







0X00 简介
multiprocessing 是一个支持使用与 threading 模块类似的 API 来产生进程的包。 multiprocessing 包同时提供了本地和远程并发操作,通过使用子进程而非线程有效地绕过了 全局解释器锁。 因此,multiprocessing 模块允许程序员充分利用给定机器上的多个处理器。 它在 Unix 和 Windows 上均可运行。
multiprocessing 模块还引入了在 threading 模块中没有的API。一个主要的例子就是 Pool 对象,它提供了一种快捷的方法,赋予函数并行化处理一系列输入值的能力,可以将输入数据分配给不同进程处理(数据并行)。下面的例子演示了在模块中定义此类函数的常见做法,以便子进程可以成功导入该模块。这个数据并行的基本例子使用了 Pool
from multiprocessing import Pool
def f(x):
return x*x
if __name__ == '__main__':
with Pool(5) as p:
print(p.map(f, [1, 2, 3]))0X01 关键方法
https://blog.csdn.net/brucewong0516/article/details/86569707
1.Process
进程类,通过实例化一个Process对象然后调用start方法来启动一个进程
from multiprocessing import Process
import os
def info(title):
print(title)
print('module name:', __name__)
print('parent process:', os.getppid())
print('process id:', os.getpid())
def f(name):
info('function f')
print('hello', name)
if __name__ == '__main__':
info('main line')
p = Process(target=f, args=('bob',))
p.start()
p.join()2.进程启动方法
| 方法名 | |
| spawn | 父进程会启动一个全新的 python 解释器进程。 子进程将只继承那些运行进程对象的 可在Unix和Windows上使用。 Windows上的默认设置。 |
| fork | 父进程使用 只存在于Unix。Unix中的默认值。 |
| forkserver | 程序启动并选择* forkserver * 启动方法时,将启动服务器进程。从那时起,每当需要一个新进程时,父进程就会连接到服务器并请求它分叉一个新进程。分叉服务器进程是单线程的,因此使用 可在Unix平台上使用,支持通过Unix管道传递文件描述符。 |
3.子进程不共享父进程的变量
from multiprocessing import Process
import time
str_list = ['ppp', 'yyy']
def add_str1():
"""子进程1"""
print('In process one: ', str_list)
for x in 'thon':
str_list.append(x * 3)
time.sleep(1)
print('In process one: ', str_list)
def add_str2():
"""子进程1"""
print('In process two: ', str_list)
for x in 'thon':
str_list.append(x)
time.sleep(1)
print('In process two: ', str_list)
if __name__ == '__main__':
p1 = Process(target=add_str1)
p1.start()
p2 = Process(target=add_str2)
p2.start()4.pool.close()和pool.join()
pool.close() 关闭进程池,无法通过该进程池再创建新进程
pool.join() 主进程阻塞等待子进程的退出,该函数可接收timeout参数,如果timeout为None,则将一直阻塞,直到所有子进程退出。如果timeout为正数,则表示最多阻塞N秒
5.多进程写入一个日志文件
https://stackoverflow.com/questions/641420/how-should-i-log-while-using-multiprocessing-in-python
0X02 坑
1.multiprocessing.lock不能被序列化
在使用多进程时,经常会用到锁,例如多进程写一个文件,就需要用锁来保证每次只有一个子进程有写入权限,代码DEMO:
import os
import multiprocessing
import time
def write_file(lock):
print(os.getpid(), os.getppid())
lock.acquire()
with open('./t.log', 'a') as f:
f.write("test")
lock.release()
if __name__ == '__main__':
lock = multiprocessing.Lock()
pool = multiprocessing.Pool(processes=5)
for i in range(5):
handler = pool.apply_async(write_file, (lock, ))
# print(handler.get())
try:
while True:
time.sleep(3600)
continue
except KeyboardInterrupt:
pool.close()
pool.join()代码很简单,创建5个进程写一个文件,使用锁来保证每次只有一个进程可以写入,父进程的lock变量是被子进程共享的,所以可以传递该对象到每个子进程。
但是这个代码将没有任何输出,也不报错,为啥?因为父进程没报错,子进程报错了,你又看不到,所以添加一行代码,获取子进程返回的信息。把注释的print语句取消注释即可,报错如下:
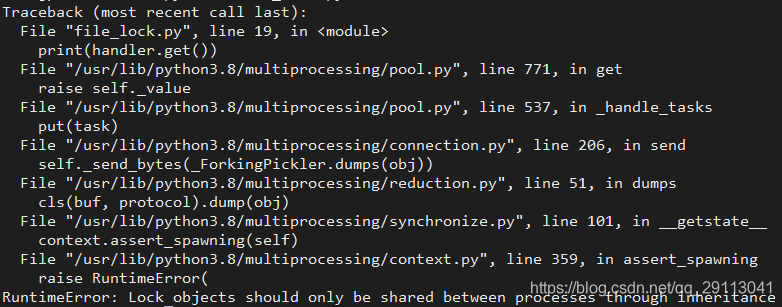
啥意思呢?这个lock对象不能被序列化,所以无法传递。(https://stackoverflow.com/questions/25557686/python-sharing-a-lock-between-processes)
解决方法:
(1)使用manager().lock()
使用该lock会创建一个manager server,锁资源由该server管理,但是消耗比较大,DEMO:
