
"num_classes": 8
},
'R52':
{'train_size': 6532,
'test_size': 2568,
'valid_size': 653,
"num_classes": 52
},
'TREC':
{'train_size': 5452,
'test_size': 500,
'valid_size': 545
},
'WebKB':
{'train_size': 2803,
'test_size': 1396,
'valid_size': 280
},
'wiki':
{'train_size': 3000,
'test_size': 127000,
'valid_size': 300
}
}
dataset.py
from config import args
import joblib
import numpy as np
from torch_geometric.data import Data, DataLoader
import torch
import random
from tqdm import tqdm
class MyDataLoader(object):
def __init__(self, dataset, batch_size, mini_batch_size=0):
self.total = len(dataset)
self.dataset = dataset
self.batch_size = batch_size
self.mini_batch_size = mini_batch_size
if mini_batch_size == 0:
self.mini_batch_size = self.batch_size
def __getitem__(self, item):
ceil = (item + 1) * self.batch_size
sub_dataset = self.dataset[ceil - self.batch_size:ceil]
if ceil >= self.total:
random.shuffle(self.dataset)
return DataLoader(sub_dataset, batch_size=self.mini_batch_size)
def __len__(self):
if self.total == 0: return 0
return (self.total - 1) // self.batch_size + 1
def split_train_valid_test(data, train_size, valid_part=0.1):
train_data = data[:train_size]
test_data = data[train_size:]
random.shuffle(train_data)
valid_size = round(valid_part * train_size)
valid_data = train_data[:valid_size]
train_data = train_data[valid_size:]
return train_data, valid_data, test_data
def get_data_loader(dataset, batch_size, mini_batch_size):
# param
train_size = args[dataset]["train_size"]
# load data
inputs = np.load(f"temp/{dataset}.inputs.npy")
graphs = np.load(f"temp/{dataset}.graphs.npy")
weights = np.load(f"temp/{dataset}.weights.npy")
targets = np.load(f"temp/{dataset}.targets.npy")
len_inputs = joblib.load(f"temp/{dataset}.len.inputs.pkl")
len_graphs = joblib.load(f"temp/{dataset}.len.graphs.pkl")
word2vec = np.load(f"temp/{dataset}.word2vec.npy")
# py graph dtype
data = []
for x, edge_index, edge_attr, y, lx, le in tqdm(list(zip(
inputs, graphs, weights, targets, len_inputs, len_graphs))):
x = torch.tensor(x[:lx], dtype=torch.long)
y = torch.tensor(y, dtype=torch.long)
edge_index = torch.tensor([e[:le] for e in edge_index], dtype=torch.long)
edge_attr = torch.tensor(edge_attr[:le], dtype=torch.float)
lens = torch.tensor(lx, dtype=torch.long)
data.append(Data(x=x, y=y, edge_attr=edge_attr, edge_index=edge_index, length=lens))
# split
train_data, test_data, valid_data = split_train_valid_test(data, train_size, valid_part=0.1)
# return loader & word2vec
return [MyDataLoader(data, batch_size=batch_size, mini_batch_size=mini_batch_size)
for data in [train_data, test_data, valid_data]], word2vec
handle_glove.py
import numpy as np
import joblib
def load_data(embedding_dim):
words, vectors = [], []
with open(f"source/glove.6B.{embedding_dim}d.txt", "r", encoding="utf-8") as f:
line = f.readline()
while line != "":
line = line.strip().split()
words.append(line[0])
vectors.append(np.array(line[1:], dtype=np.float))
line = f.readline()
vectors = np.array(vectors)
return words, vectors
if __name__ == '__main__':
for embedding_dim in [50, 100, 200, 300]:
print(embedding_dim)
words, vectors = load_data(embedding_dim)
joblib.dump(words, f"source/glove.6B.words.pkl")
np.save(f"source/glove.6B.{embedding_dim}d.npy", vectors)
model.py
import torch
from torch import nn
from torch.nn.utils.rnn import pad_sequence
from torch_geometric import nn as gnn
class GRUUint(nn.Module):
def __init__(self, hid_dim, act):
super(GRUUint, self).__init__()
self.act = act
self.lin_z0 = nn.Linear(hid_dim, hid_dim)
self.lin_z1 = nn.Linear(hid_dim, hid_dim)
self.lin_r0 = nn.Linear(hid_dim, hid_dim)
self.lin_r1 = nn.Linear(hid_dim, hid_dim)
