






备份恢复:gcrcman ,不压缩,主备分片同时备份
跨集群备份恢复:
gcrcman跨集群备份恢复与ip地址无关,恢复时集群的拓扑结构相同,包括管理节点、数据节点,数据的 distribution id可不一致。并且备份需拷贝到与源集群对应的目标节点。
RTO:容灾系统在灾难发生后数据或者系统恢复所用的时间
RPO:灾难发生时,已经备份的数据和生产中心的数据时间差
备份恢复脚本
集群的备份、恢复工具随集群的安装自动安装,该工具被安装在安装目录$GCLUSTER_BASE/server/bin 下。一次全量备份开启一个新的周期。一次增量备份则续写最后一个备份周期,使其增加一个备份点。
gcrcman功能:
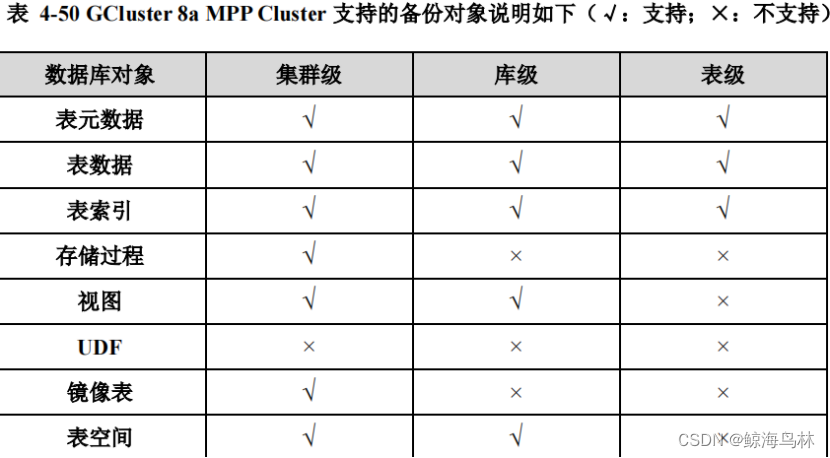
1.集群级全量备份:将当前集群的数据全量备份至指定的备份目录中(确保已经创建好目录)。
2.集群级增量备份:在指定备份目录中的全量或增量备份数据的基础上,将当前集群的数据增量备份至该备份目录。
3.库级全量备份:备份某个库下所有的表和普通视图。
4.库级增量备份:增量备份某个库下所有的表。
5.表级全量备份:将某一个表的数据全量备份至备份目录中。
6.表级增量备份:将某一个表的数据增量备份至备份目录中。
7.集群级恢复:将备份目录中的指定备份数据,恢复至当前的集群中。
8.库级恢复:恢复一个库下所有的表和普通视图。
9.表级恢复:将备份目录中的单个表的数据,恢复至当前数据库中。
10.查看备份数据:数据备份后,查看已经备份了哪些数据。
11.删除备份数据:删除用户指定的备份数据。
12.删除垃圾数据:由于异常或者用户中断,残留的垃圾备份数据,用户可以通过工具删除。
注意:
1.执行 gcrcman.py 命令时,必须是安装数据库时指定的 dbauser。
2.需要在 coordinator 节点上执行备份恢复操作,执行备份恢复操作时集群各节点网络连接正常。
3.执行 gcrcman.py 命令,需要确定操作系统已安装 pexpect 包。
4.在执行备份恢复的过程中,集群的各个节点上,必须都存在 gcrcman.py 中参数 path 指定的路径,集群安装用户 dbauser 用户对该路径具备读写操作权限,且在执行过程中该目录一直存在。
5.不要将$GCLUSTER_BASE、$GBASE_BASE、$GCWARE_BASE 这三个目录及其子目录设置为 path 的路径。
6.在执行备份恢复的过程中,操作系统和数据库用户的密码不能更改。
7.执行备份恢复操作时,恢复时需要和备份时集群的拓扑结构相同,包括管理节点、数据节点。
8.无论是多个会话连接,还是一个会话连接,每次只能运行一个 gcrcman.py 程序。
9.暂不支持单个 VC 的数据备份恢复。
10.各节点运行正常,没有 offline 节点,没有 event 事件日志,没有CLOSED服务等异常情况
注意:
1.在进行备份时需要集群各项状态正常。
2.由于 gcrcman 需要与 gcware 有交互,因此,需要在安装 gcware 服务的Coordinator 上执行备份操作。
3.集群拓扑结构不能发生改变。拓扑结构包括 Coordinator 节点,Data 节点,distribution,distribution 的各个 segment 与 datanode 的对应关系。
4.备份时,由于 gcrcman 工具运行节点获取当前时间作为备份点的备份时间,因此集群务必保持各节点时间一致,才能保证在不同节点上进行持续备份。
5.实例级备份时,需要使用集群安装用户 dbauser(默认 gbase),执行 gcadmin switchmode readonly,将集群设置为只读状态,备份完毕后,执行 gcadmin switchmode normal,将集群恢复为正常状态。
6.备份时,程序连同数据库中所有的用户和密码同时备份,因此恢复时,也是备份时的用户和密码,因此建议客户,备份前记录好集群中默认的 root用户和 gbase 用户的密码,以免恢复时忘记。
7.当集群进行了扩容或者缩容操作时,集群的结构会发生变化。因此,原先的备份记录将会失效,无法完成恢复操作。正确的做法是在集群扩容、缩容后,进行新的备份操作,这样就可以通过备份记录进行数据恢复。
8.当备份时数据是使用密钥进行加密过,还需要保存好密钥,在恢复数据时,解密过程需要用到原始密钥
备份恢复性能基本上能达到磁盘的读写性能的最高值,备份恢复执行的时候,磁盘读写是将近100%
备份命令:
python $GCLUSTER_BASE/server/bin/ gcrcman.py [options] <-d|--path BACKUP_PATH>
参数名称
说明
-h,--help
用于显示命令参数的帮助信息
参数名称
说 明
-V,--version 用于显示 gcrcman 的版本信息
-d BACKUP_PATH, --path=BACKUP_PATH /*用于设定备份数据的存放路径。该路径必须是绝对路径,路径中支持“~”的使用,在每个节点下面都要有 path 参数指定的路径,且该路径要求有写权限。不能将$GCLUSTER_BASE 或者 $GBASE_BASE */或者$GCWARE_BASE 这三个目录及子目录设置为 path 的路径。
-e COMMAND,--execute=COMMAND 指定要执行的备份或恢复命令,执行完自动退出。具体命令参考表。当使用-e 这种简称参数时,建议-e 和后面的参数之间使用一个空格,提高可读性。
-P HOST_PASSWD,--ospassword=HOST_PASSWD 指定数据库管理员的操作系统用户密码。默认是 gbase 用户,不可指定,此处填写操作系统用户 gbase 的密码。
-p DATABASE_PASSWD,--dbpassword=DATABASE_PASSWD 指定数据库管理员的数据库用户密码。备份恢复工具有些操作需要访问数据库,因此需要指定数据库用户密码。数据库用户默认是 gbase,不可指定。
-r PARALLEL_LEVEL,--parallel=PARALLEL_LEVEL 用于设置备份恢复工具执行的并行度,取值范围为[1,128],默认值为 4。
-D,--disk_space_estimate 用于设定是否进行空间预估,有此参数则不进行空间预估。默认不使用此参数,即在备份时进行空间预估。不进行空间预估,预计减少百分之20备份时间。
-c,--checksum_database 用于设定是否进行数据的校验,有此参数则不进行 DC 的checksum 校验。默认不使用此参数,即在备份时进行数据校验。
-C,--checksum_backup_data 用于设定是否进行备份数据的校验。默认不使用此参数,即进行备份数据的校验。
-t SECOND,--timeout=SECOND 用于设定等待读、写事务的时长,备份时需要等待集群中没有写事务,恢复备份数据时,需要等待集群中没有读和写事务,才可进行后面的操作。该参数单位为秒,取值范围为[0,3600],不指定该参数则默认值为 300 秒。如果超时,则报错退出,表示此次备份或恢复失败。参数值为 0,表示无限等待
backup or recover commands:
1.show backup show backup data
2.backup level <0|1> backup instance
3.backup database [vcname.]<dbname> level <0|1> backup single database /*设置备份级别,0 表示全备,1 表示增备。*/
4.backup table [vcname.]<dbname.tablename> level <0|1> backup single table
5.recover [<cycle_id> [point_id]] recover instance
6.recover database [vcname.]<dbname> [<cycle_id> [point_id]] recover single database cycle_id 最新的备份点 point_Id 指定备份点
7.recover [force] table [vcname.]<dbname.tablename> [<cycle_id> [point_id]] recover single table
8.delete <cycle_id | last> delete backup data
9.cleanup clean invalid backup data
10.quit exit
11.help show help info
1.集群备份恢复:(交互模式)
集群级别备份:
1).切换集群模式为readonly
[gbase@gbaseman GclusterData_coordinator1_node2]$ gcadmin switchmode readonly
========== switch cluster mode...
