






1.用到的主要方法
创建图层
arcpy.CreateFeatureclass_management(in_table, feature_name, geometry_type = feature_type)
参数分别是gdb数据库路径,图层名称,几何类型
创建字段
arcpy.AddField_management(featurename_all, field_name, field_type, field_length = fieldlength, field_alias = fieldalias, field_is_nullable = fieldnullable)
参数分别是图层完整路径,字段名,字段类型,字段长度,字段别名,字段是否允许空值
这里需要注意下,在gdb里面FLOAT,DOUBLE等类型无法定义精度和小数位数
2.数据库图层和字段定义表
先在Excel里面创建两个表,图层定义表和字段定义表,表结构如下
图层定义表
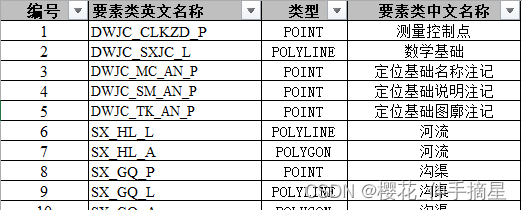
字段定义表
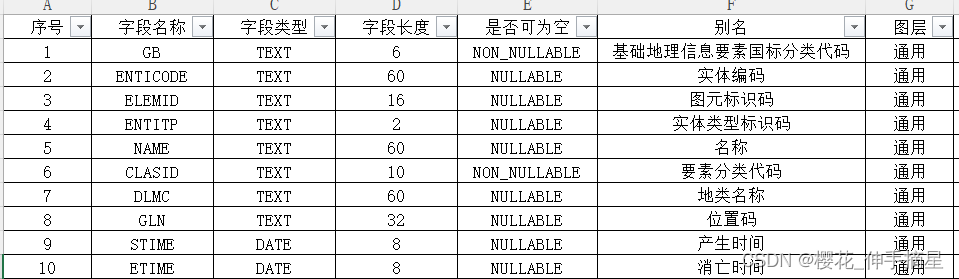
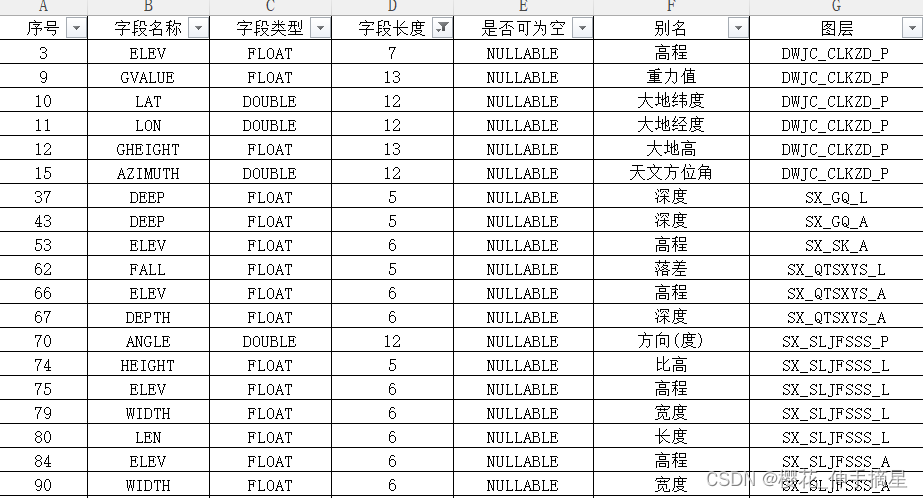
这里字段定义用了两张表来表示图层的通用字段和特有字段
3.arcpy代码
# -*- coding:utf-8 -*-
import sys
reload(sys)
sys.setdefaultencoding("utf-8")
# 导入读取excel的模块(在cmd中用pip install xlrd安装对应模块)
import xlrd
import xlwt
# 导入arcgis工具模块arcpy
import arcpy
# 设置参数(pthon脚本导入arcgis中的两个参数)
in_table = arcpy.GetParameterAsText(0) #原文件位置
xlspath = arcpy.GetParameterAsText(1) #标准化后图层结构表excel格式路径
xlspath_att = arcpy.GetParameterAsText(2) #标准化后属性结构表excel格式路径
#in_table = r"F:\2023\gdbbuild\new.gdb" #原文件位置
#xlspath = r"F:\2023\gdbbuild\mb_std_layer.xlsx" #标准化后图层结构表excel格式路径
#xlspath_att = r"F:\2023\gdbbuild\mb_std_table.xlsx" #标准化后属性结构表excel格式路径
#注意事项:excel表格注意字符串前面和后面的空格要去掉,mdb格式可能报错,前面7列不能有空着的地方
data = xlrd.open_workbook(xlspath)
layer_list = []
# 取excel第一个sheet
table = data.sheets()[0]
# for循环遍历每一行
for i in range(1,table.nrows):
row_content = [] # 初始化一个列表,用于后面存储读取的excel值
for j in range(table.ncols): # 遍历excel每行中的各个值
ctype = table.cell(i, j).ctype # 定义每个值类型用于下面判断
cell = table.cell_value(i, j) # 定义每个值用于下面判断
if ctype == 1:
row_content.append(cell.strip()) # 如果值类型为字符型,将值加入让面的列表,处理空格
if ctype ==2 and cell%1 == 0:
cell = int(cell) # 如果值类型为浮点型,且除以1余数为0,转为整数
row_content.append(cell) # 加入列表
layer_list.append(str(row_content[1]))
# 将参数赋值给AddField工具所需的必要参数
feature_name = str(row_content[1]) # 字段名:该行的第二个(列表索引从0开始)
feature_type = str(row_content[2]) # 字段类型:该行第三个
arcpy.CreateFeatureclass_management(in_table, feature_name, geometry_type = feature_type)
print feature_name
arcpy.AddMessage(feature_name)
print "图层创建完成"
arcpy.AddMessage("图层创建完成")
data_att = xlrd.open_workbook(xlspath_att)
#print data_att
print "通用字段开始添加"
arcpy.AddMessage("通用字段开始添加")
# 通用字段处理
table_allatt = data_att.sheets()[0]
for i in range(1,table_allatt.nrows):
