







背景
通过百度词条搜索,来查找300个关键词,在一年内发布新闻的条数。
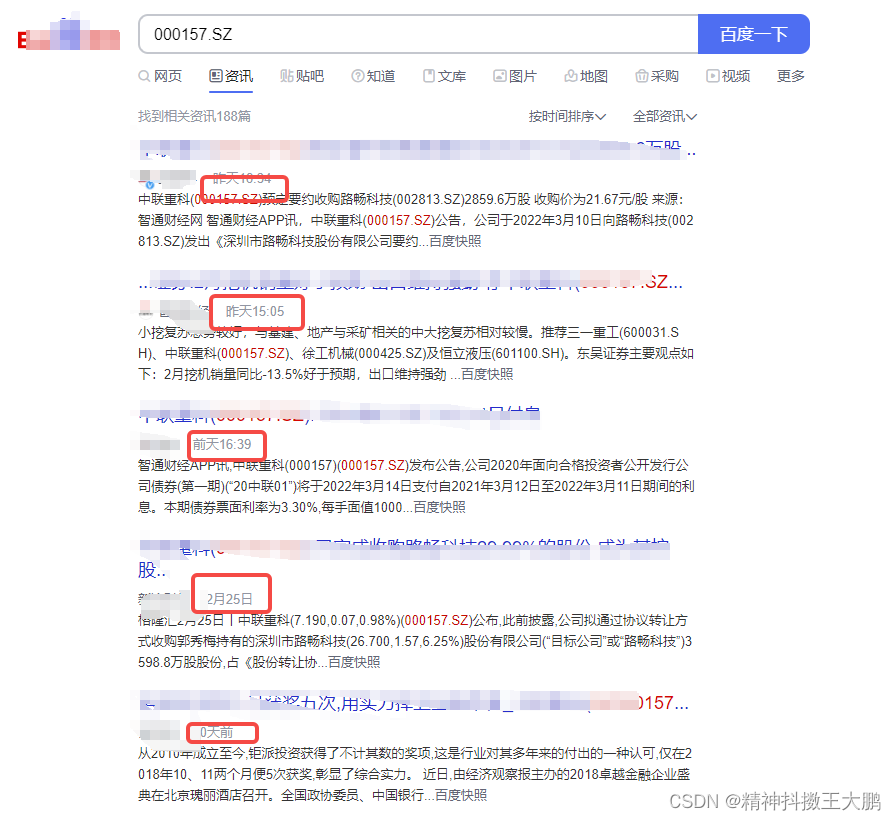
最终效果实现如下:
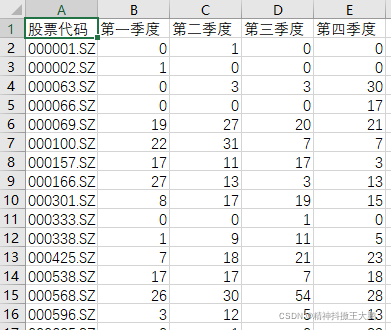
实现思路
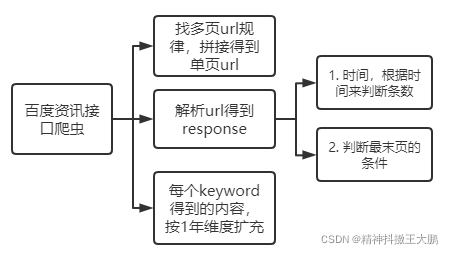
实现思路依然是:
- 先根据多页的url,来找到规律,构建起一页的url;
def format_url(url, params: dict=None) -> str:
query_str = urllib.parse.urlencode(params)
return f'{ url }?{ query_str }'
def get_url(keyword):
# https://www.baidu.com/s?tn=news&rtt=4&bsst=1&cl=2&wd=%E5%B9%B3%E5%AE%89%E9%93%B6%E8%A1%8C&medium=0&x_bfe_rqs=03E80&tngroupname=organic_news&newVideo=12&goods_entry_switch=1&rsv_dl=news_b_pn&pn=0
params = {
'tn': 'news',
'rtt': 4,
'bsst':1,
'cl': 2,
'wd': str(keyword),
'medium': 0,
'x_bfe_rqs': '03E80',
'tngroupname':'organic_news',
'newVideo': 12,
'goods_entry_switch': 1,
'rsv_dl':'news_b_pn'
}
url = "https://www.baidu.com/s"
url = format_url(url, params)
# print(url)
return url
- 对单页的url解析,拿到其时间,按时间做dict求数目。同时注意如何判断最末页的条件。因为这里的末页改变后,页面仍然能响应出内容,因此我的解决方法是每次获取单页的第一条url,如果下一页的url与这条一致,那就属于到最后一页了,退出。
def parse_page(keywords):
res_data = {}
for keyword in keywords:
print(keyword)
flag = 1
page = 0
url = get_url(keyword)
first_page_flag = ''
# 当flag=1时,表示还有页面
time_lis = []
while flag:
url_page = url + f'&pn={page}'
print(url_page)
html = get_page(url_page)