switch pre mode: [NORMAL]
switch mode to [READONLY]
switch after mode: [READONLY]
2).数据全备份
gcrcman>backup level 0
12.04 21:36:33 BackUp start
--------------------------------------------
12.04 21:36:33 node (192.168.18.11) backup begin
12.04 21:36:33 node (192.168.18.13) backup begin
12.04 21:36:33 node (192.168.18.14) backup begin
12.04 21:37:00 node (192.168.18.11) backup success
12.04 21:37:00 node (192.168.18.13) backup success
12.04 21:37:00 node (192.168.18.14) backup success
--------------------------------------------
12.04 21:37:01 BackUp end
3).切换模式为normal
[gbase@gbaseman GclusterData_coordinator1_node2]$ gcadmin switchmode normal
========== switch cluster mode...
switch pre mode: [READONLY]
switch mode to [NORMAL]
switch after mode: [NORMAL]
集群恢复:
1).切换模式为recovery
[gbase@gbaseman metadata]$ gcadmin switchmode recovery
========== switch cluster mode...
switch pre mode: [NORMAL]
switch mode to [RECOVERY]
switch after mode: [RECOVERY]
2).恢复到指定备份点
gcrcman>recover 0 1
12.04 22:01:39 check cluster topology begin
12.04 22:01:39 node (192.168.18.11) check topology begin
12.04 22:01:40 node (192.168.18.11) check topology success
12.04 22:01:40 check cluster topology end
12.04 22:01:40 check BackUp start
--------------------------------------------
12.04 22:01:40 node (192.168.18.11) check backup begin
12.04 22:01:40 node (192.168.18.13) check backup begin
12.04 22:01:41 node (192.168.18.14) check backup begin
^[[5~12.04 22:01:58 node (192.168.18.11) check backup success
12.04 22:01:58 node (192.168.18.13) check backup success
12.04 22:01:58 node (192.168.18.14) check backup success
--------------------------------------------
12.04 22:01:58 check BackUp success
12.04 22:01:58 Recover start
--------------------------------------------
12.04 22:01:59 node (192.168.18.11) Recover begin
12.04 22:01:59 node (192.168.18.13) Recover begin
12.04 22:01:59 node (192.168.18.14) Recover begin
12.04 22:02:12 node (192.168.18.11) Recover success
12.04 22:02:12 node (192.168.18.13) Recover success
12.04 22:02:12 node (192.168.18.14) Recover success
--------------------------------------------
12.04 22:02:13 Recover success
3).恢复到normal模式
[gbase@gbaseman metadata]$ gcadmin switchmode normal
========== switch cluster mode...
switch pre mode: [RECOVERY]
switch mode to [NORMAL]
switch after mode: [NORMAL]
报错
gbase> select * from t1;
ERROR 1149 (42000): (GBA-02SC-1001) Can't get distribution attribute of table test.t1, please check your gbase.table_distribution.