self.lin_h0 = nn.Linear(hid_dim, hid_dim)
self.lin_h1 = nn.Linear(hid_dim, hid_dim)
self.reset_parameters()
def reset_parameters(self):
for m in self.modules():
if isinstance(m, nn.Linear):
nn.init.xavier_uniform_(m.weight, gain=1)
nn.init.zeros_(m.bias)
def forward(self, x, a):
z = (self.lin_z0(a) + self.lin_z1(x)).sigmoid()
r = (self.lin_r0(a) + self.lin_r1(x)).sigmoid()
h = self.act((self.lin_h0(a) + self.lin_h1(x * r)))
return h * z + x * (1 - z)
class GraphLayer(gnn.MessagePassing):
def __init__(self, in_dim, out_dim, dropout=0.5,
act=torch.relu, bias=False, step=2):
super(GraphLayer, self).__init__(aggr='add')
self.step = step
self.act = act
self.encode = nn.Sequential(
nn.Dropout(dropout),
nn.Linear(in_dim, out_dim, bias=True)
)
self.gru = GRUUint(out_dim, act=act)
self.dropout = nn.Dropout(dropout)
self.reset_parameters()
def reset_parameters(self):
for m in self.modules():
if isinstance(m, nn.Linear):
nn.init.xavier_uniform_(m.weight, gain=1)
nn.init.zeros_(m.bias)
def forward(self, x, g):
x = self.encode(x)
x = self.act(x)
for _ in range(self.step):
a = self.propagate(edge_index=g.edge_index, x=x, edge_attr=self.dropout(g.edge_attr))
x = self.gru(x, a)
x = self.graph2batch(x, g.length)
return x
def message(self, x_j, edge_attr):
return x_j * edge_attr.unsqueeze(-1)
def update(self, inputs):
return inputs
def graph2batch(self, x, length):
x_list = []
for l in length:
x_list.append(x[:l])
x = x[l:]
x = pad_sequence(x_list, batch_first=True)
return x
class ReadoutLayer(nn.Module):
def __init__(self, in_dim, out_dim, dropout=0.5,
act=torch.relu, bias=False):
super(ReadoutLayer, self).__init__()
self.act = act
self.bias = bias
self.att = nn.Linear(in_dim, 1, bias=True)
self.emb = nn.Linear(in_dim, in_dim, bias=True)
self.mlp = nn.Sequential(
nn.Dropout(dropout),
nn.Linear(in_dim, out_dim, bias=True)
)
self.reset_parameters()
def reset_parameters(self):
for m in self.modules():
if isinstance(m, nn.Linear):
nn.init.xavier_uniform_(m.weight, gain=1)
nn.init.zeros_(m.bias)
def forward(self, x, mask):
att = self.att(x).sigmoid()
emb = self.act(self.emb(x))
x = att * emb
x = self.__max(x, mask) + self.__mean(x, mask)
x = self.mlp(x)
return x
def __max(self, x, mask):
return (x + (mask - 1) * 1e9).max(1)[0]
def __mean(self, x, mask):
return (x * mask).sum(1) / mask.sum(1)
class Model(nn.Module):
def __init__(self, num_words, num_classes, in_dim=300, hid_dim=96,
step=2, dropout=0.5, word2vec=None, freeze=True):
super(Model, self).__init__()
if word2vec is None:
self.embed = nn.Embedding(num_words + 1, in_dim, num_words)
else:
self.embed = torch.nn.Embedding.from_pretrained(torch.from_numpy(word2vec).float(), freeze, num_words)
self.gcn = GraphLayer(in_dim, hid_dim, act=torch.tanh, dropout=dropout, step=step)
self.read = ReadoutLayer(hid_dim, num_classes, act=torch.tanh, dropout=dropout)
self.reset_parameters()
def reset_parameters(self):
for m in self.modules():
if isinstance(m, nn.Linear):
nn.init.xavier_uniform_(m.weight, gain=1)
nn.init.zeros_(m.bias)
def forward(self, g):
mask = self.get_mask(g)
x = self.embed(g.x)
x = self.gcn(x, g)
x = self.read(x, mask)
return x
def get_mask(self, g):
mask = pad_sequence([torch.ones(l) for l in g.length], batch_first=True).unsqueeze(-1)
if g.x.is_cuda: mask = mask.cuda()
return mask
prebuild.py
import joblib
from tqdm import tqdm
import scipy.sparse as sp
from collections import Counter
import numpy as np
# 数据集
dataset = "R52"
# 参数
window_size = 1
embedding_dim = 300
max_text_len = 800
# normalize
def normalize_adj(adj):
row_sum = np.array(adj.sum(1))
with np.errstate(divide='ignore'):
d_inv_sqrt = np.power(row_sum, -0.5).flatten()
d_inv_sqrt[np.isinf(d_inv_sqrt)] = 0.