content = etree.HTML(html)
# 取第一个链接
res_href = content.xpath('//*[@id="1"]/div/h3/a/@href')
if first_page_flag == res_href:
print("无更多页面!~")
flag = 0
else:
first_page_flag = res_href
for i in range(1, 11):
title_xpath = f'//*[@id="{str(i)}"]/div/div/div/span[1]/text()'
res_title = content.xpath(title_xpath)
if len(res_title) != 0:
time_lis.append(res_title[0])
page += 10
# print(time_lis)
res_data[keyword] = time_lis
# print(res_data)
print(res_data)
return res_data
- 先生成一年的date,然后拿date去取该日对应的资讯条数。结果如下:
def trans_date(s_date):
# 传入单个字符串,统一
date_list = re.split('[年月日]', s_date)[:-1]
date_list_1 = ['0' + d if len(d) == 1 else d for d in date_list]
date_format = '-'.join(date_list_1)
return date_format
# 时间范围
def templete_date():
# 输出list
start='2020-12-31'
end='2021-12-31'
date_temp = []
datestart=datetime.datetime.strptime(start,'%Y-%m-%d')
dateend=datetime.datetime.strptime(end,'%Y-%m-%d')
while datestart<dateend:
datestart+=datetime.timedelta(days=1)
date_temp.append(datestart.strftime('%Y-%m-%d'))
return date_temp
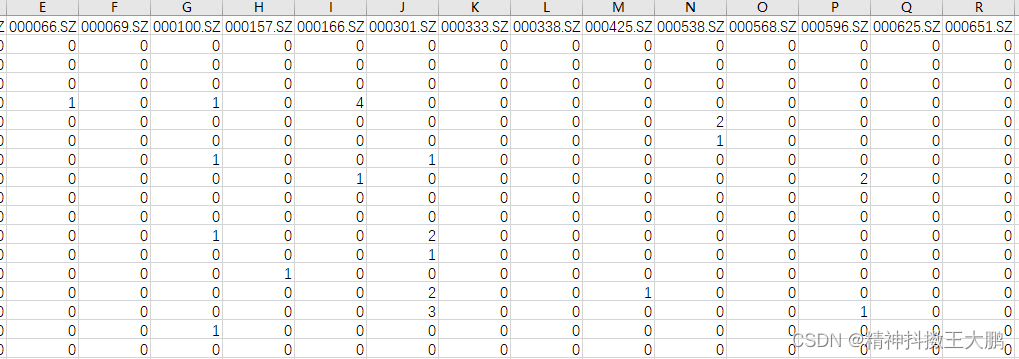
代码
公众号:diting_dapeng
回复"百度资讯"获取源码,欢迎一起学习交流~


















 9637
9637

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