4).重启gcluster服务或重启集群
[gbase@gbaseman ~]$ gcluster_services gcluster restart
测试
gbase> select count(*) from test.t_user;
+----------+
| count(*) |
+----------+
| 10335 |
+----------+
1 row in set (Elapsed: 00:00:00.01)
数据库级别备份恢复
不需要设置readonly,但是会给备份库加锁,恢复需要删除原数据库,不然报错
备份:
1).备份test库
[gbase@gbaseman bin]$ python gcrcman.py -d /opt/backdatabase -P gbase@123 -p gbase@123
gcrcman>backup database test level 0
12.04 23:54:19 BackUp database test start
--------------------------------------------
12.04 23:54:19 node (192.168.18.11) backup database begin
12.04 23:54:19 node (192.168.18.13) backup database begin
12.04 23:54:19 node (192.168.18.14) backup database begin
12.04 23:54:41 node (192.168.18.11) backup database success
12.04 23:54:41 node (192.168.18.13) backup database success
12.04 23:54:41 node (192.168.18.14) backup database success
--------------------------------------------
12.04 23:54:41 BackUp database test end
恢复test库
1),恢复test库
gcrcman>show backup
cyclepointleveltime
0002022-12-04 23:54:19
1002022-12-05 00:02:38
2002022-12-05 00:03:28
gcrcman>recover database test 2
恢复数据库
12.05 00:04:44 check database BackUp start
--------------------------------------------
12.05 00:04:44 node (192.168.18.11) check database backup begin
12.05 00:04:44 node (192.168.18.13) check database backup begin
12.05 00:04:44 node (192.168.18.14) check database backup begin
12.05 00:04:55 node (192.168.18.11) check database backup success
12.05 00:04:55 node (192.168.18.13) check database backup success
12.05 00:04:55 node (192.168.18.14) check database backup success
--------------------------------------------
12.05 00:04:55 check database BackUp success
12.05 00:04:55 recover prepare start
--------------------------------------------
12.05 00:04:55 node (192.168.18.11) recover prepare begin
12.05 00:04:55 node (192.168.18.13) recover prepare begin
12.05 00:04:55 node (192.168.18.14) recover prepare begin
12.05 00:04:57 node (192.168.18.11) recover prepare success
12.05 00:04:57 node (192.168.18.13) recover prepare success
12.05 00:04:57 node (192.168.18.14) recover prepare success
--------------------------------------------
12.05 00:04:57 recover prepare finish
12.05 00:04:57 recreate database test start
12.05 00:04:57 recreate database test end
12.05 00:04:57 recreate tablespace start
12.05 00:04:57 recreate tablespace end
12.05 00:04:57 recreate database test tables start
12.05 00:04:57 node (192.168.18.11) recreate database tables begin
12.05 00:05:00 node (192.168.18.11) recreate database tables success
12.05 00:05:00 recreate database test tables end
12.05 00:05:00 Recover database test start
--------------------------------------------
12.05 00:05:00 node (192.168.18.11) Recover database begin
12.05 00:05:00 node (192.168.18.13) Recover database begin
12.05 00:05:00 node (192.168.18.14) Recover database begin
12.05 00:05:13 node (192.168.18.11) Recover database success
12.05 00:05:13 node (192.168.18.13) Recover database success
12.05 00:05:13 node (192.168.18.14) Recover database success
--------------------------------------------
12.05 00:05:13 Recover database test success, please refresh it!