d_mat_inv_sqrt = np.diag(d_inv_sqrt)
adj_normalized = adj.dot(d_mat_inv_sqrt).transpose().dot(d_mat_inv_sqrt)
return adj_normalized
def pad_seq(seq, pad_len):
if len(seq) > pad_len: return seq[:pad_len]
return seq + [0] * (pad_len - len(seq))
if __name__ == '__main__':
# load data
word2index = joblib.load(f"temp/{dataset}.word2index.pkl")
with open(f"temp/{dataset}.texts.remove.txt", "r") as f:
texts = f.read().strip().split("\n")
# bulid graph
inputs = []
graphs = []
for text in tqdm(texts):
words = [word2index[w] for w in text.split()]
words = words[:max_text_len] # 限制最大长度
nodes = list(set(words))
node2index = {e: i for i, e in enumerate(nodes)}
edges = []
for i in range(len(words)):
center = node2index[words[i]]
for j in range(i - window_size, i + window_size + 1):
if i != j and 0 <= j < len(words):
neighbor = node2index[words[j]]
edges.append((center, neighbor))
edge_count = Counter(edges).items()
row = [x for (x, y), c in edge_count]
col = [y for (x, y), c in edge_count]
weight = [c for (x, y), c in edge_count]
adj = sp.csr_matrix((weight, (row, col)), shape=(len(nodes), len(nodes)))
adj_normalized = normalize_adj(adj)
weight_normalized = [adj_normalized[x][y] for (x, y), c in edge_count]
inputs.append(nodes)
graphs.append([row, col, weight_normalized])
len_inputs = [len(e) for e in inputs]
len_graphs = [len(x) for x, y, c in graphs]
# padding input
pad_len_inputs = max(len_inputs)
pad_len_graphs = max(len_graphs)
inputs_pad = [pad_seq(e, pad_len_inputs) for e in tqdm(inputs)]
graphs_pad = [[pad_seq(ee, pad_len_graphs) for ee in e] for e in tqdm(graphs)]
inputs_pad = np.array(inputs_pad)
weights_pad = np.array([c for x, y, c in graphs_pad])
graphs_pad = np.array([[x, y] for x, y, c in graphs_pad])
# word2vec
all_vectors = np.load(f"source/glove.6B.{embedding_dim}d.npy")
all_words = joblib.load(f"source/glove.6B.words.pkl")
all_word2index = {w: i for i, w in enumerate(all_words)}
index2word = {i: w for w, i in word2index.items()}
word_set = [index2word[i] for i in range(len(index2word))]
oov = np.random.normal(-0.1, 0.1, embedding_dim)
word2vec = [all_vectors[all_word2index[w]] if w in all_word2index else oov for w in word_set]
word2vec.append(np.zeros(embedding_dim))
# save
joblib.dump(len_inputs, f"temp/{dataset}.len.inputs.pkl")
joblib.dump(len_graphs, f"temp/{dataset}.len.graphs.pkl")
np.save(f"temp/{dataset}.inputs.npy", inputs_pad)
np.save(f"temp/{dataset}.graphs.npy", graphs_pad)
np.save(f"temp/{dataset}.weights.npy", weights_pad)
np.save(f"temp/{dataset}.word2vec.npy", word2vec)
preprocess.py
import nltk
nltk.download("stopwords")
from nltk.corpus import stopwords
from collections import Counter
import re
import joblib
import numpy as np
dataset = "mr"
# param
stop_words = set(stopwords.words('english'))
least_freq = 5
if dataset == "mr" or "SST" in dataset:
stop_words = set()
least_freq = 0
# func load texts & labels
def load_dataset(dataset):
with open(f"corpus/{dataset}.texts.txt", "r", encoding="latin1") as f:
texts = f.read().strip().split("\n")
with open(f"corpus/{dataset}.labels.txt", "r") as f:
labels = f.read().strip().split("\n")
return texts, labels
def filter_text(text: str):
text = text.lower()
text = re.sub(r"[^A-Za-z0-9(),!?\'`]", " ", text)
text = text.replace("'ll ", " will ")
text = text.replace("'d ", " would ")
text = text.replace("'m ", " am ")
text = text.replace("'s ", " is ")
text = text.replace("'re ", " are ")
text = text.replace("'ve ", " have ")
text = text.replace(" can't ", " can not ")
text = text.replace(" ain't ", " are not ")
text = text.replace("n't ", " not ")
text = text.replace(",", " , ")
text = text.replace("!", " ! ")
text = text.replace("(", " ( ")
text = text.replace(")", " ) ")
text = text.replace("?", " ? ")
text = re.sub(r"\s{2,}", " ", text)
return " ".join(text.strip().split())