import os
import multiprocessing
import time
def write_file(lock):
print(os.getpid(), os.getppid())
lock.acquire()
with open('./t.log', 'a') as f:
f.write("test")
lock.release()
if __name__ == '__main__':
lock = multiprocessing.Manager().Lock()
pool = multiprocessing.Pool(processes=5)
for i in range(5):
handler = pool.apply_async(write_file, (lock, ))
# print(handler.get())
try:
while True:
time.sleep(3600)
continue
except KeyboardInterrupt:
pool.close()
pool.join()(2)使用pool方法的initializer参数
该方法比较轻量,而且通用。该参数指定了一个函数,所有子进程在调用之前会调用该函数,那么怎么解决我们碰到的问题?DEMO:
import os
import multiprocessing
import time
def write_file():
print(os.getpid(), os.getppid())
lock.acquire()
with open('./t.log', 'a') as f:
f.write("test")
lock.release()
def init_lock(l):
global lock
lock = l
if __name__ == '__main__':
l = multiprocessing.Lock()
pool = multiprocessing.Pool(processes=5, initializer=init_lock, initargs=(l, ))
for i in range(5):
handler = pool.apply_async(write_file)
print(handler.get())
try:
while True:
time.sleep(3600)
continue
except KeyboardInterrupt:
pool.close()
pool.join()通过一个很巧妙的方式规避了lock对象无法反序列化,优秀!
2.不使用pool而是使用Process创建多个进程
import os
import multiprocessing
from multiprocessing import Process
def write_file(l, file_path):
l.acquire()
try:
with open(file_path, 'a') as f:
f.write(str(os.getpid()) + '_' + str(id(l)))
f.write('\n')
finally:
l.release()
if __name__ == '__main__':
l = multiprocessing.Lock()
for num in range(10):
Process(target=write_file, args=(l, './file.txt')).start()同样是创建多个进程,multiprocessing库提供了两种方式,一是1所述的pool方式,二是通过实例化多个Process类,使用Process的args传递全局lock锁给子进程。那么问题来了,为什么传递lock对象给pool就会出现序列化错误,传递给Process就不会?
因为pool方法使用了queue.Queue将task传递给工作进程,所以传递的数据会被序列化然后插入到队列中。而lock是一个对象,并不是str类型,对象无法插入到队列中,所以会报错。而使用Process的话,将lock对象传递给子进程是没有问题,因为lock对象不需要被序列化,直接传递lock对象的地址即可,输出的日志也可以看到,所有子进程获取到的lock对象的内存地址是一致的。
0X03 题外话
1.多线程 or 多进程写入同一文件并不会出现格式错乱
在实际使用过程中,我发现不管是使用多线程还是多进程同时写入一个文件,都不会造成文件的格式错乱,似乎所有的写入操作都是原子操作("原子操作(atomic operation)是不需要synchronized",这是多线程(or进程)编程的老生常谈了。所谓原子操作是指不会被线程调度机制打断的操作;这种操作一旦开始,就一直运行到结束,中间不会有任何 context switch,处理器会自动保证基本的内存操作的原子性。处理器保证从系统内存当中读取或者写入一个字节是原子的,意思是当一个处理器读取一个字节时,其他处理器不能访问这个字节的内存地址。)
这就很奇怪了,让我一度怀疑对于写文件操作是否需要加锁?同事的代码使用80个进程并行写入一个日志文件,运行了几年也从没出现异常。我开始怀疑with语句这个上下文管理器是否内置了锁,当一个进程拿到了文件描述符后就不会让另一个进程获取,后来咨询了大神后,得到的结论是上下文管理器并不会帮用户实现锁,而在Linux下之所以多线程 or 多进程写入同一个文件没有出现异常是因为系统的一些机制:
在POSIX上,管道不可搜索并且没有文件位置,因此附加是唯一可能的写入方式。当写入管道(或FIFO)时,PIPE_BUF保证小于系统定义的写入是原子的和非交织的。
PIPE_BUF字节或更少字节的写请求不得与来自在同一管道上进行写操作的其他进程的数据交织。大于PIPE_BUF字节的写入可能会在任意边界与其他进程的写入对数据进行交织,[…]
PIPE_BUFPOSIX系统的最小值是512个字节。在Linux上为4kB,在其他系统上为32kB。只要每条记录小于512字节,就会执行一次简单的write(2)。这都不依赖于文件系统,因为不涉及任何文件。
如果超过PIPE_BUF字节是不够的,POSIX writev可以获得(2)可用于原子地写入到IOV_MAX缓冲器的 PIPE_BUF字节。最小值为IOV_MAX16,但通常为1024。这意味着,对于完美可移植的程序,管道的最大安全原子写大小(因此,最大记录大小)为8kB(16✕512)。在Linux上为4MB。(https://nullprogram.com/blog/2016/08/03/)
综上所述,对于多线程 or 多进程同时写文件的操作,最好的方式还是加锁或者使用队列,在用户态对写入操作进行控制,这是万无一失的方式。

















 3157
3157

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