row_content_att = [] # 初始化一个列表,用于后面存储读取的excel值
for j in range(table_allatt.ncols): # 遍历excel每行中的各个值
ctype = table_allatt.cell(i, j).ctype # 定义每个值类型用于下面判断
cell = table_allatt.cell_value(i, j) # 定义每个值用于下面判断
if ctype == 1:
row_content_att.append(cell.strip()) # 如果值类型为字符型,将值加入让面的列表,处理空格
if ctype ==2 and cell%1 == 0:
cell = int(cell) # 如果值类型为浮点型,且除以1余数为0,转为整数
row_content_att.append(cell) # 加入列表
# 将参数赋值给AddField工具所需的必要参数
field_name = str(row_content_att[1]) # 字段名:该行的第二个(列表索引从0开始)
field_type = str(row_content_att[2]) # 字段类型:该行第三个
fieldalias = str(row_content_att[5])
fieldnullable = str(row_content_att[4])
#featurename = str(row_content_att[6])
print field_name
arcpy.AddMessage(field_name)
for item in layer_list:
featurename_all = in_table + '/' + item
if field_type == 'DOUBLE': # 如果字段类型为FLOAT,执行下面代码,其他elif同理
fieldscale = row_content_att[3] # 小数位数,该行第五个
arcpy.AddField_management(featurename_all, field_name, field_type,"", "", "",field_alias = fieldalias, field_is_nullable = fieldnullable)
elif field_type == 'TEXT':
fieldlength = row_content_att[3]
arcpy.AddField_management(featurename_all, field_name, field_type, field_length = fieldlength, field_alias = fieldalias, field_is_nullable = fieldnullable)
elif field_type == 'SHORT':
fieldprecision = row_content_att[3]
arcpy.AddField_management(featurename_all, field_name, field_type, field_precision = fieldprecision, field_alias = fieldalias, field_is_nullable = fieldnullable)
elif field_type == 'LONG':
fieldprecision = row_content_att[3]
arcpy.AddField_management(featurename_all, field_name, field_type, field_precision = fieldprecision, field_alias = fieldalias, field_is_nullable = fieldnullable)
elif field_type == 'FLOAT':
fieldprecision = row_content_att[3]
arcpy.AddField_management(featurename_all, field_name, field_type, field_precision = fieldprecision, field_alias = fieldalias, field_is_nullable = fieldnullable)
elif field_type == 'DATE':
fieldprecision = row_content_att[3]
arcpy.AddField_management(featurename_all, field_name, field_type, field_alias = fieldalias, field_is_nullable = fieldnullable)
else :
print "字段类型不符"
arcpy.AddMessage("字段类型不符")
print "通用字段添加完成"
arcpy.AddMessage("通用字段添加完成")
# 取excel第一个sheet
table_att = data_att.sheets()[1]
#print table_att.nrows
# for循环遍历每一行
for i in range(1,table_att.nrows):
