







1. 测试环境
Matlab
2.代码与原图
girl1=imread('1.jpg');
girl2=imread('2.jpg');
imshow(girl1);
disp('girl1 image size:');
disp(size(girl1));
imshow(girl2);
disp('girl2 image size');
disp(size(girl2));
add1=girl1+girl2;
figure(1),imshow(add1);
add2=girl1./2+girl2./2;
figure(2),imshow(add2);
add3=add1./2;
figure(3),imshow(add3);原图如下:
girl1:

girl2:

3. 结果与分析
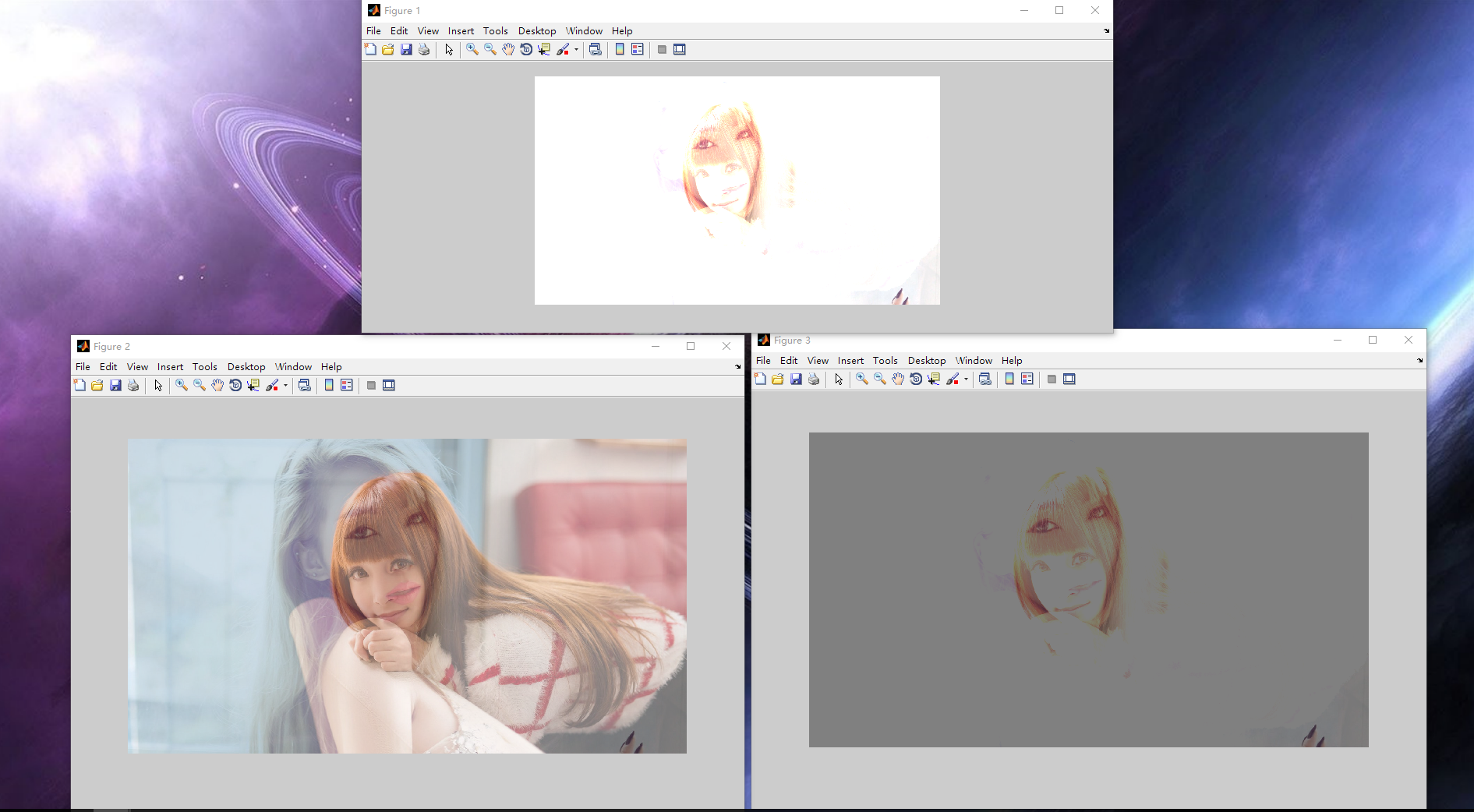
可以看到,只有figure2是我们想要的结果,那么figure1和figure3问题出在哪里呢?
第一张图片很容易理解,直接相加会让像素点的值增大,所以大部分区域趋于白色,
而第三张图片偏暗是怎么回事呢?
举个简单的例子,对应像素点的值分别为200和180,
对于图片二由200/2+180/2=190
对于图片三计算方式为(200+180)/2 但问题在于像素点的取值有范围限制,最大为255,所以实际计算是255/2得到128,比第二张图的值小了很多。














 2233
2233











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









