







我是精神抖擞王大鹏,不卑不亢,和蔼可亲~
计算机硕士,目前小米大数据开发。日常会分享总结一些技术及笔面试题目,欢迎一起讨论。公众号:diting_dapeng
需求
对探探这类软件,每天左滑右滑的,很是浪费时间精力。遂开发工具实现识别匹配类型自动右滑。
解决思路
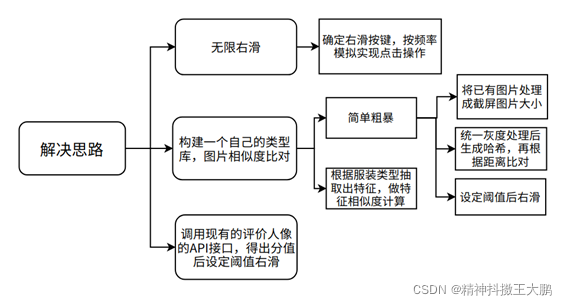
第一种实现思路:比较简单,通过定位像素的xy位置,直接确定右滑的按键,并对其进行点击操作。缺点是无脑匹配,没有选择性;
第二种实现思路:首先需要搜集自己喜欢的类型库,然后有两种方法,一种是直接归一后用距离对比;另一种是抽取出特征,再根据特征来做相似度计算;
第三种实现思路:在对接接口的基础上,对其评分进行选择,如果大于90分,则右滑,否则左滑,目前使用的是腾讯API。缺点是使用速率会不确定。
实现
因为是1.0版本实现,暂时不考虑这么复杂,简易为主。直接上第三种实现思路。
API接口测试
以腾讯API作为接口,先进行下测试:
# -*- coding: utf-8 -*-
'''
编码 : dapeng
日期 : xxxxxxxxx
功能 : 验证腾讯openai的api
环境 :win10+python3.6+opencv3.4+pycharm
'''
import hashlib
import time
import random
import string
import requests
import base64
import requests
import cv2
import numpy as np
from urllib.parse import urlencode
import json #用于post后得到的字符串到字典的转换
app_id = 'xxxxxxx'
app_key = 'xxxxxxxxxx'
'''
腾讯openai鉴权签名计算步骤:(摘抄自官网)
用于计算签名的参数在不同接口之间会有差异,但算法过程固定如下4个步骤。
1 将<key, value>请求参数对按key进行字典升序排序,得到有序的参数对列表N
2 将列表N中的参数对按URL键值对的格式拼接成字符串,得到字符串T(如:key1=value1&key2=value2),URL键值拼接过程value部分需要URL编码,URL编码算法用大写字母,例如%E8,而不是小写%e8
3 将应用密钥以app_key为键名,组成URL键值拼接到字符串T末尾,得到字符串S(如:key1=value1&key2=value2&app_key=密钥)
4 对字符串S进行MD5运算,将得到的MD5值所有字符转换成大写,得到接口请求签名
'''
def get_params(img): #鉴权计算并返回请求参数
#请求时间戳(秒级),用于防止请求重放(保证签名5分钟有效
time_stamp=str(int(time.time()))
#请求随机字符串,用于保证签名不可预测,16代表16位
nonce_str = ''.join(random.sample(string.ascii_letters + string.digits, 16))
params = {'app_id':app_id, #请求包,需要根据不同的任务修改,基本相同
'image':img, #文字类的任务可能是‘text’,由主函数传递进来
'mode':'0' , #身份证件类可能是'card_type'
'time_stamp':time_stamp, #时间戳,都一样
'nonce_str':nonce_str, #随机字符串,都一样
#'sign':'' #签名不参与鉴权计算,只是列出来示意
}
sort_dict= sorted(params.items(), key=lambda item:item[0], reverse = False) #字典排序
sort_dict.append(('app_key',app_key)) #尾部添加appkey
rawtext= urlencode(sort_dict).encode() #urlencod编码
sha = hashlib.md5()
sha.update(rawtext)
md5text= sha.hexdigest().upper() #MD5加密计算
params['sign']=md5text #将签名赋值到sign
return params #返回请求包
def main_Test():
'''
#用python系统读取方法
f = open('c:/girl.jpg','rb')
img = base64.b64encode(f.read()) #得到API可以识别的字符串
'''
#用opencv读入图片
frame=cv2.imread('screen_test_scr.png')
# frame = cv2.imread('1401020019.jpg')
nparry_encode = cv2.imencode('.jpg', frame)[1]
data_encode = np.array(nparry_encode)
img = base64.b64encode(data_encode) #得到API可以识别的字符串
params = get_params(img) #获取鉴权签名并获取请求参数
url = "https://api.ai.qq.com/fcgi-bin/face/face_detectface" # 人脸分析
#检测给定图片(Image)中的所有人脸(Face)的位置和相应的面部属性。位置包括(x, y, w, h),面部属性包括性别(gender), 年龄(age), 表情(expression), 魅力(beauty), 眼镜(glass)和姿态(pitch,roll,yaw)
res = requests.post(url,params).json()
for obj in res['data']['face_list']:
#print(obj)
x=obj['x']
y=obj['y']
w=obj['width']
h=obj['height']
cv2.rectangle(frame,(x,y),(x+w,y+h),(255,255,255),2)
delt=h//5
cv2.putText(frame,'beauty :'+str(obj['gender']), (x+w+10, y+10), cv2.FONT_HERSHEY_SIMPLEX, 0.6, (0, 0, 255), 2,cv2.LINE_8, 0)
cv2.putText(frame,'age :'+str(obj['age']), (x+w+10, y+10+delt*1), cv2.FONT_HERSHEY_SIMPLEX, 0.6, (0, 0, 255), 2,cv2.LINE_8, 0)
cv2.putText(frame,'smile :'+str(obj['expression']), (x+w+10, y+10+delt*2), cv2.FONT_HERSHEY_SIMPLEX, 0.6, (0, 0, 255), 2,cv2.LINE_8, 0)