if __name__ == '__main__':
texts, labels = load_dataset(dataset)
# handle texts
texts_clean = [filter_text(t) for t in texts]
word2count = Counter([w for t in texts_clean for w in t.split()])
word_count = [[w, c] for w, c in word2count.items() if c >= least_freq and w not in stop_words]
word2index = {w: i for i, (w, c) in enumerate(word_count)}
words_list = [[w for w in t.split() if w in word2index] for t in texts_clean]
texts_remove = [" ".join(ws) for ws in words_list]
# labels 2 targets
label2index = {l: i for i, l in enumerate(set(labels))}
targets = [label2index[l] for l in labels]
# save
with open(f"temp/{dataset}.texts.clean.txt", "w") as f:
f.write("\n".join(texts_clean))
with open(f"temp/{dataset}.texts.remove.txt", "w") as f:
f.write("\n".join(texts_remove))
np.save(f"temp/{dataset}.targets.npy", targets)
joblib.dump(word2index, f"temp/{dataset}.word2index.pkl")
train.py
import time
from sklearn import metrics
from torch import nn
import torch
from config import *
from dataset import get_data_loader
from model import Model
def train_eval(cate, loader, model, optimizer, loss_func, device):
model.train() if cate == "train" else model.eval()
preds, labels, loss_sum = [], [], 0.
for i in range(len(loader)):
loss = torch.tensor(0., requires_grad=True).float().to(device)
for j, graph in enumerate(loader[i]):
graph = graph.to(device)
targets = graph.y
y = model(graph)
loss += loss_func(y, targets)
preds.append(y.max(dim=1)[1].data)
labels.append(targets.data)
loss = loss / len(loader[i])
if cate == "train":
optimizer.zero_grad()
loss.backward()
optimizer.step()
loss_sum += loss.data
preds = torch.cat(preds).tolist()
labels = torch.cat(labels).tolist()
loss = loss_sum / len(loader)
acc = metrics.accuracy_score(labels, preds) * 100
return loss, acc, preds, labels
if __name__ == '__main__':
dataset = "mr"
print("load dataset")
# params
batch_size = 4096 # 反向传播时的batch
mini_batch_size = 64 # 计算时的batch
lr = 0.01
dropout = 0.5
weight_decay = 0.
hid_dim = 96
freeze = True
start = 0
num_classes = args[dataset]['num_classes']
(train_loader, test_loader, valid_loader), word2vec = get_data_loader(dataset, batch_size, mini_batch_size)
num_words = len(word2vec) - 1
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = Model(num_words, num_classes, word2vec=word2vec, hid_dim=hid_dim, freeze=freeze)
loss_func = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=lr, weight_decay=weight_decay)
model = model.to(device)
print("-" * 50)
print(f"params: [start={start}, batch_size={batch_size}, lr={lr}, weight_decay={weight_decay}]")
print("-" * 50)
print(model)
print("-" * 50)
print(dataset)
best_acc = 0.
for epoch in range(start + 1, 300):
t1 = time.time()
train_loss, train_acc, _, _ = train_eval("train", train_loader, model, optimizer, loss_func, device)
valid_loss, valid_acc, _, _ = train_eval("valid", valid_loader, model, optimizer, loss_func, device)
test_loss, test_acc, preds, labels = train_eval("test", test_loader, model, optimizer, loss_func, device)
if best_acc < test_acc:
best_acc = test_acc
cost = time.time() - t1
print((f"epoch={epoch:03d}, cost={cost:.2f}, "
f"train:[{train_loss:.4f}, {train_acc:.2f}%], "
f"valid:[{valid_loss:.4f}, {valid_acc:.2f}%], "
f"test:[{test_loss:.4f}, {test_acc:.2f}%], "
f"best_acc={best_acc:.2f}%"))
print("Test Precision, Recall and F1-Score...")
print(metrics.classification_report(labels, preds, digits=4))
print("Macro average Test Precision, Recall and F1-Score...")
print(metrics.precision_recall_fscore_support(labels, preds, average='macro'))
print("Micro average Test Precision, Recall and F1-Score...")
print(metrics.precision_recall_fscore_support(labels, preds, average='micro'))















 586
586











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









