







平时工作中,会经常遇到重复的文件,如果手动清理的话,则会在查找和识别上耗费大量的时间,今天用 Python 做一些 Windows 电脑上重复文件的清理操作。有时候,目录下可能会存在许多名称不同、而内容相同的文件,时间久了不去清理则会造成磁盘空间的浪费。
使用 Python 实现指定目录下的重复文件清理(这里,把清理的文件移动到备份目录,而不是直接删除),大致思路如下:
- 检查备份目录是否存在,不存在则创建备份目录;
- 读取源目录,并找出所有的文件,包含子目录里的文件;
- 对文件进行两两比对,如果文件的内容相同,则移动到备份目录保存;
代码实现,如下:
from pathlib import Path
from filecmp import cmp
def clear_repeat_files(scrPath, descPath):
# 创建备份路径
if not descPath.exists():
descPath.mkdir(parents=True)
# 从scrPath路径下查找文件,包含嵌套的子目录查找
file_list = []
for file in list(scrPath.rglob("*")):
if file.is_file():
file_list.append(file)
# 遍历文件,并两两比对
for i in file_list:
for j in file_list:
if i != j and i.exists() and j.exists():
if cmp(i, j):
# i.unlink()
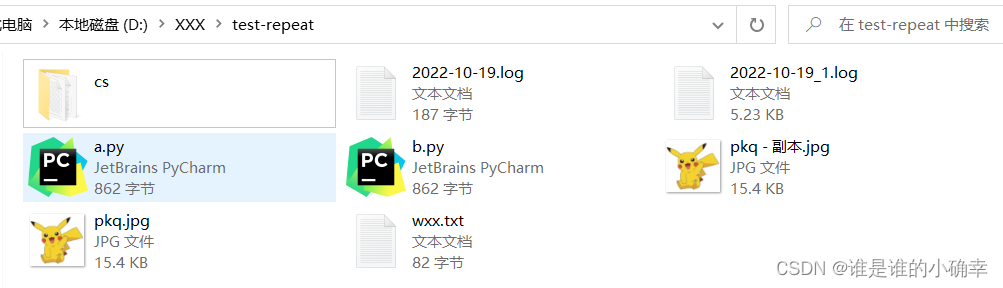
i.replace(descPath / i.name)为了更能体现实用性,并支持识别不同子目录下的重复文件,测试的文件有不同的类型,如下:
- a.py 和 b.py 是相同的文件;
- pkq..jpg 和 pkq - 副本.jpg 是相同的图片;
- wxx.txt 和 ./cs/wxx -1.txt 是相同的文件;
- 2022-10-19_1.log 和 ./cs/2022-10-19_2.log 是相同的文件;
测试代码,如下:
if __name__ == '__main__':
path = input('请输入清理重复文件的目录:')
if len(path.strip()) == 0:
path = "D:\\XXX\\test-repeat\\"
scrPath = Path(path)
descPath = Path(path + "repeat\\")
clear_repeat_files(scrPath, descPath)执行后,效果如下:
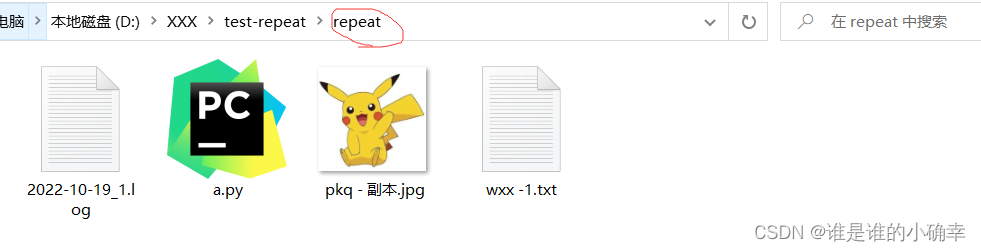
重复文件查找的效果还不错!通过循环查找,指定目录下无论存在多少子目录,都可以进行匹配到重复文件了。如果直接删除重复文件的话,只需要把 replace() 替换成 unlink() 即可。另外,路径对象的 glob() 和 rglob() 都能使用通配符在指定路径下查找文件和子文件夹,两者区别在于,glob() 只进行一级查找,而 rglob() 会进行多级查找。
清理重复文件是办公过程中经常遇到的一种场景,然而满足个性化的需求才是最难的。
比如,我想删除一个文件,但忘了在电脑哪个目录位置,这是不是很尴尬!要删除这个文件,首先肯定要先找到它,我们知道 Windows 的搜索框在键入关键字后搜索,会扫描磁盘上的所有文件,当匹配到目标关键字后则会显示出来。别急,这种最基本的文件和目录搜索操作,使用 Python 也可以轻松实现。
代码实现,如下:
from pathlib import Path
import time
import psutil
keyword = input("请输入查询的文件:")
result_files = []
result_dirs = []
start_time = time.perf_counter()
# 获取电脑磁盘各个盘符,['C:\\', 'D:\\', 'E:\\', 'F:\\']
src_dirs = []
for disk in psutil.disk_partitions():
src_dirs.append(disk.device)
for current_dir in src_dirs:
result = list(Path(current_dir.strip()).rglob(f'*{keyword}*'))
if len(result) > 0:
for i in result:
print(f'file : {i}')
if i.is_file():
result_files.append(i)
else:
result_dirs.append(i)
# 不存在
if len(result_dirs) == 0 and len(result_files) == 0:
print('对不起,你搜索的 {keyword} 不存在!')
print('-------------------------------')
print(f'匹配到:{len(result_dirs) + len(result_files)}条记录')
print(f'耗时:{time.perf_counter() - start_time}s')例如,搜索 demo 关键字的文件或目录,测试效果,如下:

此外,Python 还可以在此基础上扩展一些其他功能,比如,标记出大小超过xxx的文件(为清理这类的大文件提供参考):
新增如下代码即可:
print('--------------*readme*-----------------')
for j in result_files:
# 单位为字节
if os.path.getsize(j) > 1024*1024:
print(f'{j} 大小为:{os.path.getsize(j)} 字节')又比如,指定搜索的文件后缀类型,而不是对全部类型搜索:
新增如下代码即可:
print('--------------*readme*-----------------')
for j in result_files:
j_name = os.path.split(j)[1]
if j_name.endswith(".txt"):
print(f'匹配到的txt文件:{j}')不难发现,匹配到结果还挺耗时的,其实,为了加快查找速度,我们还可以加一层本地缓存实现。
思路是用已经搜索过的关键字作为 key,把最新搜索时间和最新搜索到的列表结果组成另一个 Map 作为 value,当下次再进行该关键字的查询时,先判断 key 中是否存在该关键字,存在的话不再进行全盘扫描,否则去查找全盘文件,并把最新搜索时间和最新搜索的列表结果更新到 value。当然,该本地缓存还可以设置过期时间(比如24h),比如取到该 key 时,发现 value 最新搜索时间超过了24h,那就不会取该 value 的列表结果,而是去查找全盘文件,搜索完毕后更新 value 的最新搜索时间和最新搜索的列表结果。
当然,对于首次搜索或 key 过期是没有什么作用的,加快查找速度还可以考虑使用多线程,后面有时间再研究研究。















 313
313











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