cv2.putText(frame,'beauty :'+str(obj['beauty']), (x+w+10, y+10+delt*3), cv2.FONT_HERSHEY_SIMPLEX, 0.6, (0, 0, 255), 2,cv2.LINE_8, 0)
cv2.putText(frame,'glass :'+str(obj['glass']), (x+w+10, y+10+delt*4), cv2.FONT_HERSHEY_SIMPLEX, 0.6, (0, 0, 255), 2,cv2.LINE_8, 0)
# print(obj['beauty'])
return obj['beauty']
# cv2.imshow('img',frame)
#cv2.imwrite('./000.jpg',frame)
# cv2.waitKey(0)
if __name__ == '__main__':
main()滑动实现
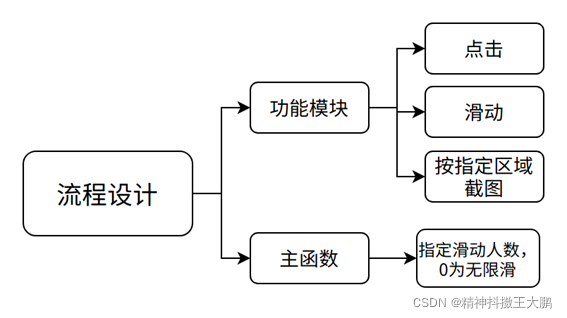
首先需要先来了解下探探滑动的过程(这里是用点击来代替滑动的方式):
- 先由图片点击到主页首图(首图更完整清晰);
- 对首图进行指定区域的截屏;
- 再对截屏的图片进行判断滑动;
- 同时收集右滑的图片作为图片库,作为以后改版本的参考;
程序从主函数入口开始,可以设定指定的人数,如果输入0则表示不限定人数滑动。
# -*- coding: utf-8 -*-
import os
import math
import matplotlib.pyplot as plt
import pytesseract
from PIL import Image
import time
import matplotlib.image as mpimg
import Api_Test
class Tantan_test:
def __init__(self):
self._coefficient = 1.35
self._click_count = 0
self._coords = []
#输出函数
def print_all(self,text):
print(text)
print('\n')
# 图片识别
def img_rec(self,img):
text = pytesseract.image_to_string(Image.open(img), lang='chi_sim')
# print(type(text))
self.print_all(text)
return text
#点击功能
def acquire_info(self,x1,y1):
x1 = str(x1)
y1 = str(y1)
os.system('adb shell input tap ' + x1 + ' ' + y1)
#滑动功能
def acquire_swipe(self,x1,y1,x2,y2):
x1 = str(x1)
y1 = str(y1)
x2 = str(x2)
y2 = str(y2)
os.system('adb shell input swipe ' + x1 + ' ' + y1+' '+x2+' '+y2)
# 截图功能
def cut_info(self,path):
path = str(path)
# screenshot.png.
os.system('adb shell screencap -p /sdcard/'+path)
os.system('adb pull /sdcard/'+path)
# 切分+识别功能
def seg_info(self,x1,y1,x2,y2,path,out_path):
path = str(path)
out_path = str(out_path)
# 此处有不足的情况,截图会覆盖
img = Image.open(path)
region=(x1,y1,x2,y2)
# print(region)
cropImg = img.crop(region)
cropImg.save(out_path)
# text = self.img_rec(out_path)
# return text
# 显示图片功能
def img_show(self,src):
img = Image.open(src)
plt.imshow(img)
plt.show()
def run(self):
self.acquire_info(148.9,734.7)
time.sleep(1)
i = 0
print("请输入人数:输入0表示无限喜欢~~")
max = input("输入多少人:")
max = int(max)
if max==0:
while 1:
self.acquire_info(642,1099)
time.sleep(0.05)
tantan_test.cut_info('screen_test.png')
tantan_test.seg_info(10,82,1056,1125,'screen_test.png','screen_test_scr.png')
# time.sleep(0.05)
# tantan_test.img_show('screen_test.png')
test_beauty = Api_Test.main_Test()
print(test_beauty)
try:
if(test_beauty > 88):
self.acquire_info(941.4,1918)
else:
self.acquire_info(130, 1895)
except:
self.acquire_info(130,1895)
# time.sleep(1)
# self.acquire_info(941.4, 1918)
else:
while i<max:
i = i+1
self.acquire_info(673.488,1823.79)
time.sleep(0.05)
if __name__ == "__main__":
tantan_test = Tantan_test()
tantan_test.run()
# tantan_test.cut_info('screen_test.png')
#tantan_test.img_show('screen_test.png')
#text=pytesseract.image_to_string(Image.open('screen_test.png'),lang='chi_sim')
#print(text)
效果&代码&adb工具
链接:百度网盘 请输入提取码
提取码:1235
最终
tt这种产品当然最终还是靠颜值决定,纯属娱乐使用。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