row_content_att = [] # 初始化一个列表,用于后面存储读取的excel值
for j in range(table_att.ncols): # 遍历excel每行中的各个值
ctype = table_att.cell(i, j).ctype # 定义每个值类型用于下面判断
cell = table_att.cell_value(i, j) # 定义每个值用于下面判断
if ctype == 1:
row_content_att.append(cell.strip()) # 如果值类型为字符型,将值加入让面的列表,处理空格
if ctype ==2 and cell%1 == 0:
cell = int(cell) # 如果值类型为浮点型,且除以1余数为0,转为整数
row_content_att.append(cell) # 加入列表
# 将参数赋值给AddField工具所需的必要参数
field_name = str(row_content_att[1]) # 字段名:该行的第二个(列表索引从0开始)
field_type = str(row_content_att[2]) # 字段类型:该行第三个
fieldalias = str(row_content_att[5])
fieldnullable = str(row_content_att[4])
featurename = str(row_content_att[6])
featurename_all = in_table + '/' + featurename
if featurename in layer_list :
print field_name
arcpy.AddMessage(field_name)
if field_type == 'DOUBLE': # 如果字段类型为FLOAT,执行下面代码,其他elif同理
fieldscale = row_content_att[3] # 小数位数,该行第五个
arcpy.AddField_management(featurename_all, field_name, field_type,"", "", "",field_alias = fieldalias, field_is_nullable = fieldnullable)
elif field_type == 'TEXT':
fieldlength = row_content_att[3]
arcpy.AddField_management(featurename_all, field_name, field_type, field_length = fieldlength, field_alias = fieldalias, field_is_nullable = fieldnullable)
elif field_type == 'SHORT':
fieldprecision = row_content_att[3]
arcpy.AddField_management(featurename_all, field_name, field_type, field_precision = fieldprecision, field_alias = fieldalias, field_is_nullable = fieldnullable)
elif field_type == 'LONG':
fieldprecision = row_content_att[3]
arcpy.AddField_management(featurename_all, field_name, field_type, field_precision = fieldprecision, field_alias = fieldalias, field_is_nullable = fieldnullable)
elif field_type == 'FLOAT':
fieldprecision = row_content_att[3]
arcpy.AddField_management(featurename_all, field_name, field_type, field_precision = fieldprecision, field_alias = fieldalias, field_is_nullable = fieldnullable)
elif field_type == 'DATE':
fieldprecision = row_content_att[3]
arcpy.AddField_management(featurename_all, field_name, field_type, field_alias = fieldalias, field_is_nullable = fieldnullable)
else :
print "字段类型不符"
arcpy.AddMessage("字段类型不符")
print "建库完成"
arcpy.AddMessage("建库完成")
















 8214
8214

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