2).重启gbase 或重启集群或刷新表
[gbase@gbasedata1 ~]$ gcluster_services all restart
Stopping gcrecover : [ OK ]
Stopping gcluster : [ OK ]
Stopping gbase : [ OK ]
Stopping syncserver : [ OK ]
Starting gbase : [ OK ]
Starting syncserver : [ OK ]
Starting gcluster : [ OK ]
Starting gcrecover : [ OK ]
[gbase@gbasedata1 ~]$ gcluster_services gbase restart
Stopping gbase : [ OK ]
Starting gbase : [ OK ]
gbase> refresh table t1;
Query OK, 0 rows affected (Elapsed: 00:00:00.02)
表级备份恢复(命令行模式):
备份表:不需要设置readonly,但是会给备份表加锁,恢复表需要先删除表
1)备份表
[gbase@gbaseman bin]$ python gcrcman.py -d /opt/backtable -P gbase@123 -p gbase@123 -e 'backup table test.t_user level 0'
12.05 00:48:19 BackUp table test.t_user start
--------------------------------------------
12.05 00:48:19 node (192.168.18.11) backup table begin
12.05 00:48:19 node (192.168.18.13) backup table begin
12.05 00:48:19 node (192.168.18.14) backup table begin
12.05 00:48:35 node (192.168.18.11) backup table success
12.05 00:48:35 node (192.168.18.13) backup table success
12.05 00:48:35 node (192.168.18.14) backup table success
--------------------------------------------
12.05 00:48:35 BackUp table test.t_user end
·
恢复表:
1).恢复表数据
[gbase@gbaseman bin]$ python gcrcman.py -d /opt/backtable -P gbase@123 -p gbase@123 -e 'recover table test.t_user 0'
12.05 00:53:10 check Table topology start
--------------------------------------------
12.05 00:53:10 node (192.168.18.11) check table topology begin
12.05 00:53:11 node (192.168.18.11) check table topology success
--------------------------------------------
12.05 00:53:11 check table topology success
12.05 00:53:11 check Table BackUp start
--------------------------------------------
12.05 00:53:11 node (192.168.18.11) check table backup begin
12.05 00:53:11 node (192.168.18.13) check table backup begin
12.05 00:53:11 node (192.168.18.14) check table backup begin
12.05 00:53:19 node (192.168.18.11) check table backup success
12.05 00:53:19 node (192.168.18.13) check table backup success
12.05 00:53:19 node (192.168.18.14) check table backup success
--------------------------------------------
12.05 00:53:19 check table BackUp success
12.05 00:53:19 refresh table test.t_user start
12.05 00:53:19 node (192.168.18.11) recreate table begin
12.05 00:53:20 node (192.168.18.11) recreate table success
12.05 00:53:20 refresh table test.t_user end
12.05 00:53:21 Recover table test.t_user start
--------------------------------------------
12.05 00:53:21 node (192.168.18.11) Recover table begin
12.05 00:53:21 node (192.168.18.13) Recover table begin
12.05 00:53:21 node (192.168.18.14) Recover table begin
12.05 00:53:34 node (192.168.18.11) Recover table success
12.05 00:53:34 node (192.168.18.13) Recover table success
12.05 00:53:34 node (192.168.18.14) Recover table success
--------------------------------------------
12.05 00:53:34 Recover table test.t_user success, please refresh it!
2).重启gbase或集群服务或刷新表
删除备份(如果只有一个备份周期记录,则不能删除)
delete <cycle_id | last>
gcrcman>show backup
cyclepointleveltime
0002022-12-04 23:54:19
1002022-12-05 00:02:38
2002022-12-05 00:03:28
删除最后一个备份
gcrcman>delete last
12.05 01:18:09 Delete BackUp Points start
--------------------------------------------
12.05 01:18:09 node (192.168.18.11) delete begin
12.05 01:18:09 node (192.168.18.13) delete begin
12.05 01:18:09 node (192.168.18.14) delete begin
12.05 01:18:11 node (192.168.18.11) delete success
12.05 01:18:11 node (192.168.18.13) delete success
12.05 01:18:11 node (192.168.18.14) delete success
--------------------------------------------
12.05 01:18:11 Delete BackUp Points end
gcrcman>show backup
cyclepointleveltime
0002022-12-04 23:54:19
1002022-12-05 00:02:38
删除cycle_id 为0 的备份
gcrcman>delete 0
12.05 01:20:10 Delete BackUp Points start
--------------------------------------------
12.05 01:20:10 node (192.168.18.11) delete begin
12.05 01:20:10 node (192.168.18.13) delete begin
12.05 01:20:10 node (192.168.18.14) delete begin
12.05 01:20:12 node (192.168.18.11) delete success
12.05 01:20:12 node (192.168.18.13) delete success
12.05 01:20:12 node (192.168.18.14) delete success
--------------------------------------------
12.05 01:20:12 Delete BackUp Points end
gcrcman>show backup
cyclepointleveltime
1002022-12-05 00:02:38















 508
508











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









